




Vertica and Delta Lake: Technical Exploration
About this Document
This document explores the integration of Vertica and Delta Lake using external tables. Delta Lake is a service in Apache Spark that provides ACID transactions to your data lakes. This document details the steps you need to perform to write data to Vertica via Delta Lake and S3. For testing purposes, we used Minio as an S3 bucket.
Delta Lake Overview
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on your existing data lake and is fully compatible with Apache Spark APIs.
Prerequisites
- Apache Spark environment. We tested using a 4 node cluster with one Master and three Workers. Follow the instructions in Set up Apache Spark on a Multi-Node Cluster to install a multi-node spark environment. Start Spark multi-node cluster.
- Vertica Analytical Database. We tested using Vertica 10.0.
- AWS S3 or S3 compatible object store. We tested using MinIO as an S3 bucket.
-
The following jar files are required. You can copy the jars in any required location on the Spark machine. We placed these jar files at /home/spark.
- Vertica - vertica-spark2.1_scala2.11.jar
- Hadoop - hadoop-aws-2.6.5.jar
- AWS - aws-java-sdk-1.7.4.jar
-
Run the following commands in the Vertica database to set S3 parameters for accessing the bucket:
SELECT SET_CONFIG_PARAMETER('AWSAuth', 'accesskey:secretkey');SELECT SET_CONFIG_PARAMETER('AWSRegion','us-east-1');SELECT SET_CONFIG_PARAMETER('AWSEndpoint',’<S3_IP>:9000');SELECT SET_CONFIG_PARAMETER('AWSEnableHttps','0');Note Your endpoint value may differ depending on the S3 object storage you have chosen for your S3 bucket location.
Vertica and Delta Lake Integration
To integrate Vertica with Delta Lake, you need to first integrate Apache Spark with Delta Lake, configure the jars, and the connection to access AWS S3. Second, connect Vertica to Delta Lake. Then, perform operations such as Insert, Append, Update, or Delete on the S3 bucket.
Follow the steps in the following sections to write data to Vertica.
Configuring Delta Lake and AWS S3 on Apache Spark
-
Run the following commands in the Apache Spark machine.
This downloads the Delta Lake package, configures the jar files, and AWS S3:
./bin/spark-shell \
--packages io.delta:delta-core_2.11:0.6.1 \
--jars /<JAR_LOC>/vertica-spark2.1_scala2.11.jar,/ <JAR_LOC>//vertica-jdbc.jar,/ <JAR_LOC>/hadoop-aws-2.6.5.jar,/ <JAR_LOC>//aws-java-sdk-1.7.4.jar \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore \
--conf spark.hadoop.fs.s3a.endpoint=http://<S3_IP>:9000 \
--conf spark.hadoop.fs.s3a.access.key=accesskey\
--conf spark.hadoop.fs.s3a.secret.key= secretkey\
-
Preparing the Data
-
Create sample data in Apache Spark using Scala:
val df = Seq(
(1,"notebook","2019-01-01 00:00:00"),
(2,"laptop", "2019-01-10 13:00:00"),
(3,"small_phone", "2019-01-15 12:00:00"),
(4,"big_phone", "2019-01-30 09:30:00"),
(5,"kitkat", "2019-04-25 07:30:00")
).toDF("id", "device", "purchase_time") -
Change the data type accordingly. In this example, we changed it from String to Timestamp to make best use of the partitioning concept in Delta Lake.
val df2 = df.withColumn("purchase_time",to_timestamp($"purchase_time"))
-
-
Writing Data to AWS S3 and Verifying this Data
-
Run the following command using Scala to write data from Apache Spark to a Delta table on AWS S3:
df2.write.format("delta").mode("overwrite").partitionBy("purchase_time").save("s3a://delta-test/delta_test_table")
Note The partition naming "purchase_time=*" is required because Delta Lake creates other folders in the table directory. Therefore an all-encompassing wildcard (*) won't do as it would cause errors on read. Hence, "purchase_time=*".
-
Run the following command using Scala to verify that data is read correctly from the S3 bucket.
val df = spark.read.format("delta").load("s3a://delta-test/delta_test_table")df.show()
-
Configuring Vertica and Delta Lake Integration
Before you begin to integrate with Vertica, you need to generate a Manifest file in AWS S3. A manifest file is a text file which contains a list of data files (Parquet files) to read for querying. The files in this directory contain the names of the data files (Parquet files) that should be read for a snapshot of the Delta table.
-
To generate the manifest file in AWS S3
Run the following commands in the Apache Spark machine using Scala:
import io.delta.tables._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")deltaTable.generate("symlink_format_manifest")The manifest files are generated in the following directory:
path/to/delta/tablename/_symlink_format_manifest/
-
Create an external table in Vertica which contains data from the Delta table on AWS S3. We created the table “delta_test_table_date”:
Note Ensure that the table you are creating does not already exist.
CREATE EXTERNAL TABLE delta_test_table_data (
id INT,
device VARCHAR,
purchase_time TIMESTAMPTZ,
parquet_filename VARCHAR
)
AS COPY (id, device, purchase_time, parquet_filename AS current_load_source())
FROM 's3://delta-test/delta_test_table/purchase_time=*/*'
PARQUET(hive_partition_cols='purchase_time');
Note The “current_load_source()”function gets the filename from where the record is coming. This is needed for parsing the Delta Table's manifests and finding all parquet files that are necessary.
-
Run the following command to verify the external table is being read:

-
Define another external table in Vertica to access the latest changes to the original data you loaded:
DROP TABLE delta_test_table_manifest;
CREATE EXTERNAL TABLE delta_test_table_manifest (filename varchar) AS COPY (col FILLER VARCHAR(700), filename AS substr(col,instr(col,'/',-1)+1)) FROM 's3://delta-test/delta_test_table/_symlink_format_manifest/*/*';
-
Create a view to get the latest data (joining both the external tables):
CREATE OR REPLACE VIEW delta_test_table AS SELECT id, device, purchase_time FROM delta_test_table_data WHERE parquet_filename IN (SELECT filename FROM delta_test_table_manifest);
Note After the ETL process completes, you need to drop the _symlink_format_manifest directory and regenerate the manifest files again in the Apache Spark machine:
import io.delta.tables._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")deltaTable.generate("symlink_format_manifest")
How to Get Vertica to See Changed Data
The following sections contain samples of some operations that we performed to view the changed data in Vertica.
Appending Data
-
In this example, we ran the following commands in the Apache Spark machine using Scala and appended some data:
val df = Seq(
(6,"notebook2","2019-01-01 00:00:00"),
(7,"laptop2", "2019-01-12 13:00:00"),
(8,"small_phone2", "2019-01-17 12:00:00"),
(9,"big_phone2", "2019-01-30 09:30:00"),
(10,"kitkat2", "2019-04-25 07:30:00")
).toDF("id", "device", "purchase_time") -
Run the following commands to append this data to the Delta table on AWS S3:
val df2 = df.withColumn("purchase_time",to_timestamp($"purchase_time"))df2.write.format("delta").mode("append").save("s3a://delta-test/delta_test_table") -
Regenerate the manifests to view the new changes in Vertica.
deltaTable.generate("symlink_format_manifest")deltaTable.toDF.show()
Updating Data
-
In the following example, we updated all records of the Delta table including the id. To update the records, you need to first import the data into Apache Spark and then update.
import io.delta.tables._
import org.apache.spark.sql.functions._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")deltaTable.update(
condition = expr("id % 2 == 0"),set = Map("id" -> expr("id + 100")))deltaTable.toDF.show()
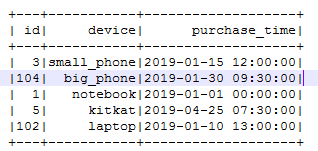
-
The Delta table is updated but if you query the table in Vertica, old records are still shown as the manifest is not updated yet.
Regenerate the manifest to get the updated records.
deltaTable.generate("symlink_format_manifest")
Deleting Data
-
Run the following commands to delete all records of the Delta table including the id and regenerate the manifest.
import io.delta.tables._
import org.apache.spark.sql.functions._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")deltaTable.delete(condition = expr("id % 2 == 0"))deltaTable.generate("symlink_format_manifest")deltaTable.toDF.show()
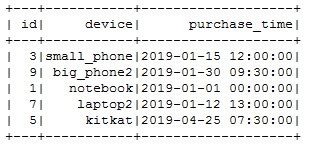
-
When you query the data in Vertica, the data seems inconsistent.

-
Regenerating the manifest does not delete the old manifest but updates the existing one. You must delete _symlink_format_manifest directory in the AWS S3 Delta table and then regenerate the manifest.
import io.delta.tables._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")deltaTable.generate("symlink_format_manifest")

