


This blog was written by Aliaksei Sandryhaila, Ignacio Hwang, and Mark Warner.
According to Wikipedia, an ORC is defined as follows:

Well, we are not going to talk about fictional orcs today. What we are going to discuss is the new functionality introduced in Vertica 7.1 SP2 that allows customers to access files in HDFS stored in ORC format and achieve significant performance benefits compared to raw text files.
The Vertica HDFS connector allows organizations to seamlessly access data housed in HDFS and blend it with other Vertica tables using standard business intelligence tools like Tableau. Starting with Vertica 7.1 SP2, Vertica has enhanced its ORC processing capability by providing both column pruning and predicate pushdown when accessing files in HDFS stored in ORC format. The performance improvements with this new implementation can be very significant compared to the standard HDFS connector using regular text files.
The development of the ORC reader API was a joint effort between the Vertica engineering team and the Hortonworks developers. All code resides on GitHub and is open to the public.
ORC Overview
ORC (Optimized Row Columnar) format is an open-source data storage format used by Hive. This is an efficient, column-oriented file format similar to Vertica’s native format. ORC stores tables by dividing them into groups of rows called stripes and by storing data within stripes in column order. Each column in the stripe is encoded using RLE, delta encoding, bit packing, or dictionary encoding and can be read separately, thus enabling column pruning. Stripes can be further compressed with zlib or snappy, leading to a further reduction in file size. Stripe metadata such as (min and max values per column and sum of all column elements) and indices allow for predicate pushdown and data skipping. Below is a diagram of the high-level ORC file format structure.
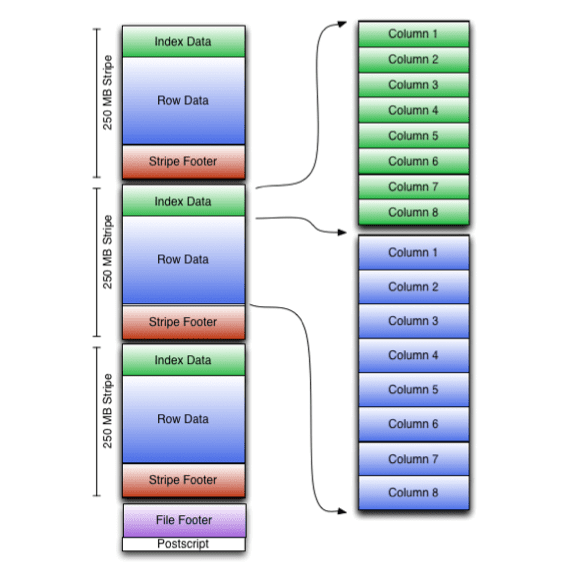
Note: Although ORC files are most often used with Hive, they are not unique to HDFS or Hive or anything else. ORC is an independent format in its own right, much like JSON or csv. For more details see: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
Query Performance Details
In Vertica, any node can act as an initiator for the planning and coordination to execute the query across the rest of the nodes, in this case, the Hadoop nodes. There is no concept of Master or Helper nodes. Vertica parallelizes the execution of the queries across all nodes to improve performance. Beyond this, we now have the ability to implement predicate pushdown and column pruning operations on stored in the ORC format.
When working with external tables in ORC format, Vertica tries to improve performance in two ways: by pushing query execution closer to the data so less has to be read and transmitted, and by taking advantage of data locality in planning the query.
Predicate pushdown moves parts of the query execution closer to the data, reducing the amount of data that must be read from disk or across the network. ORC files have three levels of indexing: file statistics, stripe statistics, and row group indexes. Predicates are applied only to the first two levels.
In a cluster where Vertica nodes are co-located on HDFS nodes, the query can also take advantage of data locality. If data is on a HDFS node where a database node is also present, and if the query is not restricted to specific nodes using ON NODE, then the query planner uses that database node to read the data. This allows Vertica to read data locally instead of making a network call.
When querying large external ORC tables, we recommend using predicates on integral (int, short, byte, long), floating-point (float, double), timestamp, date, and string (string, char, varchar) columns. With predicate pushdown, this can significantly reduce the amount of data actually being read by Vertica, and hence improve the performance.
Test Environment Load Process
For the purposes of this example, we compared loading normal raw text files in HDFS and ORC files in HDFS. Vertica provides the ability to dynamically access this kind of data using external tables, and will make a request for data every time a SQL statement is run against this external table. The out-of-the-box Vertica Vmart data was used to perform these tests. Listed below are the steps for the tests:
- Create Hive tables for both txt and ORC data.
- Load data into txt Hive tables.
- Copy data from txt Hive tables to ORC Hive tables.
- Create Vertica External Tables
- Run analyze_external_row_count statement for all external tables. (also new in 7.1.2)
- Configure Tableau Workbook to access both txt and ORC Vertica schemas.
Note: For testing purposes all the VMart tables were copied over to HDFS. It is safe to assume that this scenario will not be typical of a normal production environment and it is important to perform adequate testing to ensure performance expectations are met given the particulars of a customer’s data volumes. Be sure to follow the general guidelines for the creation of ORC files. These guidelines are identified in the Vertica documentation link provided in the summary.
Since Vertica has now exposed all the HDFS data as external tables, all we had to do to access this data in Tableau was to make a simple connection to Vertica in Tableau. There’s no need to configure a separate Hive connector in Tableau or perform any steps other than pointing the connection to the right schema in Vertica, ’ext’ for text files in HDFS or ’extorc’ for the new ORC files. Listed below is an example of one table implemented for these tests.
Create Hive tables for both txt and ORC data
CREATE TABLE shipping_dimension_orc
( shipping_key INT,
ship_type CHAR(30),
ship_mode CHAR(10),
ship_carrier CHAR(20)
STORED AS ORC;
CREATE TABLE shipping_dimension_txt
( shipping_key INT,
ship_type CHAR(30),
ship_mode CHAR(10),
ship_carrier CHAR(20)
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
Load data into txt Hive tables
LOAD DATA LOCAL INPATH '/opt/vertica/examples/VMart_Schema/Shipping_Dimension*' INTO TABLE shipping_dimension_txt;
Copy data from txt Hive tables to ORC Hive tables.
INSERT OVERWRITE table shipping_dimension_orc select * from shipping_dimension_txt;
Create Vertica External Tables
CREATE EXTERNAL TABLE ext.shipping_dimension
( shipping_key INTEGER NOT NULL PRIMARY KEY,
ship_type CHAR(30),
ship_mode CHAR(10),
ship_carrier CHAR(20)
) AS COPY SOURCE Hdfs(url='http://sandbox:50070/webhdfs/v1/user/hdfs/vmartext/shipping_dimension/*' ,username='hive');
CREATE EXTERNAL TABLE table extorc.shipping_dimension
( shipping_key INTEGER NOT NULL PRIMARY KEY,
ship_type CHAR(30),
ship_mode CHAR(10),
ship_carrier CHAR(20)
) AS COPY FROM 'webhdfs://sandbox:50070/apps/hive/warehouse/shipping_dimension_orc/*' ON ANY NODE ORC;
Note the difference in the syntax above for the copy command. The first example is showing how external tables can use the Vertica HDFS Connector, while the second one is using Vertica’s built-in ORC reader, which is new with starting with 7.1.2
At this point we can now configure Tableau to access the data in the two above schemas in Vertica. All tables in the Vertica ’ext’ schema are regular text files and all tables in the ‘extorc’ schema are the ORC files. The only data change made was to change the time data type to varchar since HIVE does not support time data type.
Parallel Processing and Vertica
Notice the syntax above for the copy command is using wild cards and the ON ANY NODE syntax. This will allow Vertica to parallelize the query to HDFS for both text version and ORC versions. Listed below are the sequence of steps performed when this happens.
- First step is to ask the Hadoop NamedNode for the location of the data in HDFS.
- Since globs were used in the copy commands each node in the Vertica cluster will make requests directly to the HDFS node containing data.
The diagram below shows how this works.

Results
For this example, a Tableau workbook was used to simulate what a typical business intelligence tool would generate from a SQL perspective. Here is a sample screenshot of the dashboard accessing data in HDFS using the new ORC reader. This capability gives you full ANSI SQL compliance of your data in HFDS.

When this dashboard renders, multiple SQL statements are generated. For the purposes of this blog, random SQL samples from different dashboards were chosen from Tableau. Here is an example of how metrics were captured.
timing
o /dev/null
SELECT call_center_dimension.cc_region AS customer_atribute__copy_2_,
SUM(online_sales_fact.sales_dollar_amount) AS temp_calculation_3970402142831247__1452178030__0_,
SUM(online_sales_fact.sales_quantity) AS temp_calculation_3970402142831247__2302502211__0_,
SUM(online_sales_fact.gross_profit_dollar_amount) AS temp_calculation_3970402142831247__851546239__0_,
SUM(online_sales_fact.cost_dollar_amount) AS temp_calculation_3970402142831247__922861288__0_,
SUM(online_sales_fact.sales_quantity) AS sum_calculation_7040319094333030_ok
FROM extorc.online_sales_fact online_sales_fact
INNER JOIN extorc.date_dimension sale_date_dimension ON (online_sales_fact.sale_date_key = sale_date_dimension.date_key)
INNER JOIN extorc.call_center_dimension call_center_dimension ON (online_sales_fact.call_center_key = call_center_dimension.call_center_key)
WHERE ((call_center_dimension.cc_region = 'West') AND ('purchase' = online_sales_fact.transaction_type) AND ((sale_date_dimension.date >= (DATE '2003-01-01')) AND (sale_date_dimension.date <= (DATE '2005-12-31'))))
GROUP BY 1
Sample output results
| Test | ORC is Times
Faster than External Text |
| ed_orc.sql | 2.72 |
| ed_ext.sql | |
| ed_orc2.sql | 3.38 |
| ed_ext2.sql | |
| osd_ord1.sql | 2.23 |
| osd_ext1.sql | |
| osd_orc2.sql | 2.54 |
| osd_ext2.sql | |
| Average | 2.72 |
As you can see on average for the samples that used the Vertica ORC reader was about 2.72 times faster than using the standard Vertica HDFS connector with text format in HDFS. Note: It is important for customers who have critical performance needs to consider what kind of data is appropriate for housing in HDFS since the performance is still not as fast as native Vertica ROS format.
Summary
The ability to read ORC files will allow Vertica to co-exist with the Hadoop ecosystem and directly access data from the “Hadoop data lake.” A fast ORC reader that supports predicate pushdown and column pruning will allow Vertica users to efficiently access their Hive data and work with them using the full functionality of a MPP RDBMS, making Vertica an attractive alternative to Hive.
We hope that this example has showed how ORC is not just a ’fictional fantasy’. Rather, when used with Vertica, ORC can allow you to obtain tangible benefits and fight the constant battle of performance with increased functionality. See links below for more details.
Vertica Documentation on ORC
About the Author
M_Warner


