




Vertica Integration with Denodo: Connection Guide
About Vertica Connection Guides
Vertica connection guides provide basic instructions for connecting a third-party partner product to Vertica. Connection guides are based on our testing with specific versions of Vertica and the partner product.
Vertica and Denodo: Latest Versions Tested
| Software | Version |
|---|---|
|
Denodo |
Denodo 7.0 |
| Client Platform |
Windows Server 2016 |
| Vertica Client |
Vertica JDBC 9.3.1 |
| Vertica Server |
Vertica Analytic Database 9.3.1 |
Denodo Overview
Denodo is a data federation tool that lets you integrate data from different sources in real-time. Supported data sources include relational databases, web services, XML documents, spreadsheets, and flat files.
The Denodo Platform includes the following modules:
- Virtual DataPort — Executes the data federation, provides a JDBC and ODBC interface to run queries, and publishes views as SOAP and REST web services. The Virtual DataPort is the core of the Denodo Data Virtualization Platform.
- ITPilot — Extracts user-specified information from a website.
- Aracne — Web crawler that indexes user-specified text in a website.
- Scheduler — Schedules tasks in the Virtual DataPort, ITPilot, and Aracne modules.
Installing Denodo
To install Denodo
-
Follow the installation steps in the Denodo Platform 7.0 Installation Guide.
Note Ensure that you follow all the steps for configuring the Virtual DataPort module.
- When Denodo installation is complete, install the latest update.
Installing the Vertica Client Driver
Prerequisites
Before you install the Vertica client driver, verify that your client system meets the following requirements.
| Requirement | Description |
|---|---|
| Operating system |
For the list of supported platforms, see Vertica Client Drivers in the Vertica documentation. |
| UTF-8, UTF-16, and UTF-32 support |
Configure the driver to use the required encoding method. This encoding allows strings to be passed between the driver and the application without intermediate conversion. |
Installing the JDBC Driver on Windows
Denodo uses the Vertica JDBC driver to connect to Vertica. To install the client driver
- Navigate to the Vertica Client Drivers page.
-
Download the JDBC driver package for your version of Vertica.
Note For more information about client and server compatibility, see Client Driver and Server Version Compatibility in the Vertica documentation.
-
Follow the instructions in Installing the JDBC Client Driver for Windows in the Vertica documentation.
Connecting Vertica to Denodo
To connect your Vertica database to Denodo
- Create a JDBC data source for Vertica.
- Create base views that represent your Vertica tables.
Creating a JDBC Data Source
To create a JDBC data source
- Go to the DENODO_HOME\bin directory.
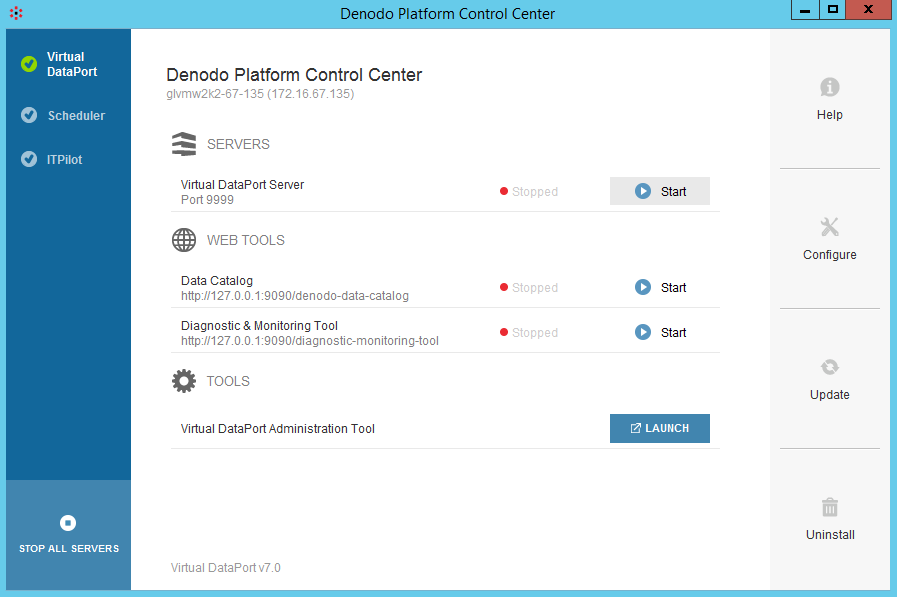
- To start Denodo, double-click
denodo_platform.exe. - In Denodo Platform Control Center, click Virtual DataPort, and then click Start.
- Click Launch.
- Log in to the Denodo Platform using the default credentials:
- User name: admin
- Password: admin
- Select File > New > Data source > JDBC.
- In the Create New JDBC Data Source dialog box, click the Connection tab.
- Type the connection details for your Vertica database.
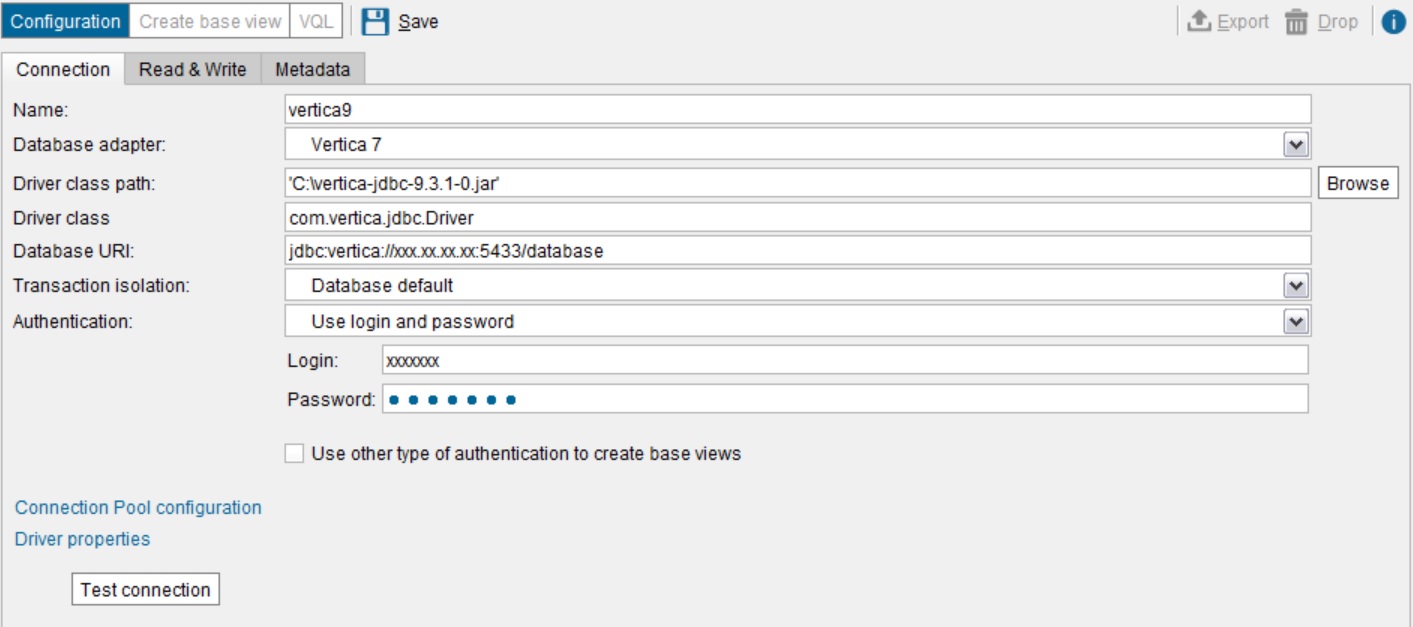
- Click Test connection.
If the connection information is correct, a list of schemas in your Vertica database is displayed.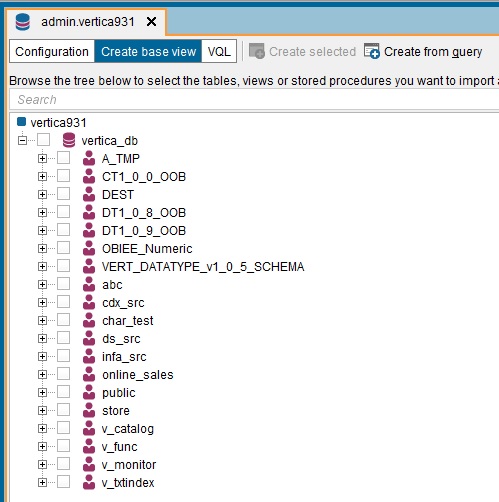
Creating a Base View
After you create the JDBC data source, to create a base view of the data you want to query
- Click the plus sign (+) to expand the schema that contains the tables.
-
Select the tables.
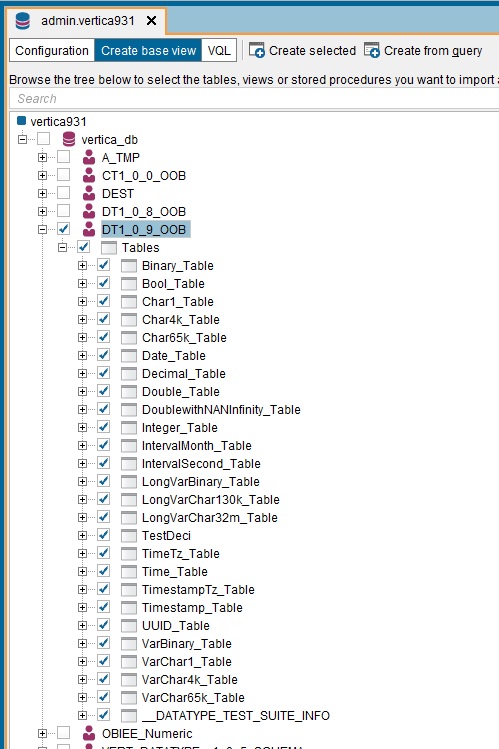
- Select Create selected base views.
After several seconds, a list of views is displayed.
Querying a Base View
To query a base view
- Right-click the base view name and click Execute.
- If you want to add conditions to the query, edit the SELECT statement.
-
Click Execute to execute the query.

Accessing Views from a JDBC Client
For information about working with views in Denodo, see the Denodo Virtual DataPort Developer Guide.
Known Limitations
- Denodo does not recognize schema organization in the source. If you have two tables with the same name in different schemas in Vertica, you must rename one of the views in Denodo to include both the schemas in a Denodo view.
- Timestamp, TimestampTz, and TimeTz data types are converted based on the server time zone and milliseconds are not supported.
- For Time and IntervalSecond data types, milliseconds are rounded off.

