


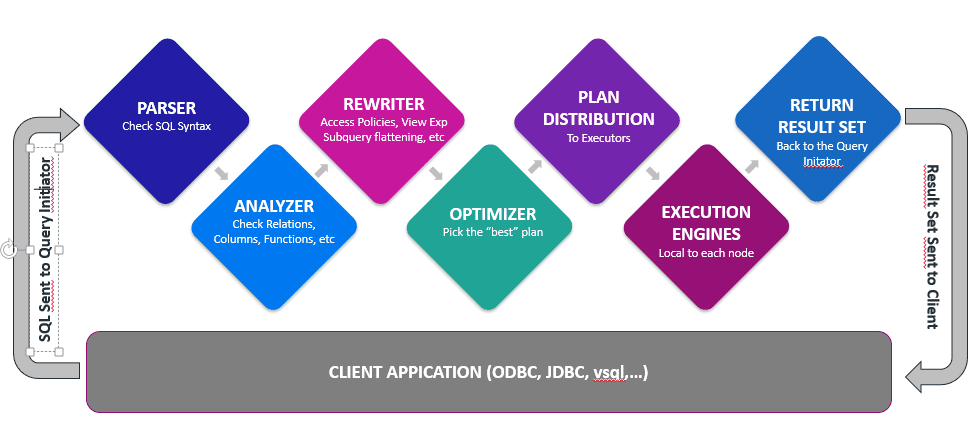
Vertica Optimizer
Queries can be executed in many ways. The Vertica optimizer quickly finds the best way to execute a query. Vertica uses a cost-based optimizer. The cost model represents the costs as a function of the amount of data flowing through the plan. Each query plan alternative is associated with a cost that estimates the amount of resources Vertica needs to execute the query, including CPU, disk, memory and network. The query optimizer selects the plan with the lower costs, which is also usually the one that is faster. The query optimizer relies on statistics and heuristics to determine the execution plan costs, including the following: • Number of rows in the table • Cardinality of each column • Min/max values of each column • Values distribution histogram for each column • Column footprint • The access path with the fewest expected I/O operations and lowest CPU, memory, and network usage • Join types based on different projection choice • Join order • Predicates selectivity • Data redistribution algorithms across nodes in the cluster The following graphic shows what you should do:
Do: Check the SQL
Start by looking at the SQL itself. Try to reduce complications as much as possible. For example, this SQL with 5 nested function calls and two string concatenations can be reduced:to_char(YEAR_ISO(period_key)) ||'-W’|| lpad(to_char(WEEK_ISO(period_key)),2,'0')
Replace it with 1 function call and no string concatenations:
to_char(period_key, 'IYYY-"W"IW')
Avoid passing UDx arguments. Instead, use parameters. Keep in mind that inequality predicates and OR operators are slow.
Do: EXPLAIN Your Query
The EXPLAIN plan describes how the optimizer would like to execute a query, before the query is actually executed. You should check the following: • GLOBAL RESEGMENTATION • BROADCAST • JOIN ORDER • JOIN TYPE • GBY TYPE • COSTs and ROWs • Projections being used • Columns being materializedDo: Update Statistics
You should update your statistics: • After a consistent table load or update • After a table is altered • When a projection is refreshed You can also run ANALYZE_STATISTICS immediately before running your benchmark.Do: Run Your Query Using vsql
Use vsql to run your perf test:$ vsql -AXtnqi -f query.sql -o /dev/null
Axtnqi means:
• Use unaligned output mode (A)
• Do not run commands in the vsql initialization file (X)
• Disable printing column names (tuples only) (t)
• Disable command line editing (n)
• Work quietly (q)
• Print timing information (i)
Do: Check QUERY_EVENTS
QUERY_EVENTS contains very useful information generated during either the OPTIMIZATION or EXECUTION of event categories.Do: DDLs and Projections
DDLs and projection definitions are some of the most important optimization techniques. DDLs are used to profile your data and ensure it uses the right data types. Consider replacing fat joining or grouping columns with slick integers. Also consider flattening tables to avoid or reduce joins. Take advantage of LAPs when possible. Avoid creating too many projections, because loads will be slower. Use the SEGMENTED BY clause to avoid resegmentation with either joins or GROUP BY. Each node should be able to group or join its own data without looking into other nodes. Use ORDER BY to influence the GROUP BY and join type: • Joins: projections are sorted on the joining column(s). You get a MERGE JOIN rather than a HASH JOIN. MERGE joins never spill to disk. • GROUP BY: if grouping columns are a subset of the ones in the SORT BY clause, you get a PIPELINED GROUP BY rather than a HASH GROUP BY. Pipelined GROUP BYs never spill to disk.Do: Profile Your Query
The query profile provides very detailed information about each single operator used during the execution. Data profiling is available in the V_MONITOR.EXECUTION_ENGINE_PROFILE if you explicitly profiled the query. Even a simple query can easily produce thousands of EXECUTION_ENGINE_PROFILEs. The EXECUTION_ENGINE_PROFILE contains the following information: • Node name • User information • Session, transaction, and statement IDs • Plan information • Operator name • Counter name • Counter value Counters change from one operator to another.Do: Update System Config (If needed)
You might want to change some system parameters to improve performance. Do this with caution.Don’t: Underestimate Data Extraction
If your query returns a large result set, moving data to the client can take a lot of time. Redirecting client output to /dev/null still implies moving data to the client. Consider instead storing the result set in a LOCAL TEMPORARY TABLE.Useful Queries
The following query checks the data distribution for a given table. This is often useful to look into a plan when no statistics are available:select
projection_name, node_name, sum(row_count) as row_count, sum(used_bytes) as used_bytes, sum(wos_row_count) as wos_row_count, sum(wos_used_bytes) as wos_used_bytes, sum(ros_row_count) as ros_row_count, sum(ros_used_bytes) as ros_used_bytes, sum(ros_count) as ros_count
from
projection_storage
where
anchor_table_schema = :schema and
anchor_table_name = :table
group by 1, 2
order by 1, 2;
The following query shows the non-default configuration parameters:
SELECT
parameter_name, current_value, default_value, description
FROM v_monitor.configuration_parameters
WHERE current_value <> default_value
ORDER BY parameter_name;
The following query checks encoding and compression for a given table:
SELECT cs.projection_name, cs.column_name, sum(cs.row_count) as row_count, sum(cs.used_bytes) as used_bytes, max(pc.encoding_type) as encoding_type, max(cs.encodings) as encodings, max(cs.compressions) as compressions
FROM
column_storage cs
inner join projection_columns pc
on cs.column_id = pc.column_id
WHERE
anchor_table_schema = :schema and
anchor_table_name = :table
GROUP BY 1, 2
ORDER BY 1, 2;
The following will retrieve the EXPLAIN PLAN for a given query:
SELECT
path_line
FROM v_internal.dc_explain_plans
WHERE
transaction_id=:trxid and
statement_id=:stmtid
ORDER BY
path_id, path_line_index;
The following shows the resource acquisition for a given query:
SELECT
a.node_name, a.queue_entry_timestamp, a.acquisition_timestamp,
( a.acquisition_timestamp - a.queue_entry_timestamp ) AS queue_wait_time, a.pool_name, a.memory_inuse_kb as mem_kb, (b.reserved_extra_memory_b/1000)::integer as emem_kb, (a.memory_inuse_kb-b.reserved_extra_memory_b/1000)::integer AS rmem_kb, a.open_file_handle_count as fhc, a.thread_count as threads
FROM
v_monitor.resource_acquisitions a
inner join query_profiles b
on a.transaction_id = b.transaction_id
WHERE
a.transaction_id=:trxid and
a.statement_id=:stmtid
ORDER BY 1, 2;
The following gives query events for a given query:
SELECT event_timestamp, node_name, event_category, event_type, event_description, operator_name, path_id, event_details, suggested_action
FROM v_monitor.query_events
WHERE
transaction_id=:trxid and
statement_id=:stmtid
ORDER BY 1;
The following query shows transaction locks:
SELECT node_name,(time - start_time) as lock_wait, object_name, scope, result,description
FROM v_internal.dc_lock_attempts
WHERE
transaction_id = :trxid
;
The following query shows threads by profile operator:
SELECT node_name, path_id, operator_name, activity_id::varchar || ',' || baseplan_id::varchar || ',' || localplan_id::varchar as abl_id, count(distinct(operator_id)) as '#Threads'
FROM v_monitor.execution_engine_profiles
WHERE
transaction_id=:trxid and
statement_id=:stmtid
GROUP BY 1,2,3,4
ORDER BY 1,2,3,4;
The following query shows how you can retrieve the query execution report:
SELECT node_name , operator_name, path_id, round(sum(case counter_name when 'execution time (us)' then counter_value else null end)/1000,3.0) as exec_time_ms,
sum(case counter_name when 'estimated rows produced' then counter_value else null end ) as est_rows,
sum ( case counter_name when 'rows processed' then counter_value else null end ) as proc_rows,
sum ( case counter_name when 'rows produced' then counter_value else null end ) as prod_rows,
sum ( case counter_name when 'rle rows produced' then counter_value else null end ) as rle_pr_rows,
sum ( case counter_name when 'consumer stall (us)' then counter_value else null end ) as cstall_us,
sum ( case counter_name when 'producer stall (us)' then counter_value else null end ) as pstall_us,
round(sum(case counter_name when 'memory reserved (bytes)' then
counter_value else null end)/1000000,1.0) as mem_res_mb,
round(sum(case counter_name when 'memory allocated (bytes)' then
counter_value else null end )/1000000,1.0) as mem_all_mb
FROM v_monitor.execution_engine_profiles
WHERE transaction_id = :trxid and statement_id = :stmtid and counter_value/1000000 > 0
GROUP BY 1, 2, 3
ORDER BY
case when sum(case counter_name when 'execution time (us)' then counter_value else null end) is null then 1 else 0 end asc , 5 desc ;
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


