Vertica Architecture Basics
There are several key concepts at the core of the Vertica architecture that you should understand, which are explained the the following sections.
Column Storage
Vertica stores data in a column format so it can be queried for best performance. Compared to row-based storage, column storage reduces disk I/O making it ideal for read-intensive workloads. Vertica reads only the columns needed to answer the query. For example:
=> SELECT avg(price) FROM tickstore WHERE symbol = 'AAPL' and date = '5/31/13';
For this example query, a column store reads only three columns while a row store reads all columns:

Data Encoding and Compression
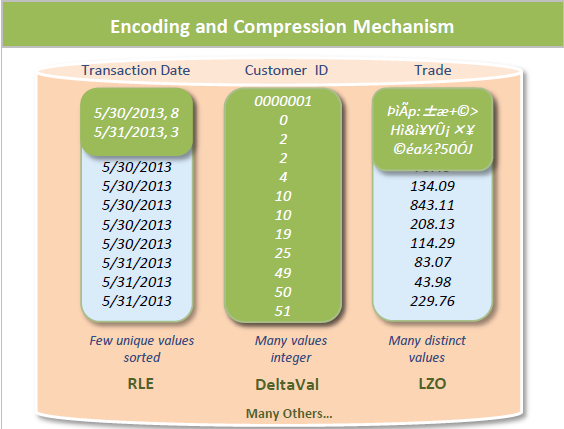
Vertica uses encoding and compression to optimize query performance and save storage space.
Encoding
Encoding converts data into a standard format. Vertica uses a number of different encoding strategies, depending on column data type, table cardinality, and sort order. Encoding increases performance because there is less disk I/O during query execution. In addition, you can store more data in less space.
Run the Database Designer for optimal encoding in your physical schema. The Database Designer analyzes the data in each column and recommends encoding types for each column in the proposed projections, depending on your design optimization objective. For flex tables, Database Designer recommends the best encoding types for any materialized flex table columns, but not for __raw__ column projections.
Compression
Using compression, Vertica stores more data, provides more views, and uses less hardware than other databases. Vertica uses several different compression methods and automatically chooses the best one for the data being compressed.
Compression allows a column store to occupy substantially less storage than a row store. In a column store, every value stored in a projection column has the same data type. This greatly facilitates compression, particularly in sorted columns. In a row store, each value of a row can have a different data type, resulting in a much less effective use of compression. The efficient storage methods that Vertica uses for your database also lets you maintain more historical data in physical storage.
The following shows compression using sorting and cardinality:
Clustering
Clustering supports scaling and redundancy. You can scale your database cluster by adding more nodes, and you can improve reliability by distributing and replicating data across your cluster.
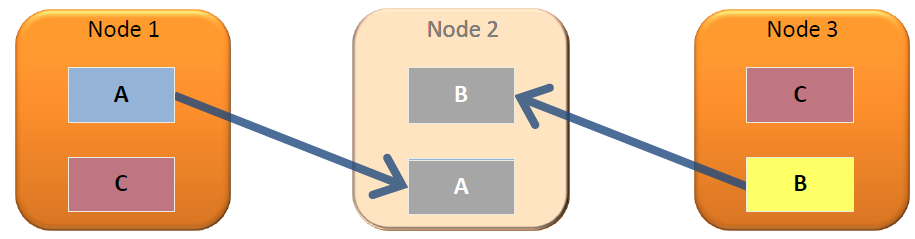
Column data gets distributed across nodes in a cluster, so if one node becomes unavailable the database continues to operate. When a node is added to the cluster, or comes back online after being unavailable, it automatically queries other nodes to update its local data.
Projections
A projection consists of a set of columns with the same sort order, defined by a column to sort by or a sequence of columns by which to sort. Like an index or materialized view in a traditional database, a projection accelerates query processing. When you write queries in terms of the original tables, the query uses the projections to return query results.
Projections are distributed and replicated across nodes in your cluster, ensuring that if one node becomes unavailable, another copy of the data remains available. For more information, see K-Safety in an Enterprise Mode Database.
Automatic data replication, failover, and recovery provide for active redundancy, which increases performance. Nodes recover automatically by querying the system.
Logical and Physical Schema
Vertica stores information about database objects in the logical schema and the physical schema. The difference between the two schemas and how they relate to data storage is an important and unique aspect of the Vertica architecture.
A logical schema consists of objects such as tables, constraints, and views. Vertica supports any relational schema design that you choose. A physical schema consists of collections of table columns called projections. A projection can contain some or all of the columns of a table.
Continuous Performance
Vertica queries and loads data continuously 24x7.
Concurrent loading and querying provides real-time views and eliminates the need for nightly load windows. On-the-fly schema changes allow you to add columns and projections without shutting down your database; Vertica manages updates while keeping the database available.
Terminology
It is helpful to understand the following terms when using Vertica:
Host
A computer system with a 64-bit Intel or AMD processor, RAM, hard disk, and TCP/IP network interface (IP address and hostname). Hosts share neither disk space nor main memory with each other.
Instance
An instance of Vertica consists of the running Vertica process and disk storage (catalog and data) on a host. Only one instance of Vertica can be running on a host at any time.
Node
A host configured to run an instance of Vertica. It is a member of the database cluster. For a database to have the ability to recover from the failure of a node requires a database K-safety value of at least 1 (3+ nodes).
Cluster
The concept of Cluster in the Vertica Analytics Platform is a collection of hosts with the Vertica software packages (RPM or DEB) that are in one admin tools domain. You can access and manage a cluster from one admintools initiator host.
Database
A cluster of nodes that, when active, can perform distributed data storage and SQL statement execution through administrative, interactive, and programmatic user interfaces.
Although you can define more than one database on a cluster, Vertica supports running only one database per cluster at a time.