


If you store large data sets in Hadoop, you undoubtedly face many challenges in managing and analyzing that data. Did you know that Vertica for SQL on Hadoop can help ? Check out the scenario that follows to learn how.
The Scenario
Data is your strategic asset your organization knows this! You’ve deployed a state-of-the-art big data platform to enable your organization to collect, store, transform, and analyze the enterprise data to gain competitive advantage against your competitors and you are winning! Briefly, your state-of-the-art big data platform looks like this:
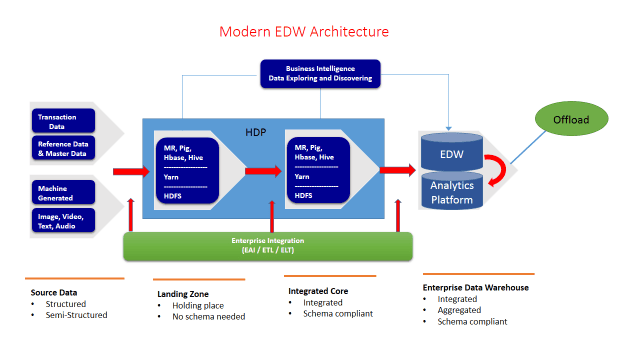
Your organization has taken advantage of a Hadoop Distributed File System (HDFS) to collect and store your data economically with scalability. You’ve offloaded your complex ETL jobs to Hadoop. As a result, higher value data is discovered, transformed, and moved to your enterprise Data Warehouse (EDW) / Analytics platform to support operational reporting, business intelligence, and ad hoc data analysis.
The Challenges
Your organization nonetheless faces significant challenges. With your massive data set sitting in the data lake, you cant extract business insight out of it quickly. Specifically, you have lots of tables in your Hive database, some of which are storing billions of rows and countless numbers of columns, and you’re using Hive to support your user community to access the data lake.
Your user community struggles with these typical problems with on daily basis:
- Users can’t run all the queries they want.
- Users are unable to extract business insights in time; queries takes too long and are hard to scale.
- Users are unable to perform advanced analytics to analyze data.
In summary, your organization needs a better SQL on Hadoop engine that provides fast and complete access to the massive amount of data stored in the data lake. The engine must also meet the following criteria:
- Fully ANSI SQL compliant:
- A SQL on Hadoop engine must have the ability to complete TPC-DS queries effectively without significant rewriting efforts. In addition, enriched in-database analytics are critical to perform more advanced analytics quickly.
- Business benefits: Support for large SQL user bases, leverage for a large ecosystem of SQL-based data analysis and visualization tools, increase in productivity.
- Higher performance with linear scalability:
- Full support of interactive query speed at the sub-second level is necessary for today’s business user community; at the same time, your solution must scale easily to a multi-PB dataset to support ever-increasing data volume.
- Business benefits: The business can scale and dramatically reduce complexity while accelerating time to insights.
- Enterprise readiness:
- The platform can be completely secured.
- The platform is proven to work with real world petabyte scale deployment.
- The platform comes with world-class enterprise support and services.
Vertica Can Help
Luckily, Vertica for SQL on Hadoop can help your organization address the challenges you’re facing. Well show you this using the standard TPC-DS benchmark, which models the query workload in real-world enterprise data warehouse and analytics platforms. We’ll pick one large fact table: store_sales, which joins to multiple dimension tables including date_dim, store, item, customer, customer_address, and others. Based on the fact table selected, we’ll use query 19 from the TPC-DS specification, which selects the top revenue generating products, and sorts by zip code, year, month, and manager. The query involves a large number of joins including multiple fact/dimensional tables, and is a typical pattern that commonly occurs in star schemas, which are widely adopted by many organizations.
Using the Vertica HCatalog Connector to Query Hive Tables Directly
The Vertica HCatalog Connector lets you transparently access data that is available through WebHCat and format the data from Hadoop into tabular data. The data within this
HCatalog schema appears as if it is native to Vertica, and you can perform operations such as joins between Vertica native tables and HCatalog tables.
You may have noticed the simplicity of querying Hive data via the Vertica HCatalog connector, but performance and concurrency may not be as good as you’d like. Vertica 7.1.2 now offers a better way to query the same data with the new ORC Reader.
Using the ORC File Reader
The ORCFile format was introduced in Hive 0.11, and it has been improving steadily over time. It has many advantages, such as:
- Block level block-mode compression based on data type, including run-length encoding for integer columns, dictionary encoding for string columns, and so forth. This kind of encoding technique provides excellent compression.
- Light-weight indexes stored within the file. It skips row groups that don’t pass predicate filtering and has the ability to seek to a given row. It comes with basic statistics min, max, sum, and count on columns. This enables query predicate pushdown and row-skipping within a strip for rapid reads.
- A larger block size of 256 MB by default. This allows for optimization of large sequential reads on HDFS, yielding more throughput and fewer files reduction on the Hadoop name nodes. It also allows for concurrent reads of the same file using separate RecordReaders.
Vertica 7.1.2 provides the ORCFile reader to enable your organization to take advantage of Hadoop Optimized Row Columnar (ORC) files, which have excellent compression and provide better query performance. You can create new ORC files or easily convert existing Hive tables to the ORC file format as follows:
- Create an external table using the TPC-DS store_sales table in Hive as an example:
=> CREATE EXTERNAL TABLE store_sales (
...) STORED AS ORC
Location '/user/dbadmin/tpc-ds/store_sales/'
Tblproperties(orc.compress=ZLIB);
You can configure a number of table properties to tune how ORC works, such as Orc.create.index, or orc.row.index.stidor.
- Create ORC data files for the store_sales table:
=>INSERT INTO table store_sales SELECT * FROM store_sales_etxt;
Notice that the original data files of table store_sales in the text delimited format are roughly 3 times larger than the same ones in ORC format. So, by using ORC files, you have achieved significant compression ratio and saved lots of storage. Other tables such as customer_demographics have even better compression. The ORC reader supports both ZLib and Snappy compression.
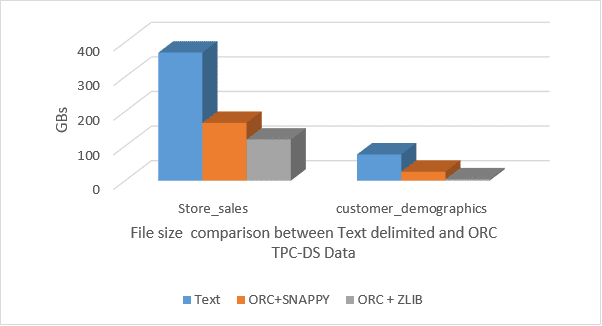
Now you can run the same query in Hive and check the result set along with the performance. As we expect, it performs better than old Hive tables in the text format, but it is still slow, given the nature of Hive architecture, and it does not meet your expectations! This is where Vertica for SQL on Hadoop comes in.
- To analyze the same data sets using Vertica for SQL on Hadoop, either:
Create an external table in Vertica as follows:
=>CREATE EXTERNAL TABLE vertica_store_sales (
...) STORED AS ORC
AS COPY FROM 'webhdfs://namenode:50070/user/dbadmin/tpc-ds/store_sales/'
ON ANY NODE ORC;
Or
Bring data into Vertica using Vertica COPY command:
=> COPY vertica_store_sales FROM 'webhdfs://namenode:50070/user/dbadmin/tpc-ds/store_sales/'
- Finally, execute the same query using Vertica for SQL on Hadoop:
=>SELECT i_brand_id brand_id, i_brand brand, i_manufact_id, i_manufact,With successful execution of the query, you should see significant performance improvement as expected.
SUM(ss_ext_sales_price) ext_price
FROM vertica_date_dim, vertica_store_sales, vertica_item,
vertica_customer, vertica_customer_address, vertica_store
WHERE d_date_sk = ss_sold_date_sk
AND ss_item_sk = i_item_sk
AND i_manager_id=7
AND d_moy=11
AND d_year=1999
AND ss_customer_sk = c_customer_sk
AND c_current_addr_sk = ca_address_sk
AND substr(ca_zip,1,5) <> substr (s_zip,1,5)
AND ss_store_sk = s_store_sk
GROUP BY i_brand,
i_manufact_id,
i_manufact
ORDER BY ext_price desc
i_brand,
i_brand_id
i_manufact_id,
i_manufact
LIMIT 10;
By creating external tables in Vertica that share the same data set with Hive tables, you can take full advantage of the fully ANSI SQL complaint Vertica SQL engine to analyze your data with much better performance, scalability, and, more importantly, completeness. In fact, with Vertica for SQL on Hadoop, you can execute 97 of 99 TPC-DS queries out the box successfully; the other 2 queries only need minor modification.
Tips for improving query performance with ORC: Predicate pushdown and Data Sorting
In older versions of Hive, rows are read out of the storage layer before being eliminated by SQL processing. ORC now has the ability to push query predicate down to the storage layer. The unique Vertica ORC file reader can take advantage of predicate pushdown and sorting to reduce the amount of data to read from the disk or across the network by applying ORCfile indexing, specifically with file statistics and stripe statistics. This helps you achieve a big reduction in execution time.
In this example, the customer_address table is sorted by column ca_state, and the customer table is sorted by column c_current_addr_sk. The ORC reader will return only those rows that actually match the WHERE predicate, and will only return records in ’CA’. It will skip the records of all other states.
=>SELECT count(*) FROM customer, customer_address WHERE c_current_addr_sk = ca_address_sk and ca_state='CA';
In general, when using ORC files, follow these guidelines:
- Use the latest Hive version
- Use a large stripe size(256MB or greater)
- Partition the data at the table level
- Sort the columns based on frequency of access, most-frequent first.
- Use Snappy or Zlib compression
Conclusion
The example above illustrations how you can improve the query performance further to meet your data exploratory needs.
As you can see, Vertica for SQL on Hadoop has the most comprehensive set of analytical functions of any SQL on Hadoop solutions. It is Hadoop distribution agnostic, and it is enterprise-ready with many proven petabyte scale deployments.
About the Author
Wei Wang



