


You might have come across this. You would have obtained a huge set of time stamped log data or sensor data that you would like to understand. Millions of rows are nothing for human consumption – and far too much for plotting on a monitor that just has a few thousand pixels across – why fetch millions of rows across a busy network, when you can just plot a few thousand of them?
What could help you is a minimum/average/maximum value for a time slice. All DBMS-s I know can truncate a timestamp value to the second, minute, hour or day, to “snap” a timestamp to the previous or next full unit of time. And you could group by that and get min/max/avg.
What if what you really needed was one value 8 times a day – that is, every 3 hours? Or at a granularity that returns just exactly 1680 rows, as that is the number of pixels across supported by your display – out of the millions of data points of the two days’ worth of data, several hundred data points per second, that someone presented you with? Or even adapting to the zoom level of the application displaying a graph?
In those cases, what you really need is the possibility of snapping a timestamp to the previous or next multiple of seconds, minutes, hours or days.
We can achieve this custom-truncation of a timestamp in several steps:
- Convert the timestamp to the number of seconds elapsed since a defined anchor timestamp
- Integer-divide that number of seconds, by the number of seconds that the wished interval of multiple of seconds, minutes, hours or days, consists of
- Multiply it back by the same number that you just integer-divided it by.
- Add the number of seconds obtained by that integer-division -> integer multiplication, to the same defined anchor timestamp.
Quite a lot of DBMS-s, in addition to Vertica, have a function call that returns the Unix epoch. That is the number of seconds elapsed since 1st January, 1970. It’s the EXTRACT() function with the EPOCH keyword as the first parameter:
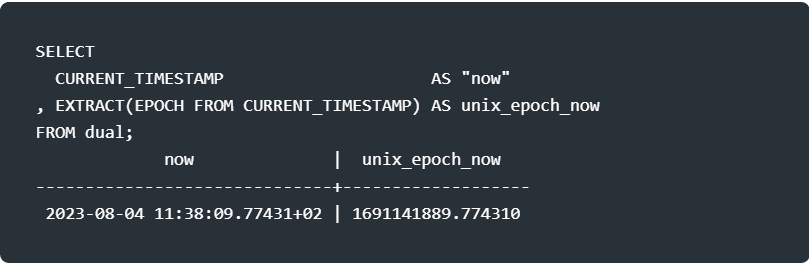
As they should, they also have a possibility to reverse that operation:
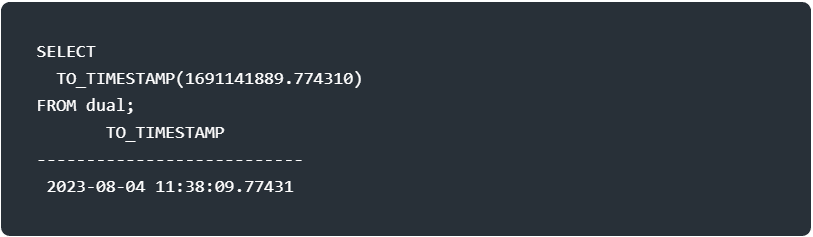
TO_TIMESTAMP could also be TO_DATE, for example in Oracle, or a differently named function.
In Oracle, an integer division is achieved by wrapping the division expression into a FLOOR() function, and casting that to NUMBER(18,0), for example.
In SQL Server, you will have to define the anchor timestamp, say ‘1970-01-01 00:00:00’, yourself, and use DATEDIFF() to calculate the number of seconds elapsed, and DATEADD() to add the custom-truncated seconds back. And if both operands of a division are integers in SQL Server, the result is an integer division with type integer.
Here below is a query and its result, to snap a set of timestamps to the nearest preceding multiple of 3 minutes using the de-facto standard functions mentioned above. In Vertica, we have a specific integer division operator – the double slash. But I tried the below in PostgreSQL, where the double slash is not supported, but a division between two integer operands always is an integer division, returning an integer.
Just convert the single slash for the division to a double one, and, optionally, remove the cast-to-integer operation, if you want to try that in Vertica.
Note the figure of 180 that I integer-divide by and re-multiply by: That’s your three minute time slice translated into seconds. “tslepoch” is just the intermediate result for whoever might be interested.
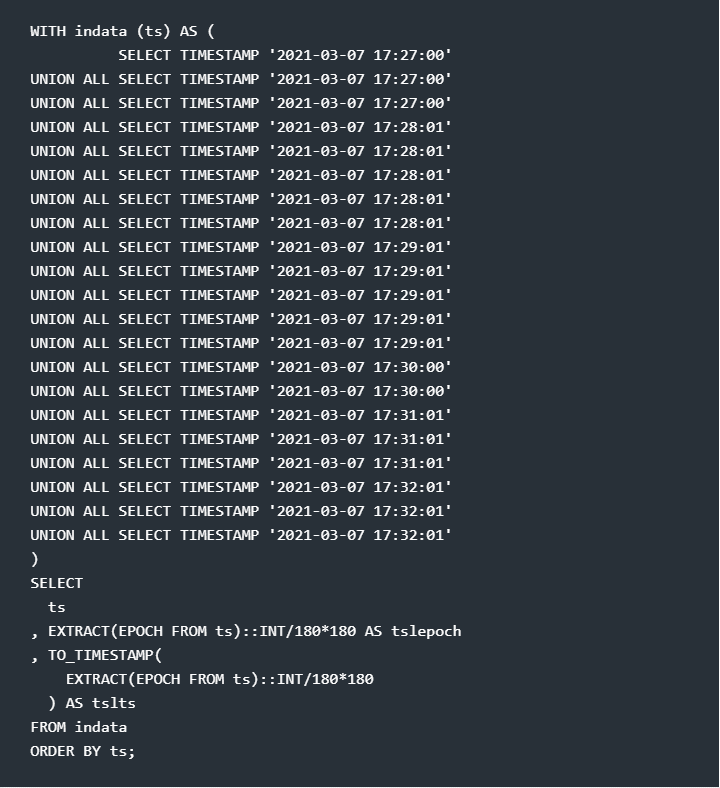
So now I have established it can be done in any “decent” DBMS. However, reading the SQL query is not exactly intuitive. I would have to “decorate” it with quite some comments for an unsuspecting reader of this query to grasp what on Earth I am trying to accomplish here – they might not have read this article. And we can not expect a SQL novice to come up with this solution on their own in useful time.
How It’s Done in Vertica
Vertica has this wonderful function called TIME_SLICE(). It uses three or four parameters:
- the timestamp we want to “snap” to, to custom-truncate to
- the unit of the time-slice
- (optional) the measure of the time slice as a string:, ‘hour‘,’minute‘,’second‘ (default),’millisecond‘,’microsecond‘
- (optional) ‘start ‘ or ‘end ‘ , to choose if you want to display the timestamp of the beginning or the end of the time-slice
The query will look like this here below – and return the same end result without bothering with an intermediate result. I repeat the WITH clause used above, just so you can copy-paste the whole query in one go without bothering to have some test data ready before.
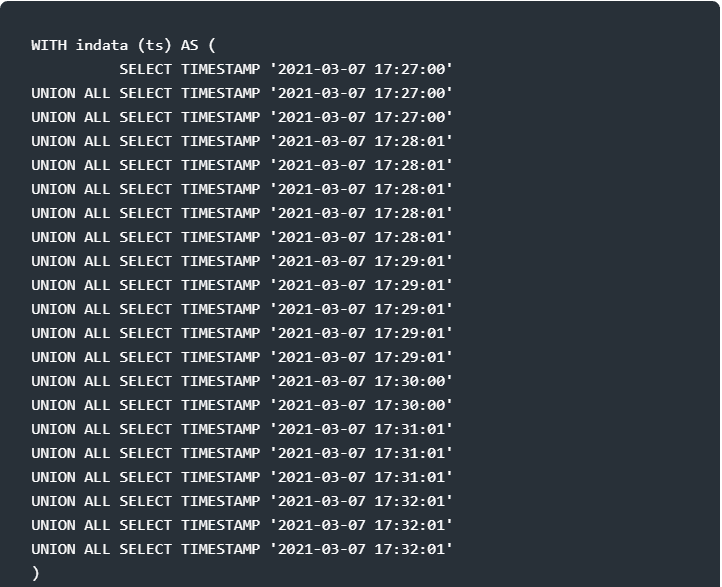
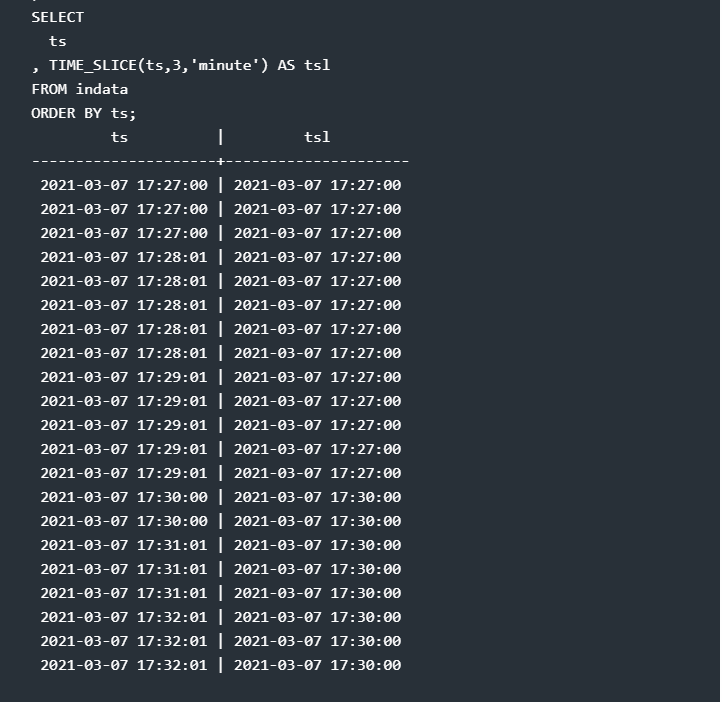
Seen? Not only do I have to code much less (let alone spend time to think to come up with the integer-division and re-multiplication idea using the Unix epoch embedded in a to-and-fro conversion), but the name of the function is so well chosen that you can understand from the SQL code what the query is trying to achieve.
I mean, one of the perks of SQL is that it is – and was conceived to be – uncannily similar to natural English language. And we should always code our queries so that any future reader can understand it. Code is much more often read than written. And well named objects – that includes the tables and columns we design, but also the functions we use (and possibly add). TIME_SLICE() is elegant in both its functionality and its name.
About the Author
Marco Gessner
Field Chief Technologist
A Data Warehousing and BI Professional in virtually all disciplines of the scene:
Data Quality; (Master) Data Management; ETL - manually and with tools like Informatica and DataStage and Ab->Initio; Conceptual and physical design; Data Warehouse Architecture; Data Warehouse / BI Project Management; BI deployment with tools like Cognos or Oracle BI or MicroStrategy.
My Objectives? Having fun being supported by peers and supporting peers in a professional environment that you either run away from screaming or you get hooked to for life. The more difficult and challenging the job, the more thrill and fun. I fell in love with Vertica some 12 years ago, when HP bought Vertica, in 2010 / 2011, and I have been working with and for Vertica ever since.


