Choosing a Frame Duration
One key setting for your scheduler is its frame duration. The duration sets the amount of time the scheduler has to run all of the microbatches you have defined for it. This setting has significant impact on how data is loaded from Apache Kafka.
What Happens During Each Frame
To understand the right frame duration, you first need to understand what happens during each frame.
The frame duration is split among the microbatches you add to your scheduler. In addition, there is some overhead in each frame that takes some time away from processing the microbatches. Within each microbatch, there is also some overhead which reduces the time the microbatch spends loading data from Kafka. The following diagram shows roughly how each frame is divided:
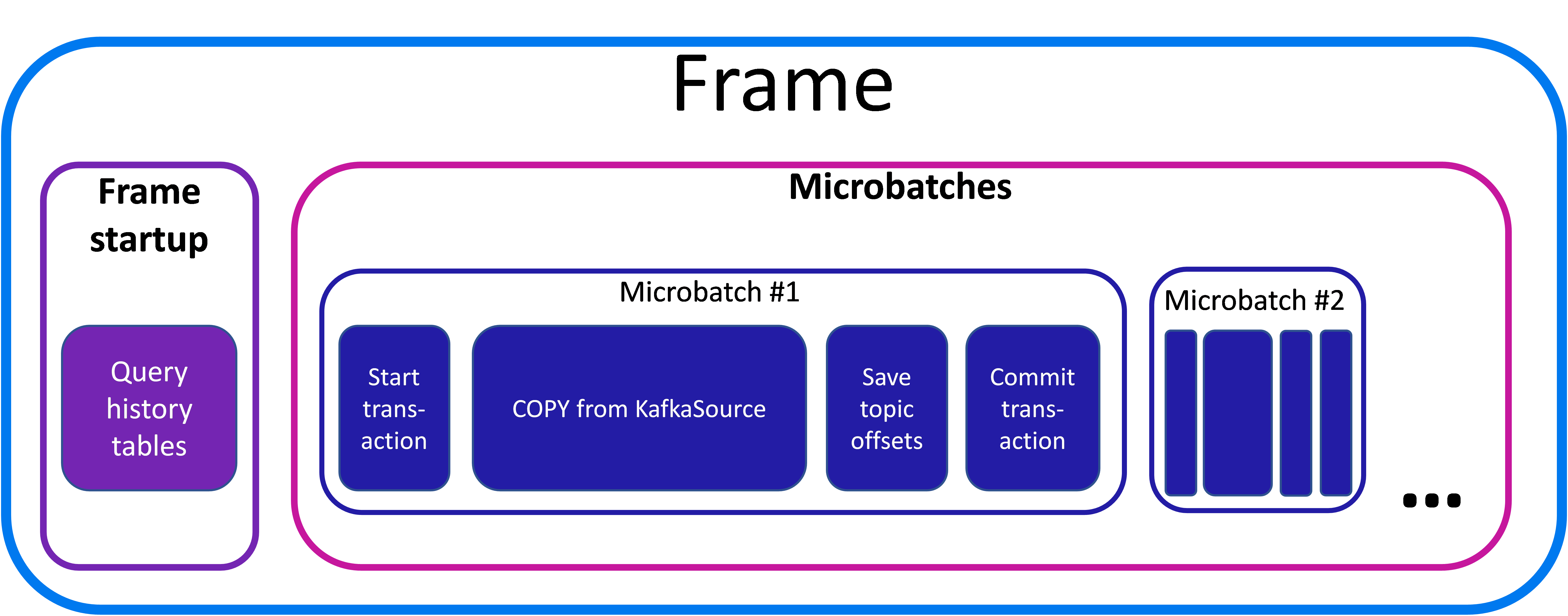
As you can see, only a portion of the time in the frame is spent actually loading the streaming data.
How the Scheduler Prioritizes Microbatches
To start with, the scheduler evenly divides the time in the frame among the microbatches. It then runs each microbatch in turn.
In each microbatch, the bulk of the time is dedicated to loading data using a COPY statement. This statement loads data using the KafkaSource UDL. It runs until one of two conditions occurs:
- It reaches the ends of the data streams for the topics and partitions you defined for the microbatch. In this case, the microbatch completes processing early.
- It reaches a timeout set by the scheduler.
As the scheduler processes frames, it notes which microbatches finish early. It then schedules them to run first in the next frame. Arranging the microbatches in this manner lets the scheduler allocate more of the time in the frame to the microbatches that are spending the most time loading data (and perhaps have not had enough time to reach the end of their data streams).
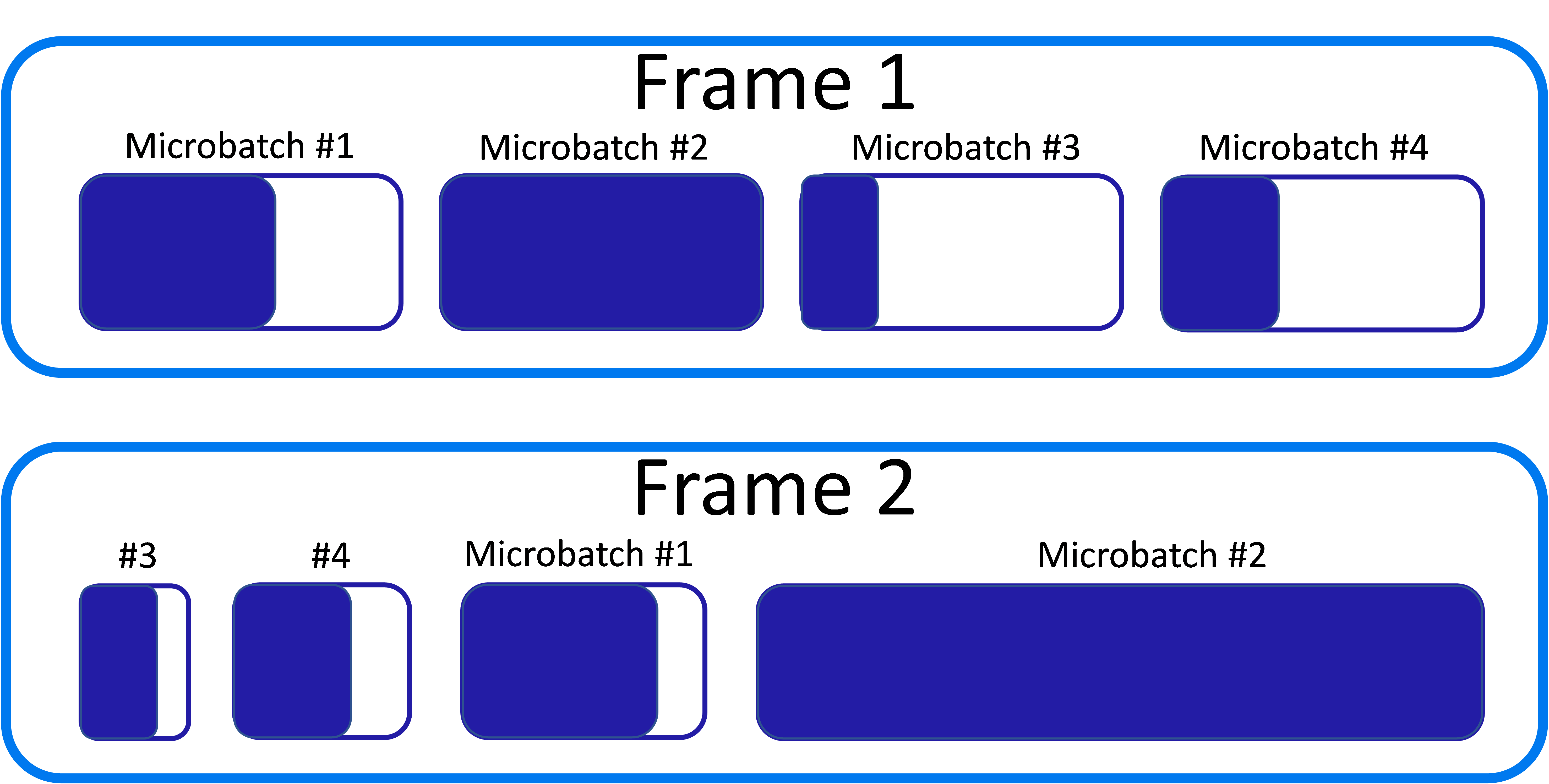
For example, consider the following diagram. During the first frame, the scheduler evenly divides the time between the microbatches. Microbatch #2 uses all of the time allocated to it (as indicated by the filled-in area), while the other microbatches do not. In the next frame, the scheduler rearranges the microbatches so that microbatches that finished early go first. It also allocates less time to the microbatches that ran for a shorter period. Assuming these microbatches finish early again, the scheduler is able to give the rest of the time in the frame to microbatch #2. This shifting of priorities continues while the scheduler runs. If one topic sees a spike in traffic, the scheduler compensates by giving the microbatch reading from that topic more time.
What Happens if the Frame Duration is Too Short
If you make the scheduler's frame duration too short, microbatches may not have enough time to load all of the data in the data streams they are responsible for reading. In the worst case, a microbatch could fall further behind when reading a high-volume topic during each frame. If left unaddressed, this issue could result in messages never being loaded, as they age out of the data stream before the microbatch has a chance to read them.
In extreme cases, the scheduler may not be able to run each microbatch during each frame. This problem can occur if the frame duration is so short that much of is spent in overhead tasks such committing data and preparing to run microbatches. The COPY statement that each microbatch runs to load data from Kafka has a minimum duration of 1 second. Add to this the overhead of processing data loads. In general, if the frame duration is shorter than 2 seconds times the number of microbatches in the scheduler, then some microbatches may not get a chance to run in each frame.
If the scheduler runs out of time during a frame to run each microbatch, it compensates during the next frame by giving priority to the microbatches that didn't run in the prior frame. This strategy makes sure each microbatch gets a chance to load data. However, it cannot address the root cause of the problem. Your best solution is to increase the frame duration to give each microbatch enough time to load data during each frame.
What Happens if the Frame Duration is Too Long
One downside of a long frame duration is increased data latency. This latency is the time between when Kafka sends data out and when that data becomes available for queries in your database. A longer frame duration means that there is more time between each execution of a microbatch. That translates into more time between the data in your database being updated.
Depending on your application, this latency may not be important. When determining your frame duration, consider whether having the data potentially delayed up to the entire length of the frame duration will cause an issue.
Another issue to consider when using a long frame duration is the time it takes to shut down the scheduler. The scheduler does not shut down until the current COPY statement completes. Depending on the length of your frame duration, this process might take a few minutes.
The Minimum Frame Duration
At a minimum, allocate two seconds for each microbatch you add to your scheduler. The vkconfig utility warns you if your frame duration is shorter than this lower limit. In most cases, you want your frame duration to be longer. Two seconds per microbatch leaves little time for data to actually load.
Balancing Frame Duration Requirements
To determine the best frame duration for your deployment, consider how sensitive you are to data latency. If you are not performing time-sensitive queries against the data streaming in from Kafka, you can afford to have the default 5 minute or even longer frame duration. If you need a shorter data latency, then consider the volume of data being read from Kafka. High volumes of data, or data that has significant spikes in traffic can cause problems if you have a short frame duration.
Using Different Schedulers for Different Needs
Suppose you are loading streaming data from a few Kafka topics that you want to query with low latency and other topics that have a high volume but which you can afford more latency. Choosing a "middle of the road" frame duration in this situation may not meet either need. A better solution is to use multiple schedulers: create one scheduler with a shorter frame duration that reads just the topics that you need to query with low latency. Then create another scheduler that has a longer frame duration to load data from the high-volume topics.
For example, suppose you are loading streaming data from an Internet of Things (IOT) sensor network via Kafka into Vertica. You use the most of this data to periodically generate reports and update dashboard displays. Neither of these use cases are particularly time sensitive. However, three of the topics you are loading from do contain time-sensitive data (system failures, intrusion detection, and loss of connectivity) that must trigger immediate alerts.
In this case, you can create one scheduler with a frame duration of 5 minutes or more to read most of the topics that contain the non-critical data. Then create a second scheduler with a frame duration of at least 6 seconds (but preferably longer) that loads just the data from the three time-sensitive topics. The volume of data in these topics is hopefully low enough that having a short frame duration will not cause problems.