


Co-authored by James Clampffer, Deepak Majeti.
In this second post in the Complex Data Types blog series, let’s look at some of the reasons complex types are used extensively in organized big data formats like ORC and Parquet. Be sure to read the first post in this series where we discussed the what complex data types are, and explored the various complex types in detail.
In the next post, we’ll dive into how Vertica allows you to import, directly analyze or export data in complex types.
There are several advantages to complex types:
1. Express Analyses More Naturally
Complex types simplify the expression of analysis logic thereby simplifying the data pipelines. For example, in order to list all the customers with more than 1000 website events, we will write this simple query.

Writing the same code in SQL would look something like the script below which is not very intuitive.
First, we will need to create four tables: customers, phone_numbers, web_events, and http_events.

Then the query would be something like:
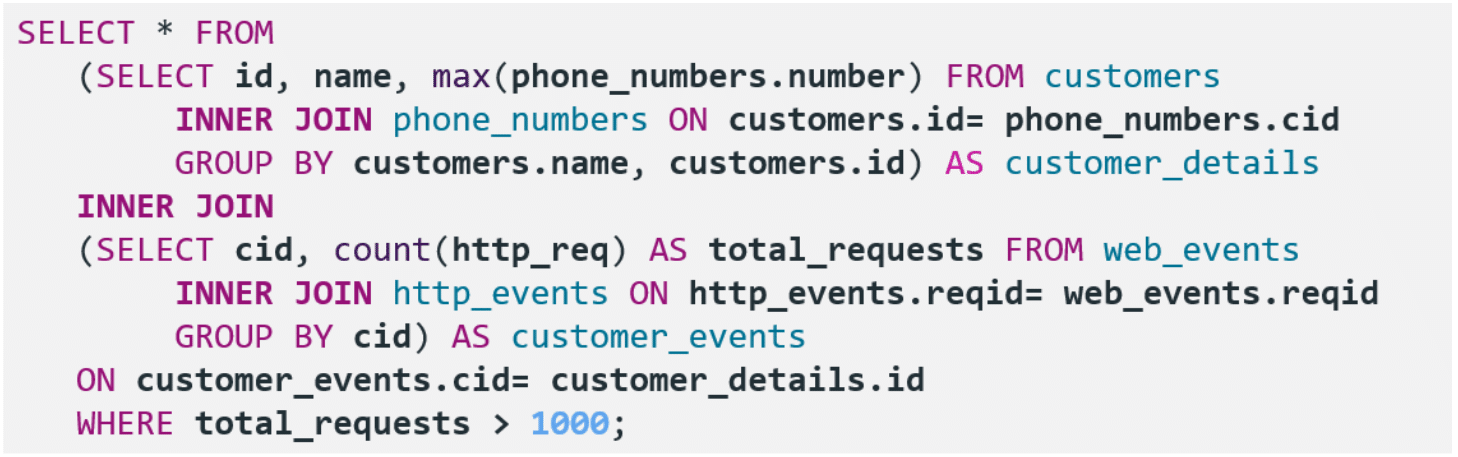
We not only have to write additional code but also needed to use multiple joins on the tables to get the desired results. For queries involving more tables, the code can get complex quickly and take the focus away from analysis. Using complex types, helps avoid this issue by having a natural flow to the analysis.
2. Alternative for Costly Joins
Complex types can be used to replace expensive joins, as shown above. This can have an impact on performance in more than one way. As a complex type value is not distributed across nodes this avoids expensive inter-node data movement. In the above example, if the query had to be run only once, it may not be much of an issue. But if the query needs to be run multiple times, especially on data that is not changing very frequently, doing a join every time you run the query would be overkill.
Complex types like Arrays are very effective at representing a set. Using these data structures allows the users to store the data in a set on a single node thereby avoiding the need to fetch data from different nodes for analysis.
Below you can see how using complex types eliminates the need for three joins.
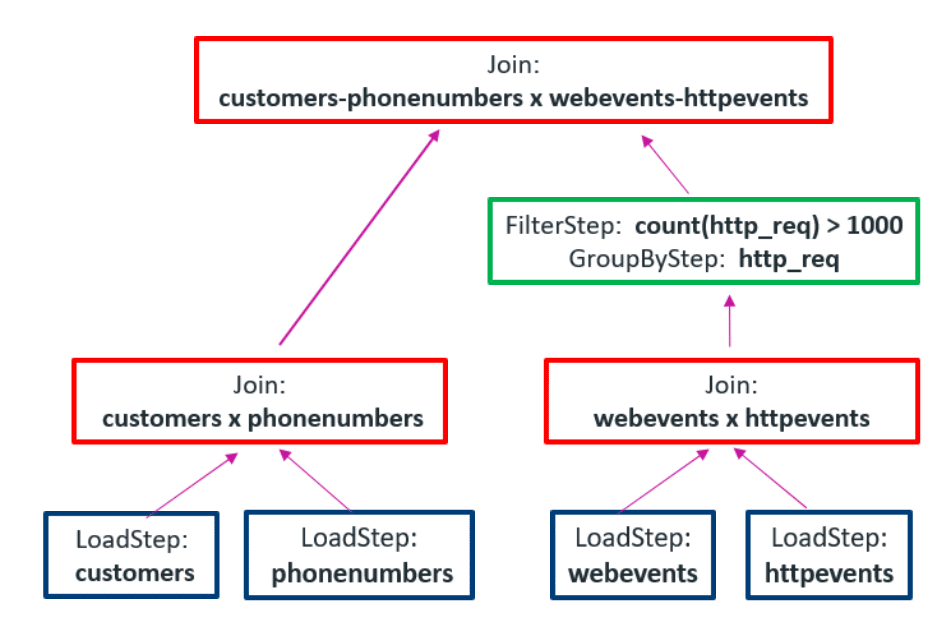
Using complex data types avoids all those costly joins:
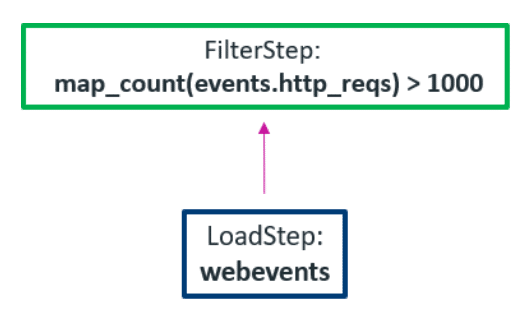
3. Allow Unstructured Data
Maps are unstructured by nature and therefore they allow unstructured data to be represented along with structured data. Maps are also a good choice for sparse data which can be better represented using maps instead of normal data types.
The ways to approximate a map in plain SQL aren’t great.
Two common approaches are:
Approach 1: Add many key1, val1 … keyN, valN columns to store key-value pairs. Null out unused columns. Limited by table width.
Approach 2: Create a table where the “map” has a unique ID that stores a single key and value in each row e.g. TABLE(map_id int not null, key<typename>, val <typename>). Something like map_count would require a groupby on map_id. You still can’t intuitively represent nested maps
Common use case: Apps that push their data to a centralized server might have optional fields that are named slightly differently over time, perhaps to indicate minor semantic changes. Then a second ETL pass can be done to normalize similar values to the same thing e.g. maybe the app started with millisecond timings and new versions use microseconds, so everything gets adjusted to use the same units. This allows the ETL to be done directly inside a SQL analytics database like Vertica.
Vertica has flex tables to help handle semi structured and unstructured data. However, complex data types are expected to provide much better performance for many use cases. The reason is that flex tables are totally unstructured, structure must be applied when querying, whereas maps have a schema associated. For the above use case, we have a map of string to string. Therefore, in this case, complex types are going to be way faster than the flex tables.

4. Supported by Popular Open Source File Formats
Apache Parquet and Apache ORC are two of the most popular columnar file formats used for analytics today. Both these formats support complex data types to varying degree. Apache Parquet supports Struct, Map, List while Apache ORC supports Struct, Map, List and Union. These two formats also differ significantly in the internal representation of complex type data. A single unified analytics warehouse like Vertica that supports these data types means you have the benefit of querying those formats directly, without first changing them to a less-efficient row and column structure. You can also import data directly from a format like Parquet into Vertica’s ROS storage format for even faster querying, or export ROS to Parquet for long-term storage.
Limitations in Other Analytical Tools
While some analytical tools like Hive, Presto and Impala currently support complex types, these tools have significant limitations for complex types. Some of the major limitations that we have observed are:
- Materialize very early at the scan step (expand complex data types to sparse row and column data)
- Do not use columnar execution
- Lack literal support
- Support limited file formats
- Lack ability to re-use complex types defined
The support for complex data types is not very mature in many tools. An additional shortcoming that’s common is that many query engines run out of memory for processing when the complex data types are expanded, causing queries to fail.
In the next post in this series, we’ll discuss what complex types are supported in Vertica, and how they are used.
Related posts:
Complex Data Types in SQL 1 – What are They?
Quick Tip: Exporting Data to Parquet
Vertica and Amazon – Better Together, for Years
Announcing Vertica Version 9.3 – Ride the Winds of Change
Vertica Version 10 Launches Today
About the Author
Waqas Dhillon
Product Manager - Machine Learning, Vertica
Waqas is the product management lead for machine learning with Vertica. In his current role, he drives the strategy and implementation of advanced analytics and machine learning features in the Vertica MPP platform. Waqas holds a bachelor’s degree in computer software engineering from NUST and a master’s degree in management from Harvard University.
Prior to his current role, Waqas has worked in multiple positions where he applied data analytics and machine learning for consumer research and revenue growth for companies in consumer packaged goods and telecommunication industries.


