




Tuple Mover Best Practices: Part 2
Applies to Vertica 9.2 and later
Tuple Mover Overview
Vertica Analytics Platform loads the data into ROS data storage. The data that is loaded into ROS is stored as sorted, encoded, and compressed data, based on Projection design.
Tuple Mover is a Vertica service that runs in the background and performs Mergeout operation that combines small ROS containers into larger ones and purges deleted data.
The database mode affects which nodes perform this operation:
- In Enterprise Mode, all nodes run the Tuple Mover service to perform the Mergeout operation on the data stored in each node.
- In Eon Mode, the Primary Subscriber to each shard plans the Mergeout operation on the ROS containers in the shard. In version 11.0.2 or later, it can delegate the execution of this plan to another node that has memory allocated to TM Resource Pool in the cluster.
In most use cases, the Tuple Mover requires little or no configuration beyond the default parameters. However, some workloads may require tuning of configuration parameters.
This document answers frequently asked questions and provides troubleshooting tips.
Following the information given in this document can help improve Tuple Mover operations and system efficiency.
Mergeout Operation
The Tuple Mover Mergeout operation is a Vertica service that runs in the background, consolidates ROS containers, and purges deleted data. The maximum number of ROS containers per projection per node is 1,024. If you encounter an error during a data load that states “TOO MANY ROS CONTAINERS” (ROS pushback), you have reached the maximum number of ROS containers per projection per node. ContainersPerProjectionLimit configuration parameter defines this maximum number. However, it is not recommended to increase this number because it hits performance degradation when the column data is fragmented across multiple ROS containers. Mergeout operation consolidates ROS containers into fewer containers, verifying that the database does not hit this limit under normal usage.
Best Practices for Mergeout
Monitoring
You can use the following query to check the mergeout performance.
SELECT
dtme.node_name,
dtme.transaction_id,
dtme.projection,
dtme.table_name,
dtme.container_count,
dtme.total_size_in_gb,
dtme.start_time,
dtme.complete_time,
dtme.epochs,
dtme.number_of_columns,
dtme.columns_in_sort_order,
dtme.row_length,
dtme.number_of_wide_1k_cols,
dtme.widest_col,
dtme.mergeout_time,
dtme.mergeout_throughput||' GB/Mn' mergeout_throughput,
dtme.include_replay_delete,
dra.memory_mb,
des.bytes_spilled
FROM
(
SELECT
s.node_name,
s.transaction_id,
s.schema_name||'.'||s.projection_name projection,
s.table_name,
s.container_count,
(s.total_size_in_bytes / 1024^3)::NUMERIC(10, 2) total_size_in_gb,
s.time start_time,
c.time complete_time,
(s.end_epoch - s.start_epoch) epochs,
projcols number_of_columns,
sortkey columns_in_sort_order,
col.row_length,
col.cnt_widecols number_of_wide_1k_cols,
col.widest_col,
DATEDIFF(MINUTE, s.time, c.time) mergeout_time,
TRUNC(s.total_size_in_bytes / 1024^3 / NULLIFZERO(DATEDIFF(MINUTE, s.time, c.time)), 3)::NUMERIC(5, 3) mergeout_throughput,
CASE WHEN c.plan_type = 'Replay Delete' THEN true ELSE false END include_replay_delete
FROM dc_tuple_mover_events s
JOIN dc_tuple_mover_events c
ON s.node_name = c.node_name
AND s.projection_oid = c.projection_oid
AND s.transaction_id = c.transaction_id
AND s.total_size_in_bytes = c.total_size_in_bytes
AND s.session_id = c.session_id
AND s.operation = 'Mergeout'
AND c.operation = 'Mergeout'
AND s.event = 'Start'
AND c.event = 'Complete'
JOIN vs_projections p
ON p.oid = s.projection_oid
JOIN (
SELECT
t_oid,
SUM(attlen) row_length,
COUNT(CASE WHEN attlen >= 1000 THEN 1 ELSE NULL END) cnt_widecols,
MAX(attlen) widest_col
FROM vs_columns GROUP BY 1) col
ON t_oid = p.anchortable
) dtme
JOIN (
SELECT node_name, transaction_id, (MAX(memory_kb) / 1024)::INT memory_mb FROM dc_resource_acquisitions WHERE pool_name='tm' GROUP BY 1, 2
) dra
USING (node_name, transaction_id)
JOIN dc_Execution_summaries des
USING (node_name, transaction_id)
WHERE
dtme.total_size_in_gb > 1
ORDER BY
dtme.mergeout_time DESC,
dtme.mergeout_throughput,
dtme.total_size_in_gb DESC;
Memory Size of TM Resource Pool and Optimal Projections
Mergeout operation may not have optimal performance in the following case:
- Projection has hundreds of columns.
- Row length is greater than 10,000.
- Sort key is with more than 8 columns.
If the performance for a projection is less than 1GB per minute, set the MEMORYSIZE of TM resource pool to 5% of available memory or 10GB, whichever is smaller. If the mergeout throughput is less, set PLANNEDCONCURRENCY to value 3.
Confirm that there is no wide VARCHAR column in the sort order of the projections, and there are no more than 8 columns in the sort order. Each column should have enough width.
Max Concurrency and Planned Concurrency of TM Resource Pool
If your workload requires additional mergeout threads, increase the MAXCONCURRENCY and PLANNEDCONCURRENCY parameters of TM resource pool. In 9.3 or previous releases, only the first and last thread work on the inactive partitions regardless of the value of MAXCONCURRENCY and PLANNEDCONCURRENCY. In 10.0 or later release, half of the threads work on both active and inactive partitions, and the other half of the threads work on only active partitions.
Partition Table
Vertica does not merge ROS containers across partitions. Thus, tables with hundreds of partitions can hit ROS pushback quickly. Consider using Hierarchical Partitioning to reduce the number of ROS containers. If you have older partitions that you no longer access, you can move them to archived tables using the MOVE_PARTITION_TO_TABLE function.
If your tables receive frequent data into the current and the most recent inactive partition, change the ActivePartitionCount parameter to 2 from the default of 1. Vertica expects partitions to be time-based, with one active partition receiving data and other inactive partitions rarely or never receiving data. The Tuple Mover merges ROS containers for inactive partitions into the minimum number of containers.
Projection Sort Order
Include fewer than 8 columns in the sort order and avoid having wide VARCHAR columns in the sort order. To control the number of columns in the sort order, replace table projections with new projections that contain fewer columns in the sort order and avoid having wide VARCHAR columns in the sort order. This helps decrease the time it takes for the mergeout operation to run. Long running operations can block mergeout threads, which increases the number of ROS containers.
Optimize Projections for Delete and Replay Delete
Optimize your projections for deletes by using a high-cardinality column as your last column in the sort order. This helps you avoid a long running mergeout due to replay delete. If mergeout is stuck performing a replay delete, cancel the operation using the close_session(<session_id>) function. Then run the make_ahm_now function to advance the Advanced History Mark (AHM) epoch.
=> SELECT close_session('<session_id>');
=> SELECT make_ahm_now();
After the AHM advances, deletes do not replay and the mergeout operation should run faster. You can also purge the deleted rows manually using purge_table function.
=> SELECT purge_table('<table_name>');
Long running mergeouts performing replay delete can cause ROS container accumulation over time.
For more information about Replay Delete, see Understanding the Vertica Replay Delete Algorithms.
Verify Reorganize Operation Completed Successfully
You can check the status of the reorganize operation by checking the PARTITION_STATUS system table. If a partition expression is altered but the reorganize expression does not start or fails, the ROS containers of the projections anchored on the table that existed before the alteration cannot qualify for mergeout until the table is reorganized. You can resolve this issue by initiating:
=> ALTER TABLE <TABLE_NAME> REORGANIZE;
Disable Mergeout on Specific Table
By default, Vertica merges ROS containers of all tables. If you create a table for a temporary purpose and you delete it soon after completing the task, you may want to disable mergeout on it. In 11.0 or later release, you can disable it using the following statement:
=> ALTER TABLE <TABLE_NAME> SET MERGEOUT 0;
Disable Mergeout Operation on Specific Subcluster
In Eon Mode, the Primary Subscriber plans and performs the Mergeout operation on the ROS containers in the shard. The secondary subcluster can focus on the other workloads. In 11.0.2 or later, it can delegate the execution of this plan to another node even if that node is in the secondary subcluster. It can help you to move the mergeout operation workload from the Primary Subscriber to the other nodes. However, it may affect the performance of the secondary subcluster. The Primary Subscriber ignores all nodes in the subclusters whose TM Resource Pool's MEMORYSIZE and MAXMEMORYSIZE settings are 0.
Frequently Asked Questions for Mergeout
How does STRATA algorithm work?
The Tuple Mover mergeout operation uses a strata-based algorithm. This algorithm is designed to verify that each tuple is subjected to mergeout a small constant number of times despite the load process that is used to load the data. Using this algorithm, the mergeout operation chooses which ROS containers to merge for tables without partitions and for active partitions in partitioned tables.
Vertica builds strata for each active partition and projections anchored to non-partitioned tables. The number of stratum, size of each stratum, and maximum number of ROS containers in a stratum is computed based on disk size, memory, and the number of columns in a projection.
The following graphic shows how the algorithm categorizes ROS containers into strata based on their size. Any ROS containers in stratum 0 are of negligible ROS size (1 MB per column or less). The purple dots represent the ROS containers:
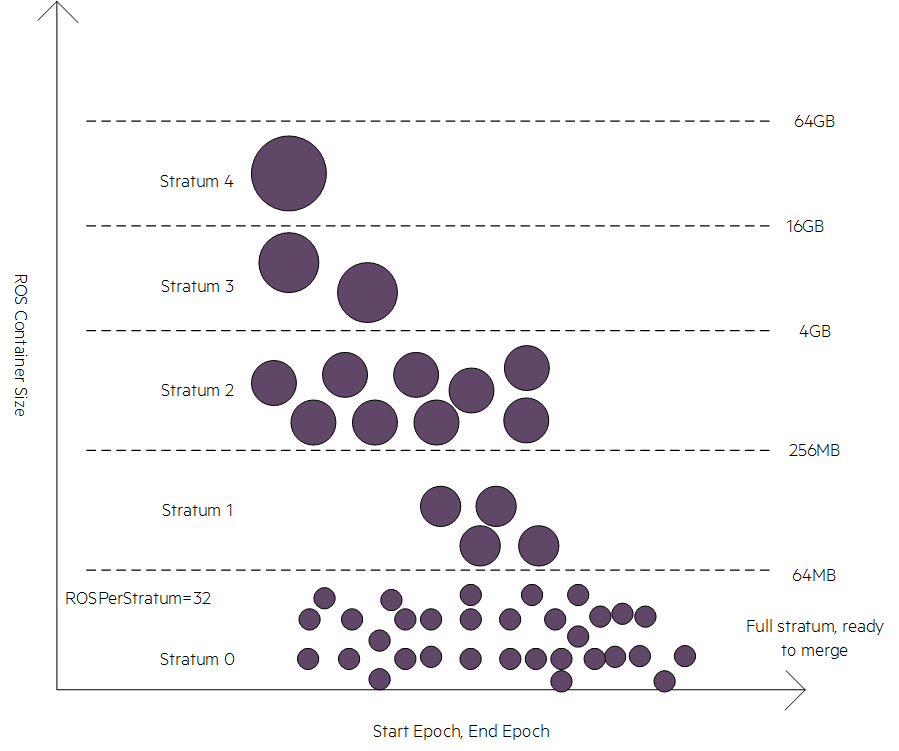
Merging small ROS containers before merging larger ones provides a maximum benefit in the mergeout algorithm. The algorithm begins at stratum 0 with 1 byte to the negligible ROS chunk size and moves upward. It checks to see if the number of ROS containers in a stratum has reached a value equal to or greater than the maximum ROS containers allowed per stratum. The default value is 32. If the algorithm finds that a stratum is full, it marks the projections and the stratum as eligible for mergeout.
The mergeout operation combines ROS containers from full strata and produces a new ROS container that is usually assigned to the next stratum. Except for stratum 0, the mergeout operation merges only those ROS containers equal to the value of ROSPerStratum. For stratum 0, the mergeout operation merges all eligible ROS containers present within the stratum into one ROS container.
Does the mergeout operation purge deleted data?
The Tuple Mover purges only data that was deleted prior to the AHM in a ROS container that qualified for mergeout based on the strata algorithm. Data that is deleted in inactive partitions can also be purged. However, to qualify for purge, the percentage of deleted data in a ROS container with inactive partitions must exceed the value of the PurgeMergeoutPercent parameter. The default value of this parameter is 20.
When and how can I use the following configuration parameters?
| Parameter | Function |
|
|
The number of ROS containers in a stratum. When a stratum reaches the default value of 32, the projection qualifies for mergeout. Decreasing this value increases I/O because records participate in more mergeout operations but it decreases the number of ROS containers. |
|
|
When the number of delete vectors attached to a single ROS container reaches the default value of 10, the Tuple Mover mergeout operation merges delete vectors. |
How can I find active partitions for a given projection?
You can find the active partitions for a given projection using the following query:
=> SELECT DISTINCT stratum_key FROM strata -> WHERE projection_name = <PROJECTION_NAME> AND schema_name = <SCHEMA_NAME>;
How can I find the container count per projection per node?
You can find the container count per projection per node using the following query:
=> SELECT -> node_name, schema_name, projection_name, -> SUM(delete_vector_count) delete_vector_count, -> COUNT(*) ROS_container_count, -> SUM(delete_vector_count) + COUNT(*) total_container_count -> FROM storage_containers -> GROUP BY 1, 2, 3 ORDER BY 6 DESC;
How does Reflexive Mergeout work?
In the previous release, the Tuple Mover mergeout is running as a background service based on a fixed schedule (MergeOutInterval parameter). These background threads wake up and go through almost the entire catalog to find out a mergeout job. As each thread is doing this work independently, not only do they go through the catalog but if they step onto each other, they throw away jobs, and start over. Reflexive Mergeout has been introduced to make mergeout more efficient, running mergeout preemptively when nearing ROS pushback before reaching there, and changing the way threads access the catalog.
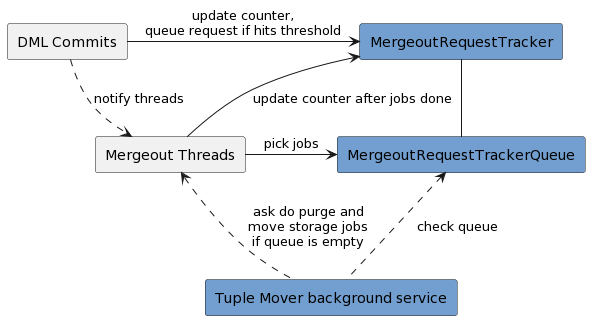
MergeoutRequestTracker keeps track of storage container and delete vector counts for different projections along with the timestamps of the last mergeout job ran on that projection, and minimum delete epoch for purge. Every node on Enterprise Mode has MergeoutRequestTracker. On Eon Mode, all nodes maintain it, but only the primary subscriber serves mergeout requests.
DML commits increments count of storage container and count of storage container since last mergeout request, and max count of delete vector as needed. If the counter since last request reaches the threshold, it queues a mergeout request. The threshold is recalculated with add/drop columns and change of configuration parameters like ContainersPerProjectionLimit and MaxROSPerStratum. If the counter of max delete vector reaches MaxDVROSPerContainer configuration parameter, it queues a mergeout request for the delete vector. In case that the minimum delete epoch is lower than AHM epoch, it queues a purge request.
Mergeout Thread is notified when a request is queued. It asks MergeoutRequestTracker for a request. If any request exists in the queue, the thread picks it up and runs the job for it. Once the job completes, update the counter. Tuple Mover background service checks the queue. If the queue is empty, it asks the thread to go through all projections of the tracker and find the jobs.
To monitor the operations of Reflexibe Mergeout, you can query vs_mergeout_request_tracker_status system table for MergeoutRequestTracker, and vs_mergeout_request_tracker_queue system table for MergeoutRequestTrackerQueue.
=> SELECT -> mrts.node_name, -> prj.projection_schema || '.' || prj.projection_name projection_name, -> mrts.mergeout_container_count_threshold, -> mrts.container_count_since_mergeout, -> mrts.container_count_since_last_request, -> mrts.last_mergeout_time, -> mrts.dv_count_threshold, -> mrts.max_dv_count_for_dml, -> mrts.last_dv_mergeout_time, -> mrts.minimum_purge_eligible_epoch -> FROM -> vs_mergeout_request_tracker_status mrts -> JOIN projections prj ON mrts.projection_id = prj.projection_id; -----------------------------------+-------------------------------------- node_name | v_verticadb_node0001 projection_name | public.table_super mergeout_container_count_threshold | 32 container_count_since_mergeout | 18 container_count_since_last_request | 20 last_mergeout_time | 2022-08-17 12:23:50.117501 dv_count_threshold | 5 max_dv_count_for_dml | 0 last_dv_mergeout_time | 2022-08-17 12:20:06.947105 minimum_purge_eligible_epoch | => SELECT -> mrtq.node_name, -> prj.projection_schema || '.' || prj.projection_name projection_name, -> mrtq.request_id, -> mrtq.request_type, -> mrtq.storage_creation_rate, -> mrtq.stratum, -> mrtq.request_created_time -> FROM -> vs_mergeout_request_tracker_queue mrtq -> JOIN projections prj ON mrtq.projection_id = prj.projection_id; ----------------------+------------------------------ node_name | v_verticadb_node0001 projection_name | public.table_super request_id | 208 request_type | MERGEOUT storage_creation_rate | 0.015625 stratum | 0 request_created_time | 2022-08-17 12:32:44.253273
Why Inactive Partition is not merged?
Vertica has one internal rule not to merge huge ROS files in inactive partitions with tiny ROS to minimize I/O and prevent unnecessarily rewriting huge ROS files. If the file size of ROS is larger than 10 times of the total size of other ROS files in one mergeout job, that huge ROS file is skipped to be merged. This rule sometimes causes the ROS pushback. In 10.0.1 or later, Vertica doesn't apply this rule to the projections in which the number of ROS containers is larger than half of the ContainersPerProjectionLimit configuration parameter.
Additional Resources
For more information about Tuple Mover, see the Vertica documentation.

