



The answer is YES if it is the right kind of tree. Here ?tree? refers to a common data structure that consists of parent-child hierarchical relationship such as an org chart. Traditionally this kind of hierarchical data structure can be modeled and stored in tables but is usually not simple to navigate and use in a relational database (RDBMS). Some other RDBMS (e.g. Oracle) has a built-in CONNECT_BY function that can be used to find the level of a given node and navigate the tree. However if you take a close look at its syntax, you will realize that it is quite complicated and not at all easy to understand or use.
For a complex hierarchical tree with 10+ levels and large number of nodes, any meaningful business questions that require joins to the fact tables, aggregate and filter on multiple levels will result in SQL statements that look extremely unwieldy and can perform poorly. The reason is that such kind of procedural logic may internally scan the same tree multiple times, wasting precious machine resources. Also this kind of approach flies in the face of some basic SQL principles, simple, intuitive and declarative. Another major issue is the integration with third-party BI reporting tools which may often not recognize vendor-specific variants such as CONNECT_BY.
Other implementations include ANSI SQL?s recursive SQL syntax using WITH and UNION ALL, special graph based algorithms and enumerated path technique. These solutions tend to follow an algorithmic approach and as such, they can be long on theory but short on practical applications.
Since SQL derives its tremendous power and popularity from its declarative nature, specifying clearly WHAT you want to get out of a RDBMS but not HOW you can get it, a fair question to ask is: Is there a simple and intuitive approach to the modeling and navigating of such kind of hierarchical (recursive) data structures in a RDBMS? Thankfully the answer is yes.
In the following example, I will discuss a design that focuses on ?flattening? out such kind of hierarchical parent-child relationship in a special way. The output is a wide sparsely populated table that has extra columns that will hold the node-ids at various levels on a tree and the number of these extra columns is dependent upon the depth of a tree. For simplicity, I will use one table with one hierarchy as an example. The same design principles can be applied to tables with multiple hierarchies embedded in them. The following is a detailed outline of how this can be done in a program/script:
- Capture the (parent, child) pairs in a table (table_source).
- Identify the root node by following specific business rules and store this info in a new temp_table_1. Example: parent_id=id.
- Next find the 1st level of nodes and store them in a temp_table_2. Join condition: temp_table_1.id=table_source.parent_id.
- Continue to go down the tree and at the end of each step (N), store data in temp_table_N. Join condition: temp_table_M.parent_id=temp_table_N.id, where M=N+1.
- Stop at a MAX level (Mevel) when there is no child for any node at this level (leaf nodes).
- Create a flattened table: table_flat by adding in total (Mlevel+1) columns named as LEVEL, LEVEL_1_ID,?.LEVEL_Mlevel_ID.
- A SQL insert statement can be generated to join all these temp tables together to load into the final flat table: table_flat.
- When there are multiple hierarchies in one table, the above procedures can be repeated for each
hierarchy to arrive at a flattened table in the end.
This design is general and is not specific to any particular RDBMS architecture, row or column or hybrid. However the physical implementation of this design naturally favors columnar databases such as Vertica. Why? The flattened table is usually wide with many extra columns and these extra columns tend to be sparsely populated and they can be very efficiently stored in compressed format in Vertica. Another advantage is that when a small set of these columns are included in the select clause of an SQL, because of Vertica?s columnar nature, the other columns (no matter how many there are) will not introduce any performance overhead. This is as close to ?free lunch? as you can get in a RDBMS.
Let?s consider the following simple hierarchical tree structure:
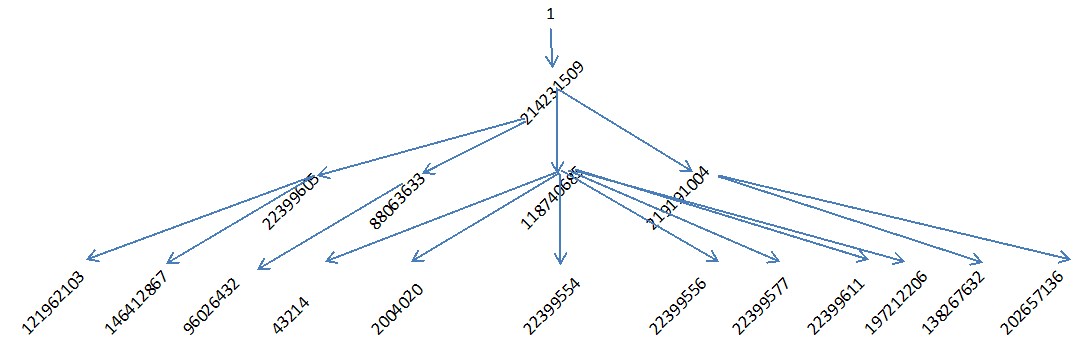
There are four levels and the root node has an ID of 1. Each node is assumed to have one and only one parent (except for the root node) and each parent node may have zero to many child nodes. The above structure can be loaded into a table (hier_tab) having two columns: Parent_ID and Node_ID, which represent all the (parent, child) pairs in the above hierarchical tree:
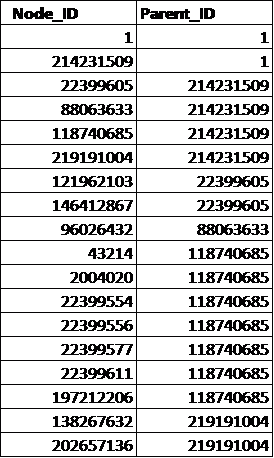
It is possible to develop a script to ?flatten? out this table by starting from the root node, going down the tree recursively one level at a time and stopping when there is no data left (i.e. reaching the max level or depth of the tree). The final output is a new table (hier_tab_flat):
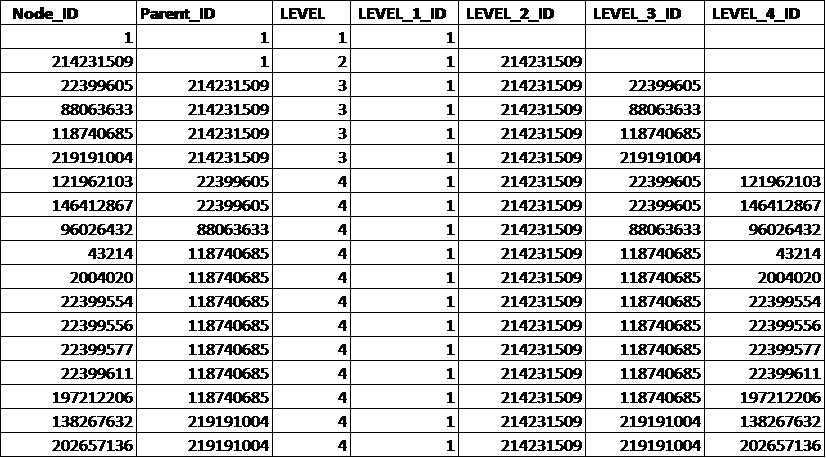
What?s so special above this ?flattened? table? First, this table has the same key (Node_ID) as the original table; Second, this table has several extra columns named as LEVEL_N_ID and the number of these columns is equal to the max number of levels (4 in this case) plus one extra LEVEL column; Third, for each node in this table, there is a row that includes the ID?s of all of its parents up to the root (LEVEL=1) and itself. This represents a path starting from a node and going all the way up to the root level.The power of this new ?flattened? table is that it has encoded all the hierarchical tree info in the original table. Questions such as finding a level of a node and all the nodes that are below a give node, etc. can be translated into relatively simple SQL statements by applying predicates to the proper columns.
Example 1: Find all the nodes that are at LEVEL=3.
Select Node_ID From hier_tab_flat Where LEVEL=3;Example 2: Find all the nodes that are below node= 88063633.
This requires two logical steps (which can be handled in a front-end application to generate the proper SQL).
Step 2.1. Find the LEVEL of node= 88063633 (which is 3).
Select LEVEL From hier_tab_flat Where Node_ID=88063633;
Step 2.2. Apply predicates to the column LEVE_3_ID:
Select Node_ID From hier_tab_flat Where LEVE_3_ID =88063633;
Complex business conditions such as finding all the nodes belonging to node=214231509 but excluding the nodes that are headed by node=88063633 can now be translated into the following SQL:
Select Node_IDBy invoking the script that flattens one hierarchy repeatedly, you can also flatten a table with multiple hierarchies using the same design. With this flattened table in your Vertica tool box, you can climb up and down any hierarchical tree using nothing but SQL.
From hier_tab_flat
Where LEVE_2_ID=214231509
And LEVE_3_ID <> 88063633 ;
Po Hong is a senior pre-sales engineer in Vertica?s Corporate Systems Engineering (CSE) group with a broad range of experience in various relational databases such as Vertica, Neoview, Teradata and Oracle
About the Author
Po Hong



