




Vertica Integration with Pentaho Data Integration (PDI): Tips and Techniques
About Vertica Connection Guides
Vertica develops Tips and Techniques documents to provide you with the information you need to use Vertica with third-party products. This document provides guidance using one specific version of Vertica and one version of the vendor's software. While other combinations are likely to work, we may not have tested the specific versions you are using.
Overview
This document provides guidance for configuring Pentaho Data Integration (PDI, also known as Kettle) to connect to Vertica. It outlines some of the best practices to load data using components such as table output and bulk loader. You can also configure Vertica for better performance by enabling PDI parallelization, monitoring resources, and more which is explained in detail in this guide.
This document covers only PDI. However, connectivity options for other Pentaho products should be similar to the options this document provides.
These tips and techniques are tested with PDI 9.3 and Vertica 12.0.0 versions. Most of the information also applies to earlier versions of both products.
Connecting Vertica to Pentaho (PDI)
PDI connects to Vertica using the Vertica JDBC driver. This document is based on our testing with the Vertica 12 JDBC driver. Follow these instructions to download and install the JDBC driver:
-
Navigate to the Vertica Client Drivers page on the Vertica website.
-
Download the JDBC driver package.
-
Copy the JAR file you downloaded.
-
Locate the directory where Pentaho is installed.
-
Copy the Vertica JAR file to the folder
\data-integration\libin your PDI installation.In this example,
C:\<Pentaho>\data-integration\lib
Note <Pentaho> in the file locations above refers to the name of the directory where Pentaho BA is installed.
Installing the JDBC Driver
Store your Vertica JDBC driver file in a folder similar to C:\<Pentaho>\data-integration\lib\ (for a Windows system). The following screenshot shows how to connect to Vertica.

Vertica Client Driver/Server Compatibility
Usually, each version of the Vertica server is compatible with the previous version of the client drivers. This compatibility lets you upgrade your Vertica server without having to immediately upgrade your client software. However, some new features of the new server version may not be available through the old drivers.
For more information, see Client Driver and Server Version compatibility in the Vertica documentation.
Reading Data from Vertica with Input Components
PDI provides an input component that you can use to run SELECT statements on the Vertica database, as the following figure shows:
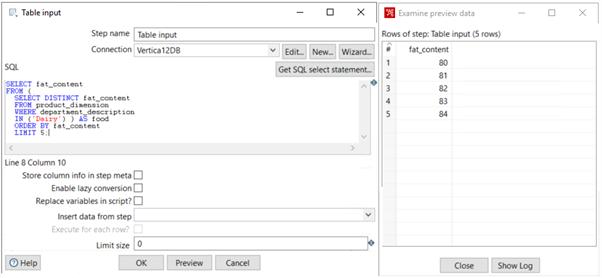
Writing Data to Vertica
You can write data to a Vertica table using either of two PDI components:
- Standard table output component
- Vertica Bulk Loader for PDI
In limited testing, the Vertica Bulk loader is faster than using the standard table output component. However, test the integration on your own system to verify that all necessary capabilities are available and that your service-level agreements can be met.
Using Vertica COPY
The COPY statement bulk loads data into a Vertica database. You can load one or more files, or pipes on a cluster host. You can also load directly from a client system, using the COPY statement with its FROM LOCAL option. For more information, see the COPY documentation in the SQL Reference Manual for details.
Raw input data must be in UTF-8, delimited text format. Data is compressed and encoded for efficient storage.
Bulk Loading Guidelines
-
You can pass the COPY statement parameters that define the format of the data in the file, the data that is to be transformed as it is loaded, handling errors, and loading data.
-
Databases created in versions 10.0 or later no longer support WOS and moveout operations; all data is always loaded directly into ROS.
- Use INSERT when the row count is small (< 1000 rows).
- Load multiple streams on different nodes.
-
Using COPY reduces overhead of per-plan INSERT cost.
Vertica COPY Example: Execute SQL Script Statement Component
You can load data directly into Vertica from a client system using the COPY statement with the FROM LOCAL option. PDI components generate only the COPY LOCAL option. However, if your data files are on the Vertica cluster, you can use COPY with the PDI Execute SQL Script statement component. The following example shows how to use this component to load a Vertica flex table:
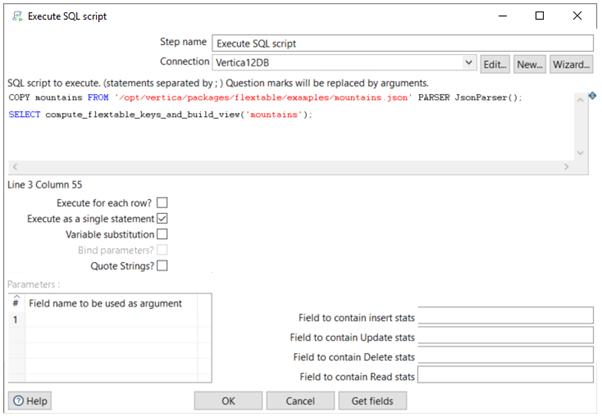
You can enter any valid SQL such as:
=> COPY mountains FROM '/opt/vertica/packages/flextable/examples/mountains.json'
PARSER fjsonparser();
=> SELECT compute_flextable_keys_and_build_view('mountains');
Note To learn more about the above example, see Flex Tables in Vertica.
By default, COPY uses the DELIMITER parser to load raw data into the database. Raw input data must be in UTF-8, delimited text format. Data is compressed and encoded for efficient storage. If your raw data does not consist primarily of delimited text, specify the parser that COPY should use to align most closely with the load data.
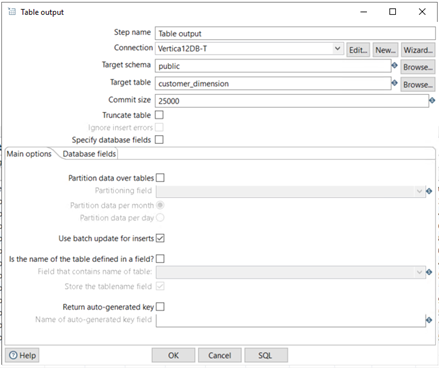
Loading Data into Vertica with the Standard Table Output Component
The following figure shows the standard table output component:
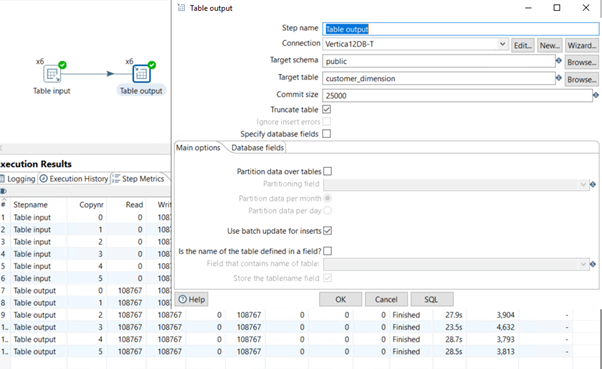
In this example, the standard table output component generates the following COPY statement:
COPY public.customer_dimension ( customer_key, customer_type, customer_name, customer_gender, title, household_id, customer_address, customer_city, customer_state, customer_region, marital_status, customer_age, number_of_children, annual_income, occupation, largest_bill_amount, store_membership_card, customer_since, deal_stage, deal_size, last_deal_update ) FROM LOCAL STDIN NATIVE VARCHAR ENFORCELENGTH RETURNREJECTED NO COMMIT
Vertica Bulk Loader for PDI
PDI provides a Vertica Bulk Loader for PDI plugin, as shown:
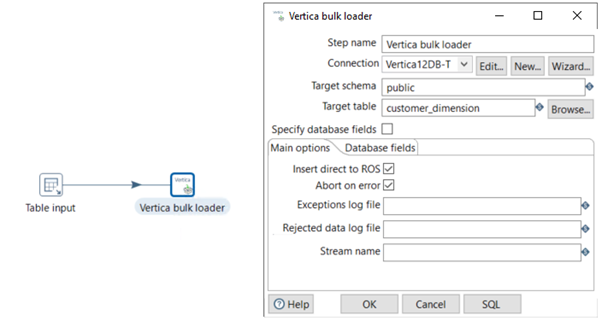
By default, the Vertica Bulk Loader for PDI plugin is included in the PDI Enterprise as well as Community Edition.
Best Practices for Loading and Updating Data
Resource pool parameters and configuration parameters affect the performance of data load.
Vertica can divide the work of loading data, taking advantage of parallelism to speed up the operation. Vertica supports several types of parallelism:
-
Distributed load: Vertica distributes files in a multi-file load to several nodes to load in parallel, instead of loading all of them on a single node. Vertica manages distributed load; you do not need to do anything special in your UDL.
-
Cooperative parse: A source being loaded on a single node uses multi-threading to parallelize the parse. Cooperative parse divides a load at execution time, based on how threads are scheduled. You must enable cooperative parse in your parser. See Cooperative Parse.
-
Apportioned load: Vertica divides a single large file or other single source into segments, which it assigns to several nodes to load in parallel. Apportioned load divides the load at planning time, based on available nodes and cores on each node. You must enable apportioned load in your source and parser. See Apportioned Load.
There are many possible reasons as to why a load is not performing to expectations. Both Pentaho and Vertica provide a number of documents and best practices that can help you troubleshoot data load issues.
PDI Best Practices for Data Load
Follow this link to check out PDI performance tips:
Note For more information about PDI transformations and steps, see Transformations, Steps, and Hops in the PDI documentation.
Consider the following root causes for transformation flow problems:
- Lookups
- Scripting steps
- Memory hogs
- Lazy conversion
- Blocking step
- Commit size, Rowset size
Consider the following root causes for job workflow problems:
- Operating system constraints—memory, network, CPU
- Parallelism
- Looping
- Execution environment
For more information about optimizing data loads with PDI, there is a fantastic book on optimizing PDI called Pentaho Kettle Solutions. This book describes advanced operations like clustering PDI servers.
Improving the Performance of Data Load
At a minimum, consider two PDI settings to improve the performance for a particular load.
COMMIT Size
The size of a COMMIT operation is important for data load performance, Based on testing, 25000 rows seems to be a good place to start. You may have to modify the commit size depending on the source system table size and number of columns.
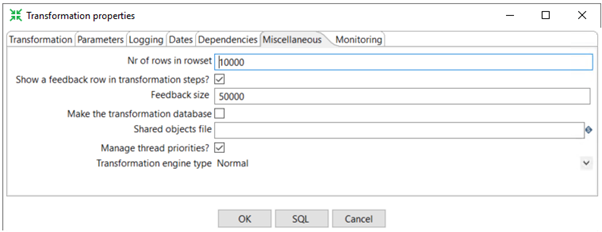
Number of Rows in Row Set
The number of rows in the RowSet setting depends on the machine memory and row set size. To set this option, go to the Transformation properties dialog box, the Miscellaneous tab.
Configuring Vertica to Work with PDI
Consider these tips when using Vertica with PDI:
- Managing Vertica Resources
- Managing Vertica ROS Containers
- Using Linux to Monitor Resource Usage
- Data Type Mappings
- Using Non-ASCII Data
Managing Vertica Resources
To prevent query users from being affected by ETL jobs, create a separate resource pool for PDI. Your resource pool settings depend on the amount of memory on the machine and the number of resource pools available for users. The following SQL statements show how to create a PDI resource pool:
=> CREATE RESOURCE POOL batch_pool MEMORYSIZE '4G' MAXMEMORYSIZE '84G' MAXCONCURRENCY 36; => DROP USER pentaho_pdi; => DROP SCHEMA pentaho_pdi_s; => CREATE SCHEMA pentaho_pdi_s; => CREATE user pentaho_pdi identified by 'pentaho_pwd' SEARCH_PATH pentaho_pdi_s; => GRANT USAGE on SCHEMA pentaho_pdi_s to pentaho_pdi; => GRANT USAGE on SCHEMA PUBLIC to pentaho_pdi; => GRANT USAGE on SCHEMA online_sales to pentaho_pdi; => GRANT USAGE on SCHEMA store to pentaho_pdi; => GRANT SELECT on ALL TABLES IN SCHEMA PUBLIC to pentaho_pdi; => GRANT SELECT on ALL TABLES IN SCHEMA store to pentaho_pdi; => GRANT SELECT on ALL TABLES IN SCHEMA online_sales to pentaho_pdi; => GRANT ALL PRIVILEGES ON SCHEMA pentaho_pdi_s TO pentaho_pdi WITH GRANT OPTION; => GRANT CREATE ON SCHEMA pentaho_pdi_s to pentaho_pdi; => GRANT USAGE ON RESOURCE POOL batch_pool to pentaho_pdi; => ALTER USER pentaho_pdi RESOURCE POOL batch_pool;
Managing Vertica ROS Containers
By default, Vertica supports up to 1024 ROS containers to store partitions for a given projection (see Projection Parameters). Depending on the amount of data per partition, a partition or partition group can span multiple ROS containers.
Given this limit, it is inadvisable to partition a table on highly granular data—for example, on a TIMESTAMP column. Doing so can generate a very high number of partitions. If the number of partitions requires more than 1024 ROS containers, Vertica issues a ROS pushback warning and refuses to load more table data. A large number of ROS containers also can adversely affect DML operations such as DELETE, which requires Vertica to open all ROS containers.
ROS containers consume system resources, so the number of ROS containers has a direct effect on system performance. A large number of ROS containers can degrade performance. Too few ROS containers can prevent the system from taking advantage of inherent parallelism. Too many ROS containers can also result in Vertica errors.
For best performance:
- When not loading data, 10 containers per projection
- During data load, up to 20 containers per projection
- No more than 50 containers per projection
Using Linux to Monitor Resource Usage
Use the following Linux commands to monitor disk and resource usage:
df—Usedfto monitor the disk so that enough space remains available.vmstat—Usevmstatto monitor CPU usage at specified intervals. The column values bi (blocks in) and bo (blocks out), are reported in kilobytes per second.
The vmstat display also shows swapping I/O using columns si (swap in) and so (swap out), also in kilobytes per second.
vmstat estimates the disk bandwidth used in the load in kilobytes per second. The maximum values observed for the bi + bo columns provide the disk bandwidth estimate.
The vmstat display shows swapping I/O using columns si and so, for swap in and swap out, also in KB/sec. Suppose the swapping I/O is significant (si + so is more than 20% of maximum-seen bi + bo, thus stealing up to 20% of the disk bandwidth) over many minutes, especially during the high block I/O periods. In this situation, the system is under stress. The parallelism of the load should be reduced at the earliest opportunity by reducing the number of load streams after the COPY for a chunk is finished.
For example, suppose you run vmstat 60 to obtain a report every 60 seconds. During the load, you see high CPU usage in bursts for the sequence of memory sorts in the first part of chunk processing. During the rest of the process, you observe high block I/O (vmstat columns bi and bo). The system should not become idle until the load is done, where "idle" means low CPU use and low bi + bo.
You can also use sar and sar –r.
Data Type Mappings
PDI has the ability to generate Vertica DDL automatically when moving data from another database to a Vertica database. Make sure that you understand the differences between the two databases. For additional information, see Data Type Mapping.
Vertica and Oracle Data Type Mappings
Oracle uses proprietary data types for all common data types (for example, VARCHAR, INTEGER, FLOAT, and DATE). If you plan to migrate your database from Oracle to Vertica, convert the schema. Doing so is a simple and important exercise that can minimize errors and the time lost spent fixing erroneous data issues.
For information about the SQL data types that Vertica supports, see SQL Data Types in the product documentation. For example, if you are migrating from Oracle, you must convert the non-standard type named NUMBER to SQL-standard INT or INTEGER.
Using Non-ASCII Data
Vertica stores data in the UTF-8 compressed encoding of Unicode. The resulting UTF-8 codes are identical to ASCII codes for the ASCII characters (codes 0‒127 in one byte).
On most UNIX systems, use the locale command to see the current locale. You can change the locale for a session by setting the LANG environment variable to en_US.UTF-8.
For more information on Handling Non-UTF-8 Input, check this link.
Refer to this blog for more information about replacing non-UTF-8 Characters.
Enabling PDI Parallelization
All versions of PDI include the ability to run transformations in parallel. How it works depends on the format of the data source, as described in the following sections.
Parallelization When the Source is a Table
When the source is a table, implementing parallelism for the output can lead to a 30% performance boost. The following example shows how to use the Standard Table Output component. In this transformation, PDI parallelizes only the write operations.
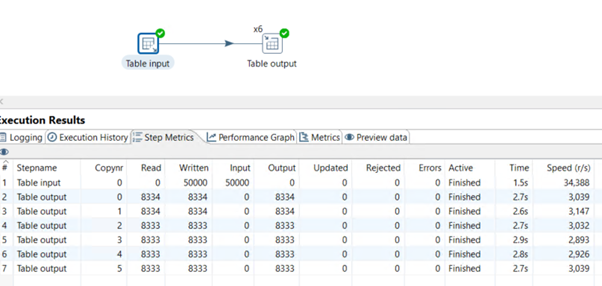
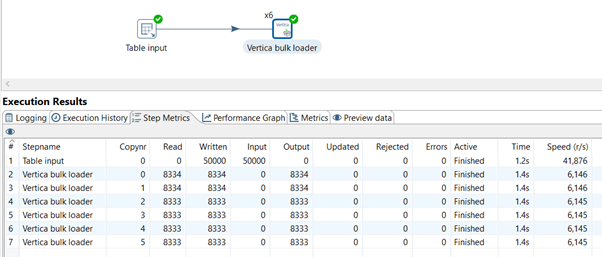
The next example shows how to use the Vertica Bulk Loader when the source is a table. For this transformation, PDI again only parallelizes the write operations.
In order to achieve better performance, implement faster input reads by introducing SELECT logic as follows:
- Take the original SELECT query.
- Add a WHERE clause to chunk the data.
In the following example, the Vertica Bulk Loader reads the data in six chunks. PDI provides variables (where mod(customer_key,${Internal.Step.Unique.Count}) = ${Internal.Step.Unique.Number}) that implement this chunking easily. The following figure shows an example.
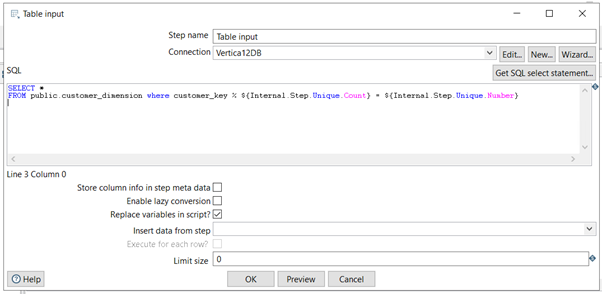
Note When PDI asks you to choose a split method, select Distribute Rows. If you are using the PDI Enterprise Edition, you can use Load Balancing instead.
This example shows the parallel queries to the source database that PDI generates. The WHERE clause defines the data chunking:
NEW:
SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 0; SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 1; SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 2; SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 3; SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 4; SELECT * FROM public.customer_dimension WHERE mod(c_custkey,6) = 5;
Note customer_key must be an integer and should be evenly distributed. If there are more keys that its mod is 3, the fourth copy will have more rows. The fourth copy will perform slower than the other copies.
Reducing Parallelism to Control I/O Swap
If the swapping I/O is significant, the system is under stress. (Use vmstat or iostat to capture the I/O.) Significant I/O swapping can occur when
si + so > 20% of maximum ‒ seen bi + bo
Thus, up to 20% of the disk bandwidth can take many minutes. This condition presents most often during the high block I/O periods.
In this situation, reduce the parallelism of the load, by reducing the number of load streams.
Using Row Buffers to Troubleshoot PDI
PDI creates a row buffer between each step. Steps retrieve rows of data from their inbound row buffer, process the rows, and pass them into an outbound row buffer that feeds into the subsequent step. By default, row buffers can hold up to 10,000 rows, but this value can be configured for each transformation.
When you run a transformation, the Step Metrics tab on the Execution Results pane shows real-time statistics for each step. The input/output field shows a real-time display of the number of rows in the buffers feeding into and coming out of each step. If the input buffer of a step is full, that step cannot keep up with the rows being fed into it.
Tracing
To allow tracing, follow this link to set the parameters:

