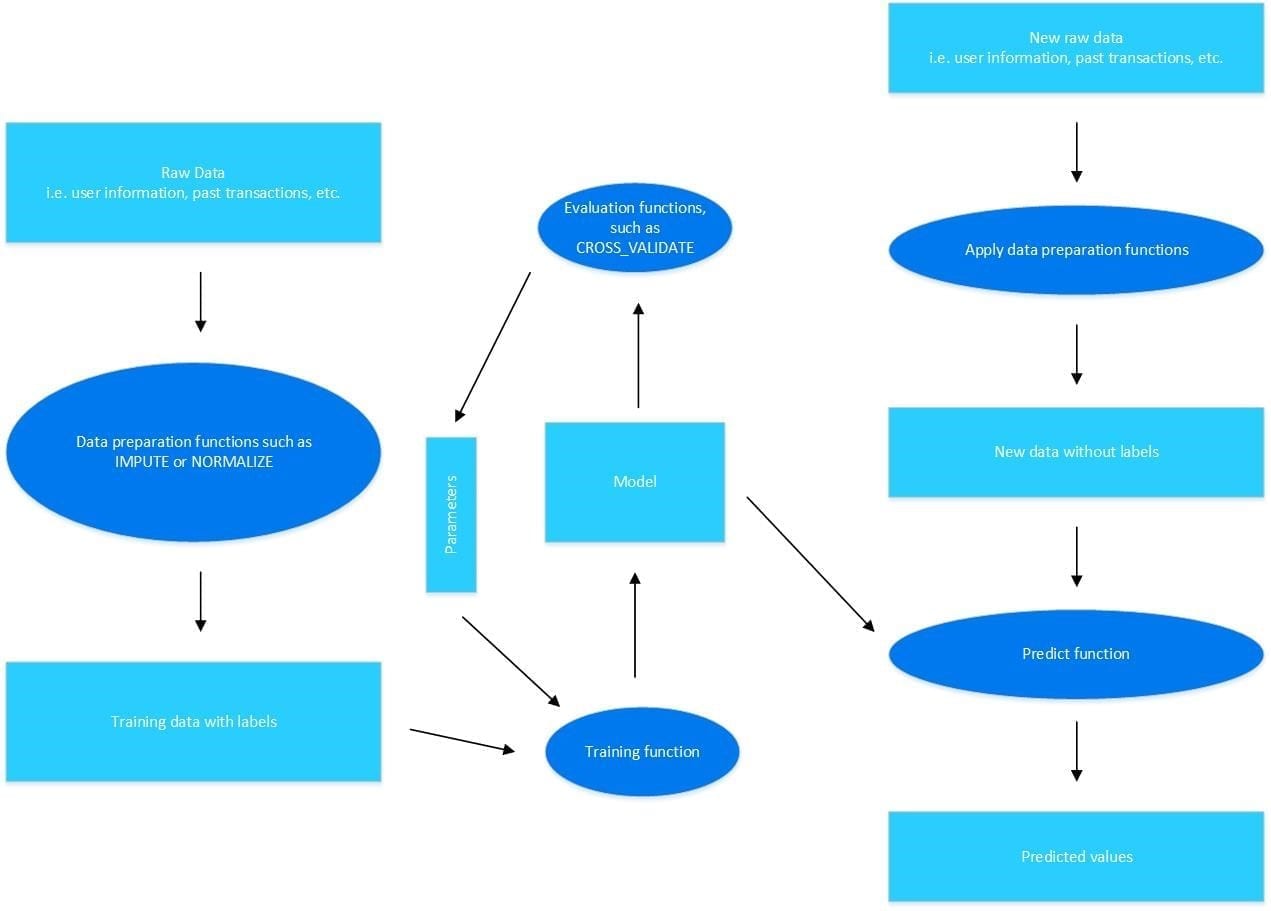
 All machine learning is based on raw data, like the user information and preferences Netflix uses to recommend what show you should watch next. Sometimes that data is missing values or needs to be cleaned before it is ready for use. This preprocessing step ensures that the data is in a form that is usable.
Models are the representation learned from the data, while the algorithms are the process for learning the data. Models are created by a process known as training. The goal of training is to create an accurate model that can answer your question. To train the model, the data set is split into two parts. The first part, known as the training data set is used to train the model. The second part, known as the testing data, is used to evaluate the model’s performance.
Machine learning algorithms can be divided into two main categories: supervised and unsupervised learning. The supervised algorithms work on the assumption that given some input variables, also known as predictors, the algorithms try to predict an output variable. This output variable is also called a response variable. Often, you have more than one input variable that is used to predict the response variable. For example, if you’re trying to determine the cost of a house, you look at multiple input variables – the size of the house, the location, parking, and so on. The unsupervised algorithms try to find clusters among the training data based on the similarity of the data points. These algorithms are often useful when the data points have no response variable. These data points are known as unlabeled data.
In Vertica, the machine learning algorithms are broken into three major categories:
• Classification: These supervised algorithms build models that consolidate information about the relationship between data points and their distinct classes. A predict function is provided for each algorithm in this category that applies the trained model on any new data point to predict the class of its corresponding response. Common algorithms for classification include SVM and Random Forest.
• Regression: These supervised algorithms operate similarly to the classification algorithms. However, regression algorithms learn the relation of data points with continuous numerical values instead of classes. A predict function is provided for each algorithm in this category that applies the trained model on any data point to predict the value of its corresponding response. Linear regression is a common regression algorithm.
• Clustering: These unsupervised algorithms differ a bit from the previous two. Clustering algorithms build models that consolidate information for grouping data points based on their similarities. An apply function is provided for each algorithm in this category that applies the trained model on any new data point to associate it with an identified group. K-means is the most popular clustering algorithm.
Finally, let’s take a closer look at some of the algorithms in Vertica to get a better understanding of how they work.
The Bayes Theorem is the theory behind the Naïve Bayes algorithm. This theorem uses the basic idea that it lets you predict the probability of a hypothesis based on data points. For example, you could use the theorem to predict the probability of someone having cancer based on their age.
Decision trees are top-down trees that split a data set based on a set of conditions on different attributes of data points. The Random Forest algorithm internally uses a set of decision trees. Decision trees decide which attributes are best to split on, hoping for a minimum number of splits. Because this process can sometimes get unwieldy, decision trees often use tree pruning to remove unnecessary structures from the tree.
Support vector machines (SVMs) are used to classify both linear and non-linear data. They work by creating boundaries between classes.
It’s also important to understand that sometimes the models you build don’t always perform as expected. When you talk about how well a model learns and generalizes to new data, there are two important terms to understand: overfitting and underfitting.
Overfitting happens when a model learns the detail of the training data so well that it negatively impacts the performance of the model on the testing data. The model learns the random fluctuations in the training data. However, the testing data won’t exhibit these same random fluctuations, and therefore the model won’t apply well. On the other hand, underfitting refers to a model that cannot generalize to new data and cannot model the training data. Underfitting is often easier to detect than overfitting.
One way to detect overfitting is cross validation. When trying to limit overfitting, you can use a few different techniques: increase training data size, reduce the number of predictors, or apply regularization.
We hope this clarifies some of the basics of understanding machine learning!
All machine learning is based on raw data, like the user information and preferences Netflix uses to recommend what show you should watch next. Sometimes that data is missing values or needs to be cleaned before it is ready for use. This preprocessing step ensures that the data is in a form that is usable.
Models are the representation learned from the data, while the algorithms are the process for learning the data. Models are created by a process known as training. The goal of training is to create an accurate model that can answer your question. To train the model, the data set is split into two parts. The first part, known as the training data set is used to train the model. The second part, known as the testing data, is used to evaluate the model’s performance.
Machine learning algorithms can be divided into two main categories: supervised and unsupervised learning. The supervised algorithms work on the assumption that given some input variables, also known as predictors, the algorithms try to predict an output variable. This output variable is also called a response variable. Often, you have more than one input variable that is used to predict the response variable. For example, if you’re trying to determine the cost of a house, you look at multiple input variables – the size of the house, the location, parking, and so on. The unsupervised algorithms try to find clusters among the training data based on the similarity of the data points. These algorithms are often useful when the data points have no response variable. These data points are known as unlabeled data.
In Vertica, the machine learning algorithms are broken into three major categories:
• Classification: These supervised algorithms build models that consolidate information about the relationship between data points and their distinct classes. A predict function is provided for each algorithm in this category that applies the trained model on any new data point to predict the class of its corresponding response. Common algorithms for classification include SVM and Random Forest.
• Regression: These supervised algorithms operate similarly to the classification algorithms. However, regression algorithms learn the relation of data points with continuous numerical values instead of classes. A predict function is provided for each algorithm in this category that applies the trained model on any data point to predict the value of its corresponding response. Linear regression is a common regression algorithm.
• Clustering: These unsupervised algorithms differ a bit from the previous two. Clustering algorithms build models that consolidate information for grouping data points based on their similarities. An apply function is provided for each algorithm in this category that applies the trained model on any new data point to associate it with an identified group. K-means is the most popular clustering algorithm.
Finally, let’s take a closer look at some of the algorithms in Vertica to get a better understanding of how they work.
The Bayes Theorem is the theory behind the Naïve Bayes algorithm. This theorem uses the basic idea that it lets you predict the probability of a hypothesis based on data points. For example, you could use the theorem to predict the probability of someone having cancer based on their age.
Decision trees are top-down trees that split a data set based on a set of conditions on different attributes of data points. The Random Forest algorithm internally uses a set of decision trees. Decision trees decide which attributes are best to split on, hoping for a minimum number of splits. Because this process can sometimes get unwieldy, decision trees often use tree pruning to remove unnecessary structures from the tree.
Support vector machines (SVMs) are used to classify both linear and non-linear data. They work by creating boundaries between classes.
It’s also important to understand that sometimes the models you build don’t always perform as expected. When you talk about how well a model learns and generalizes to new data, there are two important terms to understand: overfitting and underfitting.
Overfitting happens when a model learns the detail of the training data so well that it negatively impacts the performance of the model on the testing data. The model learns the random fluctuations in the training data. However, the testing data won’t exhibit these same random fluctuations, and therefore the model won’t apply well. On the other hand, underfitting refers to a model that cannot generalize to new data and cannot model the training data. Underfitting is often easier to detect than overfitting.
One way to detect overfitting is cross validation. When trying to limit overfitting, you can use a few different techniques: increase training data size, reduce the number of predictors, or apply regularization.
We hope this clarifies some of the basics of understanding machine learning!
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!