- Product
- Product Resource

Vertica Announces Vertica 12 for Future-Proof Analytics
Latest version of analytics database enables more deployment flexibility, advanced analytics, and enhanced machine learning
-
- Partners
- Partners Resource

Vertica Inside – Embedded Analytics at Scale
Seize the huge growth opportunity for OEM software developers
-
Machine Learning
Get the Power to Operationalize Machine Learning – at Scale
Because data scientists are forced to down-sample, move data, and settle for sluggish computation, the promise of predictive analytics at scale with complete accuracy has only been a dream. Until now. Watch this video to learn how Vertica’s in-database machine learning empowers teams to put machine learning into operation – whether your data scientists want to build models in Python, or data analysts and engineers prefer a SQL-based approach.
Vertica In-database Machine Learning
Vertica’s in-database machine learning supports the entire predictive analytics process with massively parallel processing and a familiar SQL interface, allowing data scientists and analysts to embrace the power of Big Data and accelerate business outcomes with no limits and no compromises.
Vertica Training: Machine Learning & Predictive Analytics
Want to know the latest in machine learning model development, data preparation, regression algorithms, clustering algorithms and more?
Check out the newly launched Digital Learning course: Predictive Analytics Using Machine Learning.
This 4-hour course, consisting of six self-paced modules, is designed with both new and experienced users. Improve your machine learning know-how, and put those algorithms to the test!

Put the full power of Vertica behind Python data science
The VerticaPy library gives Python scale and performance
Python is the most popular language for machine learning workflows, but it can only work within a computer’s memory. To get the most accurate models, you need to prepare and train on data sets far beyond that limitation.
With VerticaPy, you can use full data sets without downsampling, do data preparation in a fraction of the time, and use every feature that contributes to accuracy with Vertica’s blazing-fast performance.
Machine Learning and Predictive Analytics is changing the way companies across every industry operate, grow and stay competitive
Financial Services
Discover fraud, detect investment opportunities, identify clients with high-risk profiles and determine the probability of an applicant defaulting on a loan.
Telecommunications
Analyze network performance, predict capacity constraints and ensure quality of service delivery to end customers.
AdTech
Optimize audience targeting, analyze visitor behavior through A/B and multivariate testing, and predict user engagement patterns.
Manufacturing
Identify product defects, predict equipment maintenance needs, optimize supply chain planning, and forecast demand.
End-to-end Machine Learning Management
From data prep to deployment, Vertica supports the entire machine learning process:
- Explore and prepare data with functions for normalization, correlation, outlier detection, sampling, imbalanced data processing, and more
- Join disparate time series data sets and impute missing values
- Use geospatial functions to cluster, geo-fence, and analyze by location
- Evaluate model-level statistics including ROC tables and confusion matrices
- Revert back to previous model iterations using model management and version control
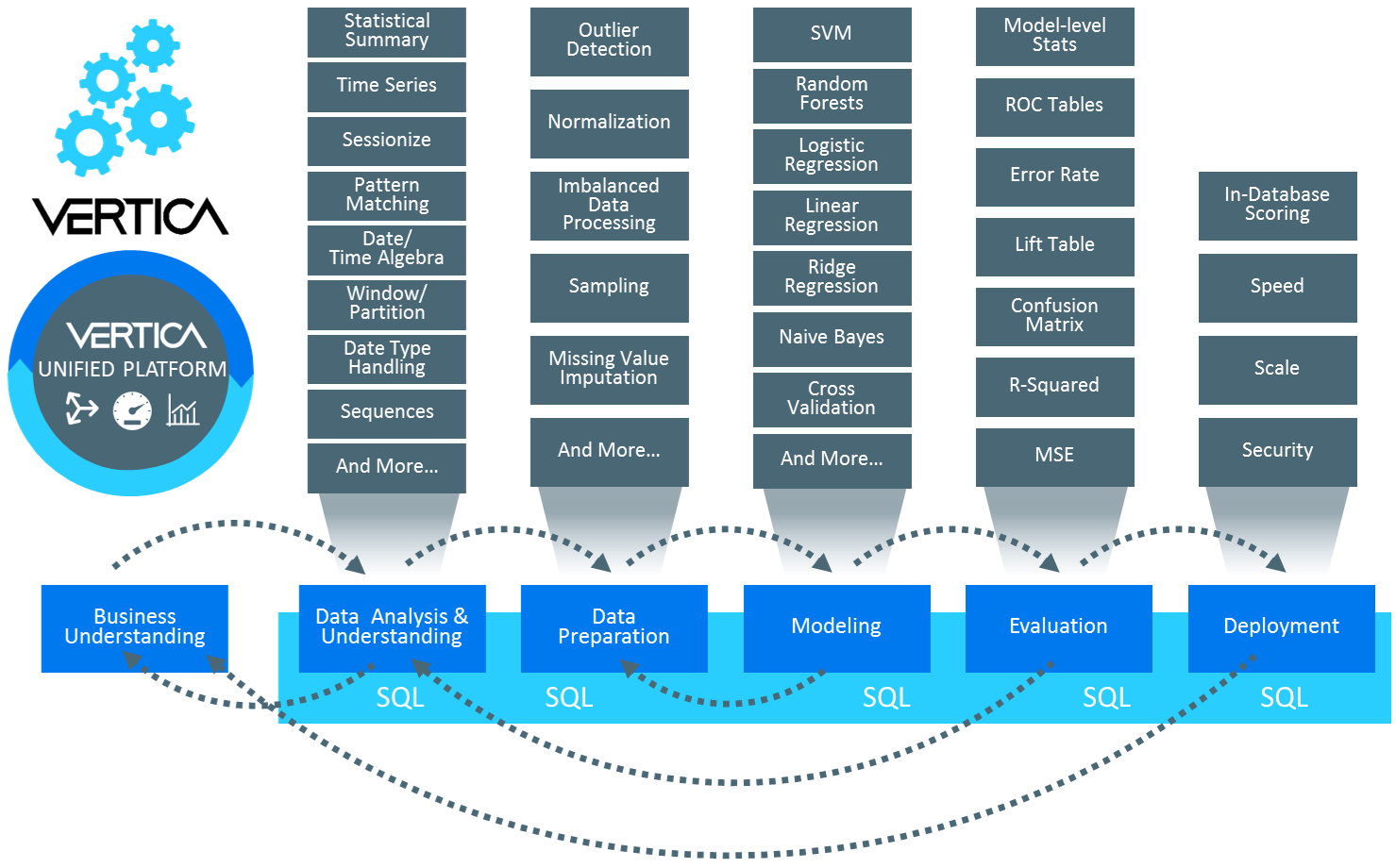
Massively Parallel Processing (MPP) Architecture
Build and deploy models at Petabyte-scale with extreme speed and performance:
- Leverage high scalability on clusters with no name node or other single point of failure
- Train our built-in distributed algorithms on massive data sets rapidly
- Boost query performance with 10-50x faster results than legacy data warehouses
- Lower costly I/O with columnar storage and advanced data compression
- Use subclusters to dedicate compute to machine learning to use clean data warehouse data without bogging down BI
Simple SQL Execution
Democratize predictive analytics with user-friendly, SQL-based machine learning functions:
- Train, manage and deploy machine learning models using simple SQL calls
- Increase productivity of machine learning teams with fast data preparation and shorter development cycles
- Access advanced analytics with SQL: pattern matching, regression, geospatial, time series, clustering, and more
Familiar Programming Languages
Develop user-defined extensions (UDx) with C++, Java, Python or R:
- Increase the power and flexibility of procedural code by bringing it close to the data
- Analyze data quickly by executing algorithms in parallel on each node in the cluster
- Create and deploy C++, Java, Python or R libraries directly in Vertica
- Import and put to work PMML for TensorFlow, Python, and more
Vertica’s built-in machine learning algorithms support classification, clustering and predictive applications with functions for model training, scoring and evaluation.
Engineering Distributed Machine Learning
Are you interested in a technical deep-dive on Vertica’s built-in machine learning? Here is a paper, written by Vertica’s Chief Architect and Engineering leaders, that describes our distributed machine learning subsystem within the Vertica database. It includes Vertica’s current SQL machine learning functionalities that cover a complete data science workflow as well as model management.
The problem with traditional tools is that the growing volume and velocity of data has increased the complexity of creating and deploying machine learning models – requiring more time and resources to bring predictive analytics projects to fruition.
Scalability
Scale-out MPP architecture handles massive volumes of data with blazing fast speed
Speed
End-to-end process reduces time spent preparing, normalizing and moving data
Simplicity