


This blog post is based on a white paper authored by Maurizio Felici.
What is Logistic Regression?
Logistic regression is a popular machine learning algorithm used for binary classification. Logistic regression labels a sample with one of two possible classes, given a set of predictors in the sample. Optionally, the output can be the probability that a sample belongs to a given class.
For example, suppose a researcher is interested in the factors that determine if a student will be accepted or rejected to graduate school. The response is binary – admit or don’t admit. The researcher might look at factors such as undergraduate GPA, GRE score, and work experience.
The standard logistic function is defined as the following:

Where y represents the dependent variable, and x is the independent variable(s), defined as:
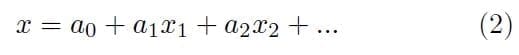
In our example, the dependent variable is the binary response (admit or don’t admit), and the independent variable consists of all the factors we plan to consider.
Training of logistic regression in Vertica is a two-step process:
1. Build the model – a training data set is used to find the best values for the coefficients given in equation (2) above.
2. Evaluate the model – the model created in Step 1 is applied to a testing data set to predict the dependent variable based on the independent variables. We can compare the predicted output with the actual values to evaluate how good the prediction is.
Now that we’ve covered the basics, let’s work through an example to better understand logistic regression.
The Titanic Data Set
The Titanic tragically sank in the Atlantic Ocean in the early morning of April 15th, 1912 after it collided with an iceberg. This example uses a data set containing passenger information from the Titanic.
Note: You can find the data set we used on the Vanderbilt Department of Biostatistics site.
The data set contains information about the following:
• pclass: Passenger class (1st, 2nd or 3rd)
• survival: 0 = No; 1 = Yes
• name: Passenger name
• sex: Passenger sex
• age: Age in years
• sibsp: Number of siblings/spouses aboard
• parch: Number of parents/children aboard
• ticket: Ticket number
• fare: Passenger fare
• cabin: Cabin number
• embarked: Port of embarkation, C = Cherbourg; Q = Queenstown, S = Southampton
• boat: Lifeboat number
• body: Body number
• home.dest: Home or destination
We will use this data set to predict survival (either 0 or 1) based on other columns, such as passenger class, age, and gender. To do this, we will split the original data set into two randomly selected tables named “train” and “test” with 70% and 30% of samples respectively:
• train: This table will be used to generate the logistic regression model
• test: After the model is generated, we will use this table to check the model’s accuracy
Loading the Data
Let’s use the following table definition to load the data set:
=> CREATE TABLE public.titanic (
pclass integer,
survived integer,
name varchar(96),
gender integer,
age numeric(6,3),
sibsp integer,
parch integer,
ticket varchar(24),
fare numeric(7,4),
cabin char(10),
embarked integer,
boat char(4),
body integer,
homedest varchar(64),
split float DEFAULT RANDOM()
) ;
All of the columns from the original data set appear in the table definition, along with an additional column named split. The split column will be used to separate the data set into “train” and “test”.
Let’s assume that the downloaded file is named “titanic3.csv”. To use the COPY command to load this data into a table, we must first replace any empty pair of double quotes with a backslash followed by a double quote. While this can be done using any text editor, you can also use the following Linux command:
sed –i 's/""/\\"/g' titanic3.csv
To load the data from the file to the table, we will use the COPY command:
=> \set titanic_file '\' absolute path/titanic3.csv\''
=> COPY public.titanic (
pclass, survived, name,
fgend FILLER varchar(6),
gender AS DECODE (fgend,'female',0,'male,1),
age, sibsp, parch, ticket, fare, cabin,
femb FILLER char(1),
embarked AS DECODE(femb,'C',1,'Q',2,'S',3),
boat, body, homedest)
FROM :titanic_file
DELIMITER ','
ENCLOSED BY '"'
ESCAPE AS '\'
SKIP 1
ABORT ON ERROR
DIRECT ;
Because logistic regression only uses numeric values as inputs when calculating the coefficients, we performed a data transformation in the COPY statement above. This transformation replaced text with numeric values for both gender and embarkment.
Missing Values
The logistic regression algorithm doesn’t accept missing values. If one of the predictors is NULL, the whole row is discarded.
In the original data set, there are several missing NULL values in the age column. To avoid excluding the whole row, we replace the NULL ages with the average age of the people with the same gender in the same class.
We perform this replacement at the same time we create the “train” and “test” tables.
First, let’s create the train table:
=> CREATE LOCAL TEMPORARY TABLE train
ON COMMIT PRESERVE ROWS AS /*+DIRECT*/
SELECT
pclass,
survived,
gender,
COALESCE(age, avg_age) AS age,
(sibsp + parch + 1) AS family_size,
fare, embarked
FROM (
SELECT
pclass,
survived,
gender,
age,
sibsp,
parch,
fare,
embarked,
AVG(age) OVER(
PARTITION BY pclass,gender)
AS avg_age,
split
FROM public.titanic )
x
WHERE x.split < 0.7;
Then create the test table:
=> CREATE LOCAL TEMPORARY TABLE test
ON COMMIT PRESERVE ROWS AS /*+DIRECT*/
SELECT
pclass,
survived,
gender,
COALESCE(age, avg_age) AS age,
(sibsp + parch + 1) AS family_size,
COALESCE(fare,avg_fare) AS fare,
COALESCE(embarked,3) AS embarked
FROM (
SELECT
pclass,
survived,
gender,
age,
sibsp,
parch,
fare,
embarked,
AVG(age) OVER(
PARTITION BY pclass,gender)
AS avg_age,
AVG(fare) OVER(
PARTITION BY pclass, gender)
AS avg_fare,
split
FROM public.titanic )
x
WHERE x.split >= 0.7 ;
A few important points to remember:
• We split the original data set using the split column that was generated during the loading phase.
• We skipped all non-numeric columns when we create the two tables because logistic regression only uses numeric column. For simplicity, we won’t cover the non-numeric columns in this example.
• We created the column family_size, which is a combination of sibsp and parch, to determine if the size of the family has an impact on survival rate.
Create a Logistic Regression Model
Now, let’s use the Vertica machine learning functions to create our model. To create the model, we will use the LOGISTIC_REG function on the train table. Survived is the dependent variable, and the independent variables are pclass, age, gender, family_size, fare, and embarked:
=> SELECT LOGISTIC_REG(
'titanic',
'v_temp_schema.train',
'survived',
'pclass,age,gender,family_size,
fare,embarked') ;
After we generate the model, we use the PREDICT_LOGISTIC_REG and ERROR_RATE functions on the test table to compare the prediction value with the actual values and measure error rate:
=> SELECT ERROR_RATE (
obs, predict::int USING PARAMETERS num_classes=2)
OVER()
FROM (
SELECT survived AS obs, PREDICT_LOGISTIC_REG (
pclass, age, gender,
family_size,
fare, embarked
USING PARAMETERS MODEL_NAME='titanic',
OWNER='dbadmin')
AS predict
FROM
test ) AS prediction_output ;
The result is 0.17, which means that our model correctly predicted the survived value in more than 82 percent of the cases.
We can also group the prediction accuracy by age and passenger class:
=> SELECT
pclass,
CASE WHEN gender = 1 THEN 'male'
ELSE 'female' END AS gender,
(100 * SUM(
CASE WHEN survived = predict
THEN 1 ELSE 0 END) / COUNT(*)
)::NUMERIC(5,2) as accuracy_perc
FROM (
SELECT
pclass,gender,survived,
PREDICT_LOGISTIC_REG (
pclass,
age,
gender,
family_size,
fare,
embarked
USING PARAMETERS OWNER='dbadmin',
MODEL_NAME='titanic') AS predict
FROM
test) AS prediction_output
GROUP BY pclass, gender
ORDER BY accuracy_perc DESC
;
Note: In Vertica 8.1, the OWNER parameter will be deprecated.
pclass | gender | accuracy_perc
--------+--------+---------------
1 | female | 95.00
3 | male | 91.78
2 | male | 86.21
2 | female | 84.38
1 | male | 68.09
3 | female | 59.32
From this chart, we can see that females in first class were most accurately predicted, while females in third class were least accurately predicted.
References
[1] How to Perform a Logistic Regression in R – datascience+
[2] Titanic: Machine Learning from Disaster – Kaggle
[3] Titanic data set at biostat.mc.vanderbilt.edu
For more information, see Machine Learning for Predictive Analytics in the Vertica documentation.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


