


In Vertica version 8.0.0, we added integration for Apache Spark through our Vertica Connector for Apache Spark. This is a fast parallel connector that allows you to transfer data between Apache Spark and Vertica.
What is Apache Spark?
Apache Spark is an open-source, general-purpose, cluster-computing framework. The Spark framework is based on Resilient Distributed Datasets (RDDs), which are logical collections of data partitioned across machines.
When would I use the Spark connector?
Use the Spark connector in upstream workloads to process data before loading it in Vertica. You can also use the connector when you want to pre-process data in Vertica and then move it into Spark for further transformation.
The following graphic shows the runtime behavior of the connector when moving data from Vertica to Spark.

What can I do with the connector?
Using the Vertica Connector for Apache Spark, you can:
- Move large volumes of data from Spark DataFrames to Vertica tables.
- Save Spark data to Vertica with the DefaultSource API.
- Move data from Vertica to a Spark RDD or DataFrame.
To set up the connection from Vertica to Apache Spark, you need two JAR files:
- Vertica Apache Spark connector JAR file
- Vertica JDBC driver JAR file.
Read this topic for more prerequisites and specific usage instructions.
The DefaultSource API
The DefaultSource API (com.vertica.spark.datasource.DefaultSource) is optimized for moving large amounts of data from Spark DataFrames to Vertica tables, as well as loading Vertica data into a Spark DataFrame. The API provides generic key-value options for configuring the database connection and tuning parameters as well as other options.
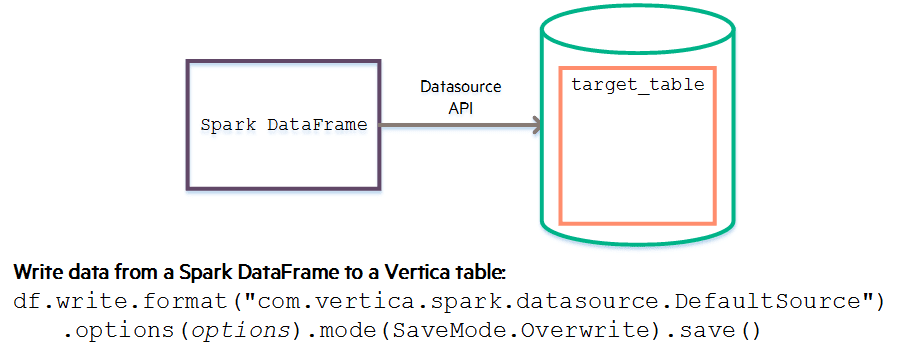
This example shows you how to write data from a Spark DataFrame to a Vertica table using the Spark df.write.format() method.
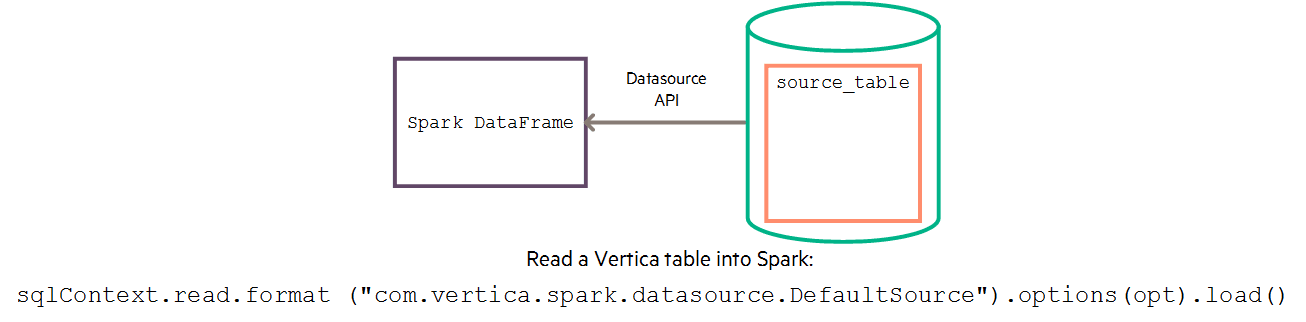
See this example to learn how to read a Vertica table into Spark by invoking the SQLContext.read() function.
From Spark to Vertica
Saving a Spark DataFrame to a Vertica Table
Using parallel read and write from HDFS, the connector can load large volumes of data from partitions distributed across multiple Spark worker-nodes into Vertica.
When writing Spark DataFrames to Vertica, youll specify a Vertica target table and indicate the DataFrame SaveMode, which specifies the expected behavior of saving a DataFrame to Vertica.
Here are your different SaveMode options:
- Overwrite:overwrites or creates a new table.
- Append:appends data to an existing table.
- ErrorIfExists:creates a new table if the table does not exist, otherwise it errors out.
- Ignore:creates a new table if the table does not exist, otherwise it does not save the data and does not error out.
You can monitor the save process by consulting the S2V_JOB_STATUS_USER_$USERNAME$ table, which includes the following columns:
- target_table_schema
- target_table_name
- save_mode
- job_name
- start_time
- all_done
- success
- percent_failed_rows
Saving Spark Data to Vertica Using the DefaultSource API
To simplify writing data from a Spark DataFrame to a Vertica table, use the com.vertica.spark.datasource.DefaultSource API with the Spark df.write.format()method.
From Vertica to Spark
To load Vertica table data into a Spark DataFrame, use the DefaultSource API with the Spark sqlContext.read.format() method.
You can create a VerticaRDD object either by initiating it or by calling one of the RDD.create methods.
Try out our new connector today! Read more in our full documentation.
New to Vertica? Download our free Community Edition.
About the Author
Sarah Lemaire
Manager, Vertica Documentation

