Vertica Integration with Denodo: Tips and Techniques
About Vertica Tips and Techniques
This document explores Vertica analytical database using the data federation tool Denodo. It provides technical details and examples that demonstrate how to implement cache and statistics with Vertica to efficiently manage resources and improve query performance and output. You can significantly boost query performance by using Vertica as cache for data stored in other databases as well. Various cache mechanisms and modes are explained in this guide in order to achieve optimal results.
The use cases were tested using Vertica 9.3.1 with Denodo 7.0.
Denodo Overview
Denodo is a data federation tool that lets you integrate data from different sources in real-time. Supported data sources include relational databases, web services, XML documents, spreadsheets, and flat files.
The Denodo Platform includes the following modules:
- Virtual DataPort — Executes the data federation, provides a JDBC and ODBC interface to run queries, and publishes views as SOAP and REST web services. The Virtual DataPort is the core of the Denodo Data Virtualization Platform.
- ITPilot — Extracts user-specified information from a website.
- Aracne — Web crawler that indexes user-specified text in a website.
- Scheduler — Schedules tasks in the Virtual DataPort, ITPilot, and Aracne modules.
The following diagram illustrates the basic architecture of the Denodo Platform:
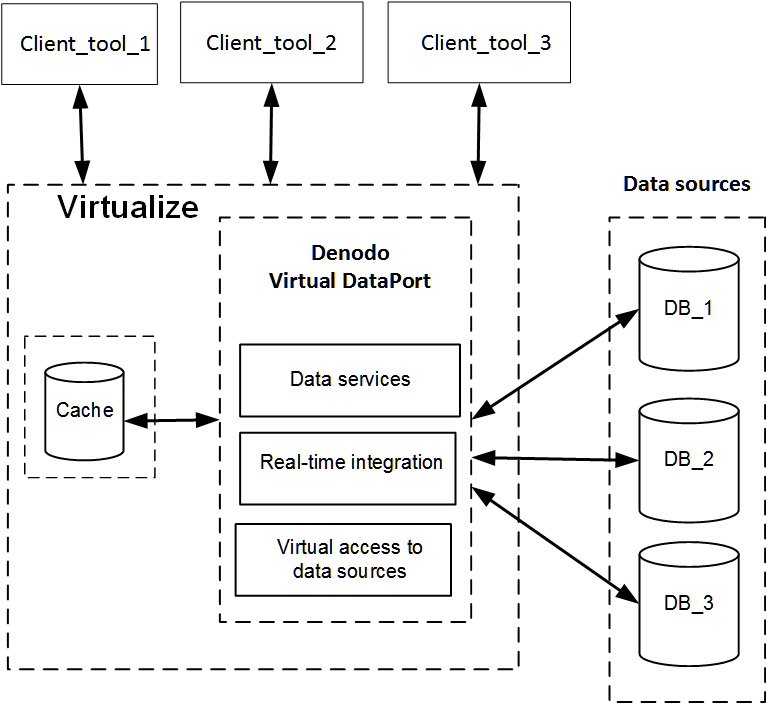
Note The Denodo Platform supports an optional cache that you can configure to store query results for faster retrieval.
Default Join Processing in Denodo
By default, Denodo executes SELECT statements in each data source and then performs joins and other connecting operations in the Denodo server without caching.
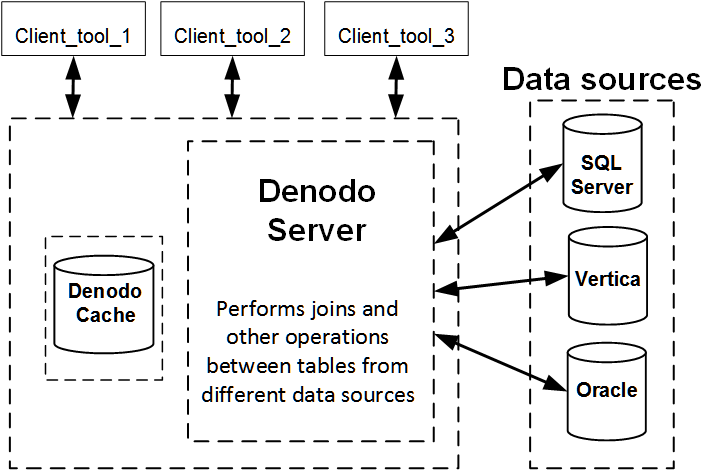
The Denodo server pushes down as much processing as it can to the data sources, but it still has to retrieve the data from these data sources and perform the join. Additionally, it does not have the processing speed or capacity of Vertica.
Recommendations for Using Vertica with Denodo
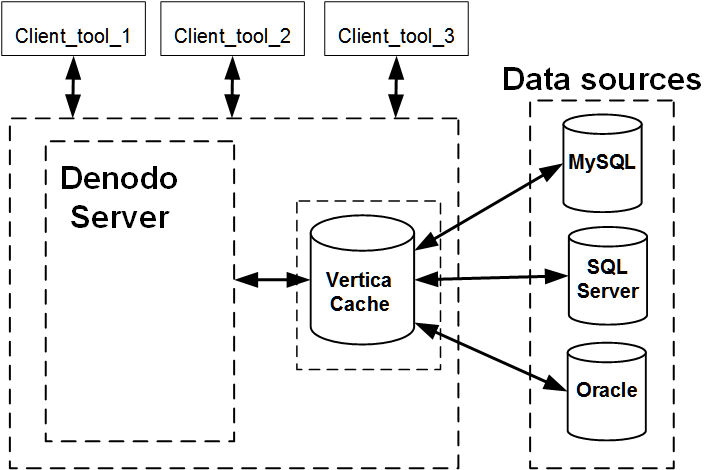
The process of joining columns from tables in different databases is the phase of data virtualization that places the most demand on system resources. Offloading join processing to Vertica can significantly improve query performance. The following section explains this process using Vertica as the Denodo Cache.
Using Vertica as the Denodo Cache
The Denodo cache contains views of the source data. When you select from cached views, Denodo creates copies of the source data in the cache and pushes the join processing into the cache database.
When Vertica is configured as the cache, the processing-intensive work of data virtualization is pushed into Vertica, where it can be performed quickly.
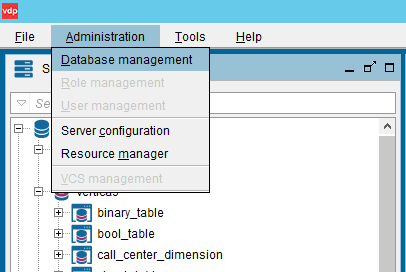
Enabling Vertica as Cache in Denodo
- In the Administration menu, click Database management.
- Click the Cache tab.
- Select Specify an existing data source as code and specify Vertica Database and Data source.
- Click Ok.

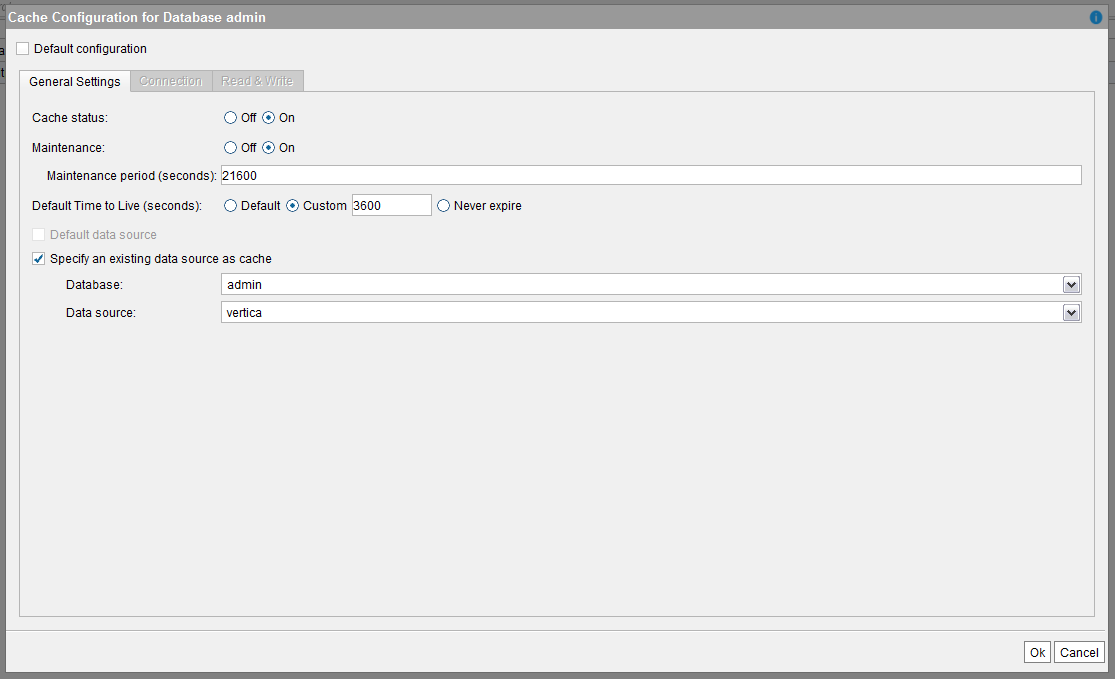
A message is displayed when the operation is successful.
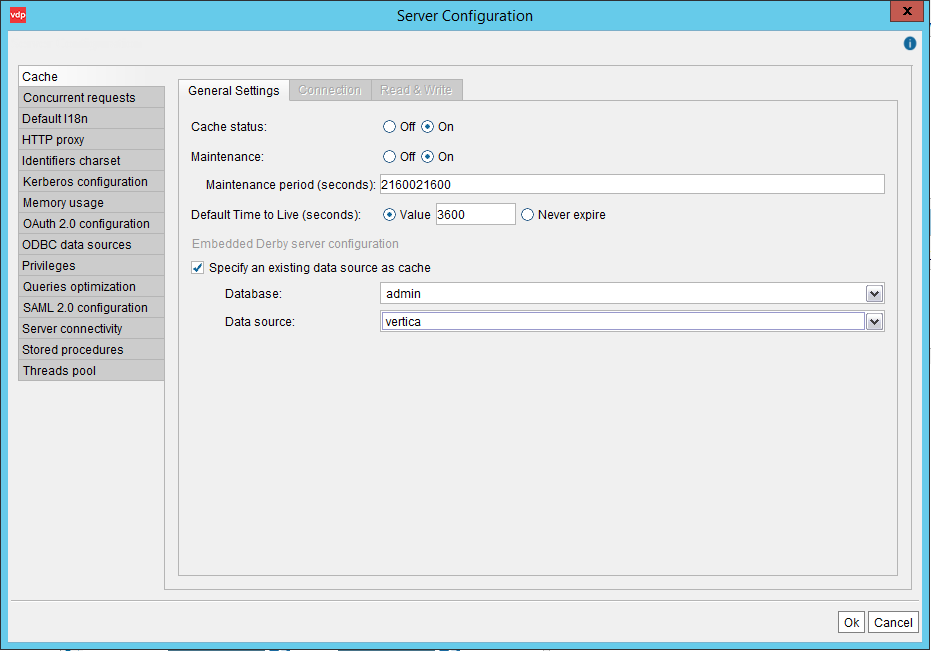
Vertica Cache Server Configuration
Cache options including general settings, connection, and read and write can be configured via Administration > Server configuration. You can turn cache status On or Off and also specify the Vertica database for Cache.
Example
Let's say you want to join the date dimension in SQL Server with the online_sales_fact and product dimension tables in Vertica while using Vertica as the cache.
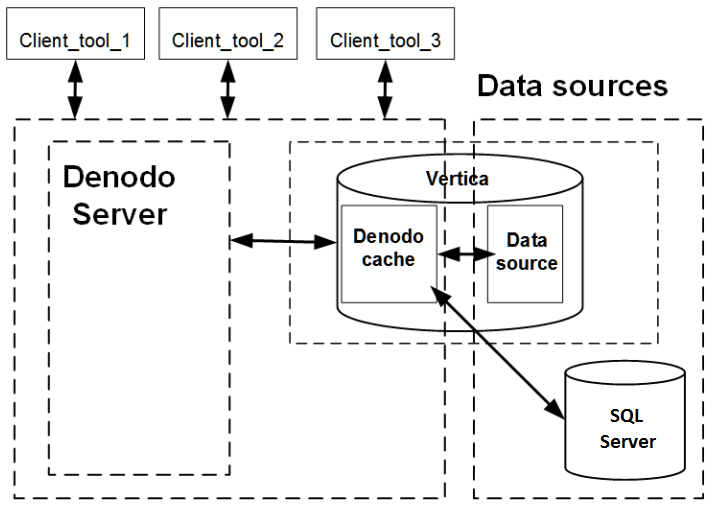
Assuming you already have a view in Denodo called date_dimension that maps to the date_dimension table in SQL Server, follow these steps:
- Create the base view of Vertica in the
vdpcachedatasourcedata source of the Denodoadmindatabase. -
In
vdpcachedatasource, create a view ofonline_sales_factandproduct dimensionin Vertica. -
Select Full: The cache will contain a complete copy of the data for the
date_dimensionview.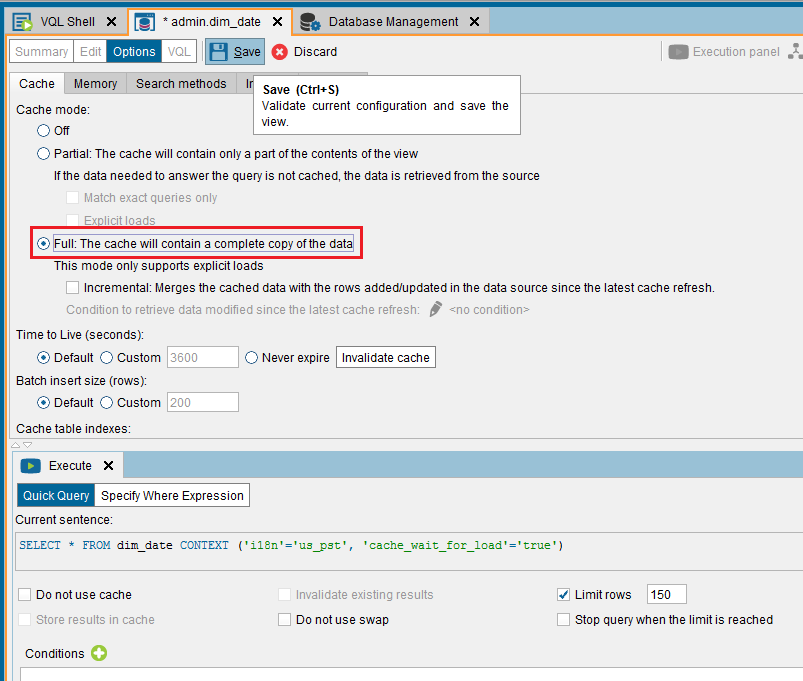
-
Execute a join of
online_sales_fact,product dimension, anddate_dimension.Following is the query that is executed:
SELECT a.category_description, co.calendar_year, SUM(c.sales_quantity)
FROM online_sales_fact
c LEFT OUTER JOIN product_dimension a
ON c.product_key =a.product_key and c.product_version=a.product_version
LEFT OUTER JOIN dim_date co
ON co.date_key=c.sale_date_key
GROUP BY a.category_description,co.calendar_year
ORDER BY a.category_description,co.calendar_year;Denodo pushes the join processing down to Vertica.
The query in the Vertica Log appears as follows:
'SELECT s0.category_description AS category_description, s0.calendar_year AS calendar_year, sum( s0.sales_quantity) AS sum_1 FROM (SELECT t1.category_description AS category_description, s1.calendar_year AS calendar_year, t0.sales_quantity AS sales_quantity FROM (VMart.online_sales.online_sales_fact t0 LEFT JOIN VMart."public".product_dimension t1 ON ((t0.product_key = t1.product_key AND t0.product_version = t1.product_version) )) LEFT JOIN (SELECT t2.date_key AS date_key, t2.calendar_year AS calendar_year FROM C_DIM_DATE17798148297808750356174133839326557512039817183621480622404904352621851432028563123404580760860407534475493356276195 t2 WHERE t2.rowStatus = 'V' AND (t2.expirationDate = 0 OR t2.expirationDate > 1540372198273)) s1 ON ((s1.date_key = t0.sale_date_key) )) s0 GROUP BY s0.category_description, s0.calendar_year ORDER BY category_description ASC, calendar_year ASC'
The query executed in the Denodo environment and its Execution Trace appears as follows:
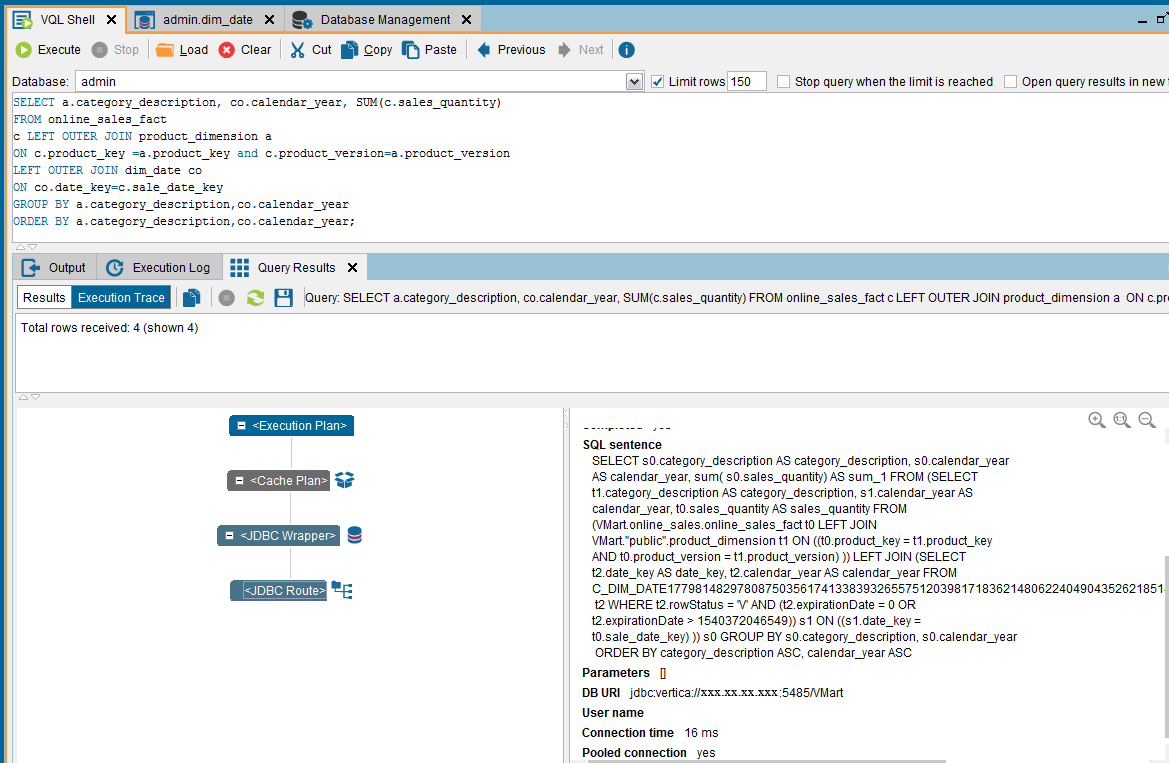
Following is the Execution Log in the Denodo environment:

Execute the same Query by selecting Partial Cache for dim_date. The Cache will contain only a part of the contents of the view.
The query in the Vertica Log appears as follows:
'UPDATE vdb_cache_querypattern SET qpStatus = 'V' WHERE queryPatternId = '6'::Integer'
'UPDATE vdb_cache_querypattern SET qpStatus = ? WHERE queryPatternId = ?' 848
'SELECT s0.category_description AS category_description, sum( s0.sales_quantity) AS sum_1, s0.sale_date_key AS sale_date_key FROM (SELECT t1.category_description AS category_description, t0.sale_date_key AS sale_date_key, t0.sales_quantity AS sales_quantity FROM VMart.online_sales.online_sales_fact t0 LEFT JOIN VMart."public".product_dimension t1 ON ((t0.product_key = t1.product_key AND t0.product_version = t1.product_version) )) s0 GROUP BY s0.category_description, s0.sale_date_key ORDER BY sale_date_key DESC' 849
The query executed in the Denodo environment and its Execution Trace appears as follows:
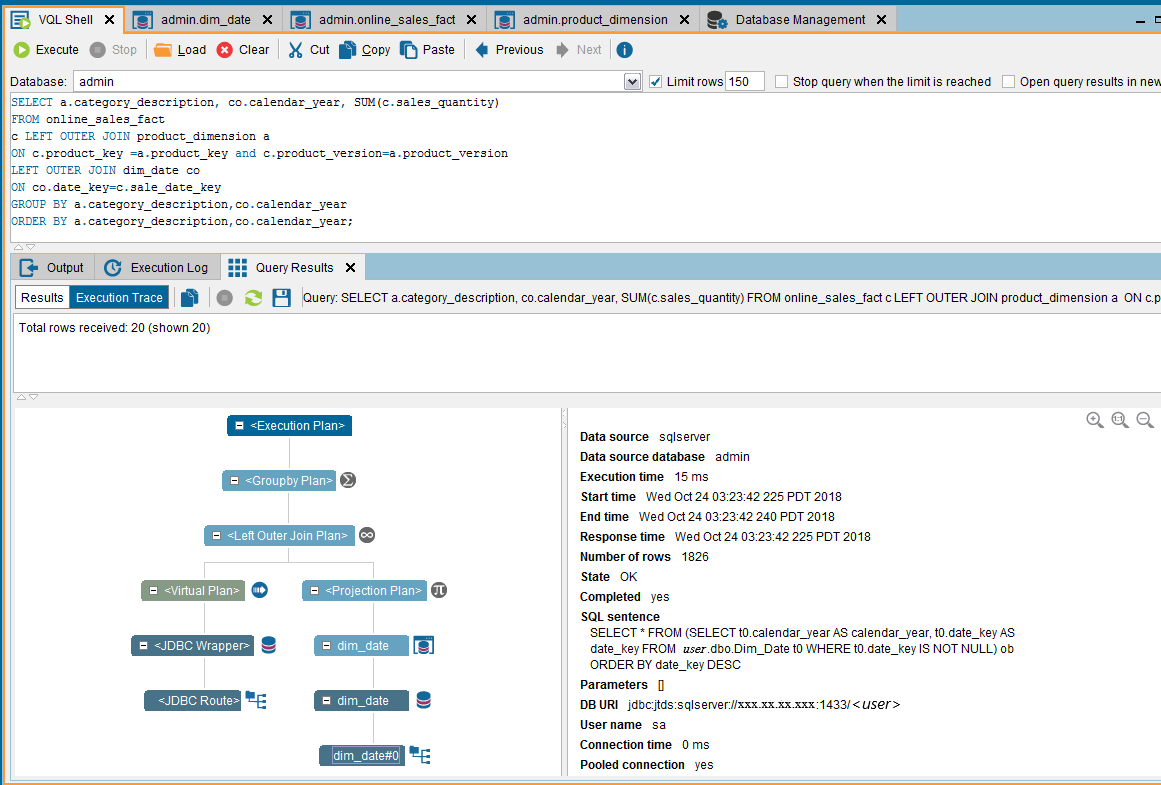
Following is the Execution Log in the Denodo environment:

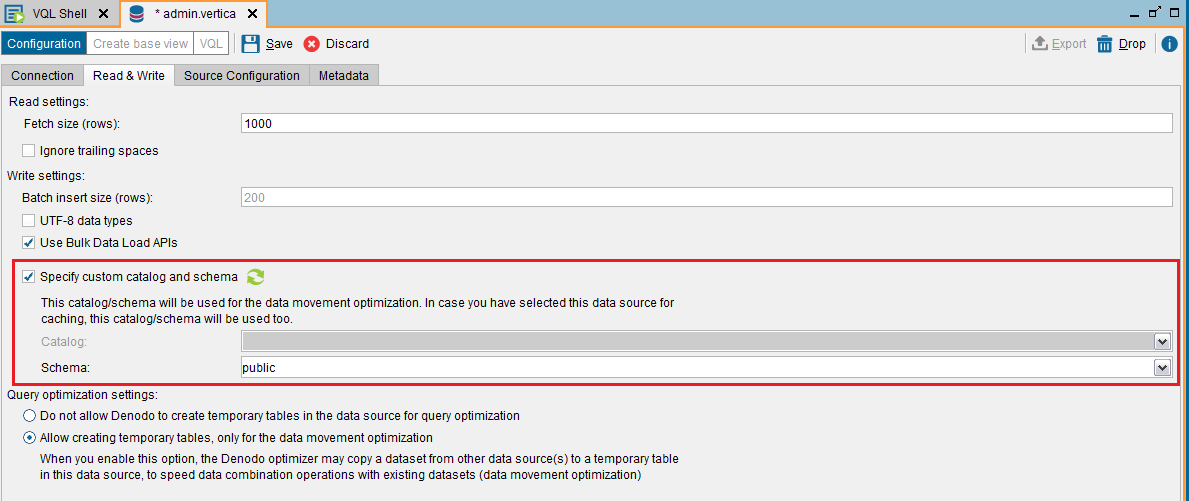
Specify custom catalog and schema Option
In Denodo 7.0, the Specify custom catalog and schema option enables you to optimize data movement. This is also used when you select your Vertica database for caching.
Use Case: Vertica as Cache with Update
When you use Vertica as the cache, you must explicitly load the cache in full mode. To ensure data consistency, you must set cache_invalidate to matching_rows. When these settings are used together, Vertica performs updates during the cache load.
fullmode — Caching infullmode means that the data in the view is always retrieved from the cache engine instead of from the source. This mode always requires explicit cache loads.cache_invalidatesetting — When set tomatching_rows, Denodo invalidates any row that matches the WHERE condition of the query before loading new data. If the query does not have a WHERE clause, it invalidates all the rows.
An alternative iscache_invalidate=all_rows. This setting invalidates all the rows regardless of the WHERE clause of the query.- Denodo refreshes the cache by invalidating any row for which new data exists before loading the new data. Thus each row of data in the cache is an exact duplicate of the corresponding row in the data source.
For this example, you would load the date dimension from SQL Server into the Vertica cache as follows:
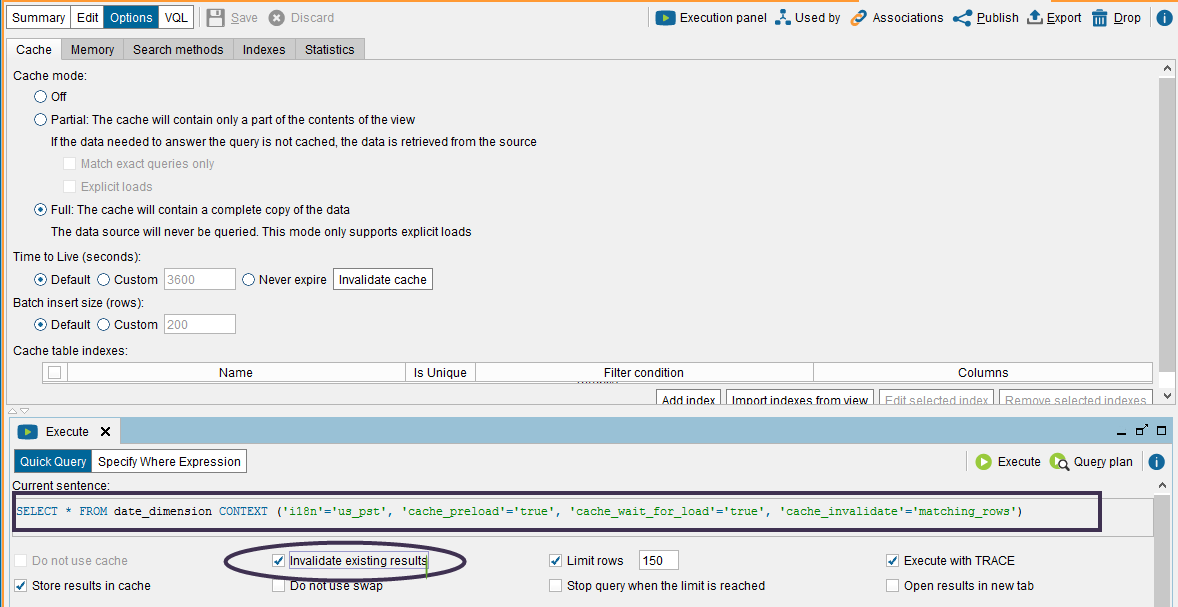
When this query loads the cache, Denodo stores the rows with status Processing and later changes the status to Valid. This indicates that Vertica executed updates during the load. The updates have a negative impact on performance.
The Vertica log shows the updates:
UPDATE C_DATE_DIMENSION SET rowStatus = 'I3' , expirationDate = '1490261596508'::Integer WHERE rowStatus = 'V'' UPDATE C_DATE_DIMENSION SET expirationDate = '1490265196102'::Integer ,rowStatus = 'V' WHERE rowStatus = 'P2'
Use Case: Vertica as Cache with No Update
Due to the impact of Vertica update operations on cache load performance, Vertica recommends setting cache_atomic_operation to false. This setting prevents Denodo from saving rows with status Processing before saving them as Valid and thus prevents any updates.

Following is the query for better performance when loading the cache:
SELECT * FROM date_dimension CONTEXT ( 'cache_preload'='true' , 'cache_invalidate'='matching_rows' , 'cache_wait_for_load'='true' , 'cache_atomic_operation'='false' , 'cache_return_query_results'='false');
With the parameter cache_return_query_results=false, the query does not return the result of the query to the client; it just stores the result in the cache database. This makes the query much faster and the memory footprint is also much lower.
The Vertica log is as follows:
INSERT INTO C_CHAR1_TABLE (datatypeset, valuedesc, char1_column, expirationDate, rowStatus) VALUES ( ? , ? , ? , ? , ?)'
However, the performance gain would be offset by possible inconsistency in the data. There is no way to invalidate existing records and ensure data consistency in the cache while also benefiting from the high performance capabilities of Vertica.
Use Case: Vertica as Cache for Other Data Sources
You can boost query performance by using Vertica as the cache even if you do not have any data stored in Vertica. For example, let's say your data is stored in MySQL, SQL Server, and Oracle and your queries are running too slow. You could speed things up by deploying Vertica as the cache.
For more information on using Vertica as cache, see Enabling Vertica as Cache in Denodo