


Behavioral patterns in time series are something that many analysts are keen to find in time series. A clickstream analyst wants to find the series of clicks that happened between coming to the website, browsing one or more articles in the web site, and finally filling the basket and checking out; a financial analyst wants to find the v-shapes in the curves of stock values, consisting of two or more rows where the stock value went down, followed by at least one row where the stock value went up again.
The peculiarity of this data search need consists in the words “one or more”. It means that we want a group of consecutive rows that follow a certain behavioural pattern (for example: first event “a” happens, then event “b” happens, one or more times, then event “c” can happen, and finally event “d” happens). We are looking for groups of rows – logical partitions of a time series – whose number of rows we don’t know in advance. This is something that SQL – even SQL rich in analytical functions – struggles with. The second parameter of the LAG() OVER() function can only say 1, or 2, or 3, etc. rows; it is fix. The RANGE BETWEEN or ROWS BETWEEN window frame clauses don’t help, either.
You might have seen from my previous posts in this series that I take pride in solving analytical problems also in databases with a smaller toolbox than Vertica. In the last three examples, I think I succeeded – somehow. So, I assure you that I also have tried recursive queries, with no luck so far. My current plan, which I hope to implement, time permitting, in the not-too-distant future, is to use a Stored Procedure that maintains a variable that will build the pattern string each time a series of rows promises to end up as the pattern I am searching for. To illustrate that using the clickstream case above
- A given user id reaches my website from outside. This could be the beginning of my pattern.
- The same user navigates to the page of an article I’m offering – this could be the second row of my pattern.
- The same user navigates to another article I’m offering – this still matches my pattern.
- The same user navigates to a third, fourth and fifth article of mine – this still matches my pattern.
- The same user navigates away from my pattern – without filling the shopping basket, let alone checking out – this is not the pattern I’m searching for, I need to abandon the whole pattern I have accumulated so far.
With the same pattern as above, just with the last bullet point replaced by the fact that the user clicked “Add to Basket” and then “Check Out”, I want to keep this whole pattern – to find out how long the session lasted (timestamp difference between first and last row), the average interval between clicks, etc.
What I have not yet solved is how to abandon a pattern rather than keep it, at least in an elegant and effective manner. From what you have read so far, it looks like it might become a several-hundred-line Stored Procedure.
The Vertica Way of Detecting Behavioral Patterns
For this type of requirement, Vertica has the MATCH() clause ready. Vertica was first published around 2006, and it was already part of the toolbox then. The only other DBMS I know to also support something like this is Oracle, since their version 12c, which was published in 2014. It could be a matter of personal tastes, but I find the Oracle version less intuitive than the Vertica version.
The structure of a MATCH clause goes like this:
- The opening MATCH keyword and an open parenthesis
- a PARTITION BY … ORDER BY … clause like in any OLAP function
- a DEFINE clause, which consists of the DEFINE keyword, followed by several, comma separated, event definitions. These event definitions consist of a programmer’s word (i.e a SQL identifier) of your choice, followed by the AS keyword and any Boolean expression
- a PATTERN clause, consisting of the PATTERN keyword, a programmer’s word of your choice, the AS keyword, and then the identifiers defined in the DEFINE clause above, in the order in which they should appear, enriched as needed by the asterisk – meaning zero, one or more times, the plus sign – meaning one or more times. And if this reminds you of regular expression syntax, that’s exactly how it works.
- a closing parenthesis
If you can memorize the five points above, you don’t have to go back to the manual to code a MATCH clause. I find the simplicity of the syntax, to express an admittedly complex query requirement, impressive.
The MATCH() clause in action.
Input is this sensor data cutout from an internal-combustion engine. During the prototype phase of a new car, automotive engineers want to analyse the incoming airmass – in mass per unit of time – during the failed start attempts of the engine. The data of one or more test drives, maybe of one or more cars, are in the dataset, and a test drive can last several days, and we get several hundred measurements per second and car. We have pruned out all sensor data columns except airmass and revolutions per minute of the engine’s crankshaft – that’s rpm. And we want to filter out just the partitions that correspond to a failed start attempt. So, a cut-out of the input data we are working with looks like this:
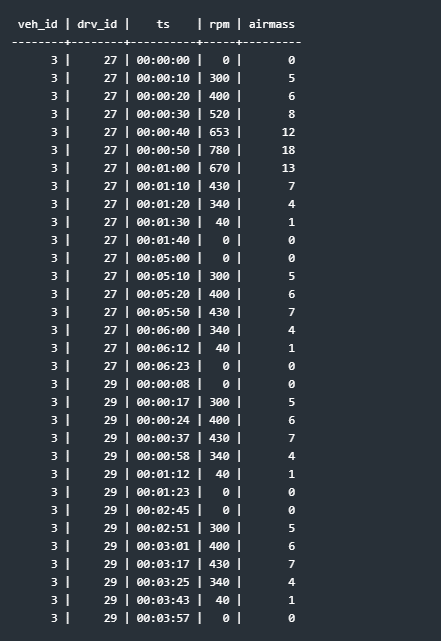
Of course, ts is a timestamp in reality, including day, month and year. Note that in this partial view, we have the same vehicle all the time, and two test drives that it was taken to. Of course it is much bigger and contains millions of rows that are completely useless for our purpose in reality.
How do we recognise a failed start attempt?
- At the start, the engine starts to turn: in one row, rpm is at 0, in the next above 0.
- The engine turns for a while – one or more times, but never at the speed sufficient for the engine to fire up and turn by itself with its own combustion: the tick-over, or idle, rpm value, which, in our case, is 650rpm.
- The engine stops turning: in one row, rpm is above zero, in the next, it is at 0.
Of course, I purposefully put candidate patterns in the above cut-out – they don’t occur so often in a day of a test drive. You’ll notice groups of rows where the engine turns, framed by rows where the engine does not turn. Note the group in test drive 27 that starts at 00:00:00 and ends at 00:01:40. It looks like all the other groups, but has two rows above 650 rpm, and therefore needs discarding in its entirety. Eyeballing 32 rows is a doable task – especially if it consists only of candidate patterns. In reality we are looking for a bunch of needles in a haystack.
What do we do with it now? We run this commented query:

And this is the result of the whole exercise:
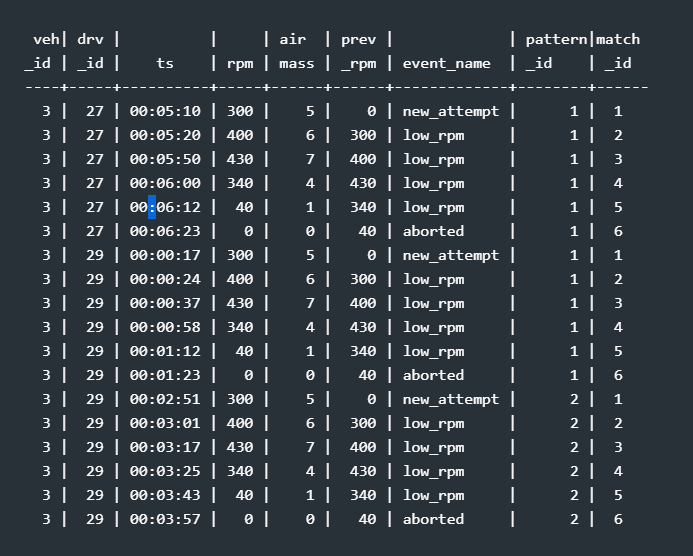
Note that we found one pattern for test drive 27 – the first candidate for that drive had two rows above 650 rpm and was discarded – and two patterns in the test drive 29. The event_name is a handy part of the report to illustrate why a pattern I was searching for was matched.
About the Author
Marco Gessner
Field Chief Technologist
A Data Warehousing and BI Professional in virtually all disciplines of the scene:
Data Quality; (Master) Data Management; ETL - manually and with tools like Informatica and DataStage and Ab->Initio; Conceptual and physical design; Data Warehouse Architecture; Data Warehouse / BI Project Management; BI deployment with tools like Cognos or Oracle BI or MicroStrategy.
My Objectives? Having fun being supported by peers and supporting peers in a professional environment that you either run away from screaming or you get hooked to for life. The more difficult and challenging the job, the more thrill and fun. I fell in love with Vertica some 12 years ago, when HP bought Vertica, in 2010 / 2011, and I have been working with and for Vertica ever since.


