




Reading Query Plans
This is the first document in the three-part series on performance tuning, containing these articles:
Part 1: Reading Query Plans
Part 2: Troubleshooting Vertica Query Performance with System Tables
Part 3: Redesigning Projections for Query Optimization
Query Plans
A query plan is a sequence of step-like paths that the Vertica query optimizer selects to execute the statement in your Vertica database. Vertica can execute a query in many different ways to achieve the same results. The query optimizer creates a plan that executes the query at the lowest execution cost. The Vertica user runs EXPLAIN on a query to analyze how the database processes a query and to see a visual representation of the paths that Vertica uses to execute the query.
The EXPLAIN Statement
The EXPLAIN statement returns a formatted description of the optimizer's execution plan for the specified statement. You can use this information to analyze and investigate the query. By default, EXPLAIN output represents the query plan as a hierarchy. Each level represents a single database operation that the optimizer defines to execute the query. The EXPLAIN output also appends .DOT language to the source file that enables you to display this output graphically.
Consider the following query with the EXPLAIN statement.
EXPLAIN SELECT DISTINCT s.product_key, p.product_description FROM store.store_sales_fact s, public.product_dimension p WHERE s.product_key = p.product_key AND s.product_version = p.product_version AND s.store_key IN ( SELECT store_key FROM store.store_dimension WHERE store_state = 'MA') ORDER BY s.product_key;
The next sections provide details about the EXPLAIN statements and output options.
EXPLAIN Output Options
The EXPLAIN statement has the following types of outputs:
- EXPLAIN option: The EXPLAIN option returns detailed information about the query execution plan without executing the query. You can view the output as a textual output or as a graphical output.
- EXPLAIN LOCAL VERBOSE option: The EXPLAIN LOCAL VERBOSE option returns detailed information useful for analyzing complex queries. The detailed information includes costs and memory usage per resource. You can view the output as a textual output or as a graphical output.
EXPLAIN Results
The EXPLAIN option returns detailed information about the query execution plan without executing the query. The query optimizer considers different query rewrites, combinations of projections, and JOIN orders, resulting in different execution plans.
Then, to choose the best query plan, the optimizer performs a statistical analysis. It assigns a cost to each operator and selects the least costly plan as the execution plan. Vertica returns the chosen query plan with the EXPLAIN option in two different formats:
- Textual output: A plain-text representation of the query plan. The query plan lists the steps in detail, and Vertica executes the query plan with a bottom-to-top approach.
- Graphical output: The query plan is in the .DOT language.
- You can use the Management Console to view the tree path.
- You can use the web visualization tools like Graphviz to view the graphical representation.
This representation gives more details than the plain-text plan and provides better readability and presentation for complex queries.
Textual Output for EXPLAIN
The access path information for the example query shown earlier in this document describes the operator, cost, projection, column materialization, and path ID for the query.
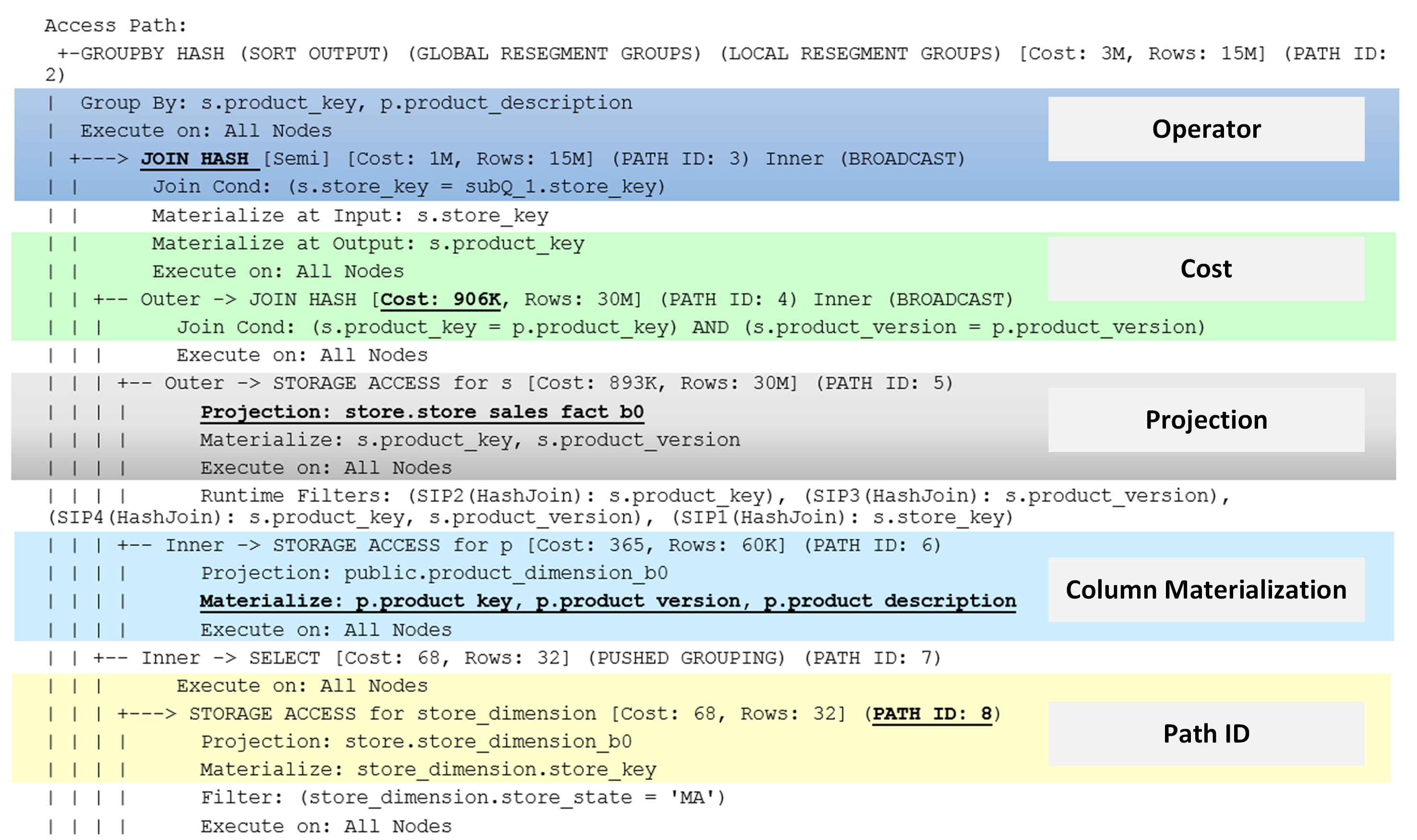
- Operators: Vertica executes the operators such as JOIN, SORT, FILTER, LIMIT, as designated in a query plan, using a bottom-to-top approach. These operators can:
- Be single or multi-threaded
- Stream data to the next operator
For example, some operators need to complete computation before moving to the next operation such as SORT or GROUPBYHASH. Others can stream data before completing computation such as JOIN.
- Cost: The optimizer calculates the cost for each operator using algorithms that estimate resources for CPU, memory, and network. The estimate of usage of resources is based on statistics. Some examples of the statistics are as follows:
• Number of rows in the table.
• Number of distinct values of each column.
• Minimum or maximum values of each column.
• Histogram of the distribution of values in each column.
• Disk space of each column.
Update statistics at regular intervals. Without accurate statistics, the optimizer could choose a sub-optimal plan that affects query performance.
Update statistics by running either of the command:=> SELECT ANALYZE_STATISTICS => SELECT ANALYZE_HISTOGRAM
For more information, see Getting Statistics and Histograms in the Vertica documentation.
- Projection: The optimizer analyzes possible projection combinations that meet the query requirements to determine which projection has the lowest computation cost. When it plans a query, the optimizer chooses one projection per table. However, if a node is down, the optimizer could choose two projections for the same table.
- Column Materialization: The column materialization provides access to columns for executing the operator. Access refers to opening the column file, encoding, and uncompressing based on projection column definition.
- Path ID: The Path ID is an integer value that the optimizer assigns to each query operation for a specific transaction. When the query plan includes multiple operators, analyzing the profile information the Path ID helps the optimizer to identify the operators at every instance.
Graphical Output for EXPLAIN
Use Management Console to view the graphical representation of the query plan. The Management Console ships with Vertica. For more information about how to use Management Console to view a query plan, see the Vertica documentation. If you do not have access to Management Console, you can use open-source web visualization tools to view the graph. The graphical output provides detailed information about the query plan for better comprehension of the query plan.
The following figure shows how a graph visualization tool, Graphviz, displays the graph of the example query from earlier in this document. The following graph is a snippet of the complete graph.

Each object in the graph corresponds to an operator, and the boxes provide detailed information about that operator. The different shapes and the colors of the boxes help you to visually understand the data flow.
| Color | Description |
|---|---|
|
Green |
Single-threaded operation that passes data from its own operator to another. |
|
Brown |
Multi-threaded operators. The number of threads that can be managed on the settings the resource pool in which the query is executed. |
|
Purple |
Combined stream of data or storage. |
|
Blue |
Data target that is written to the disk. |
|
Shape |
Description |
|
Oval or Circle |
Push model. The operator sends the information to the next operator above it. |
|
Rectangle |
Pull model. The next operator looks for information from the operator data buffers. |
|
House |
Root object where the query starts. |
This table lists the most important operators of the preceding graphical plan.
| Operators | Description | Usage Considerations |
|---|---|---|
|
Copy |
Makes a copy of the data for the buddy projections during load. |
|
|
DataTarget |
Writes the data from WOS to ROS during load. |
|
|
ExprEval |
Evaluates expressions such as C1+C2. |
Select only the required columns. |
|
Filter |
Filters Vertica tuples to the next operator. |
|
|
GroupByHash |
Aggregates tuples in hash in memory before streaming data to the next operator. |
GroupByHash uses all possible memory. If the data exceeds available memory, disk spillover results. The operator must complete all the operations before passing the data to the next operator. |
|
GroupByPipe |
Aggregates sorted tuples before streaming data to the next operator. |
GroupByPipe has fewer memory requirements than GroupbyHash and streams data to the next operator. |
|
Join Merge-Join |
Joins pre-sorted tuples. |
Uses less memory. |
|
Join Hash-Join |
Joins unsorted tuples by loading the inner side of the join operator in memory. |
If the inner side is large, and the data does not fit in memory, the query fails. If the inner side is small, the operation is faster than merge-join. |
|
Load |
Loads data from disk and parses the input. |
|
|
Merge |
Merges multiple data streams into one sorted stream. |
|
|
NetworkRec NetworkSend |
Information about the data sent to another node or the data received from another node. |
The query requires more memory for each pair of network operators (send and receive). |
|
ParallelMerge |
Combines sorted data stream. |
|
|
ParallelUnion |
Combines not sorted data stream. |
|
|
Root |
The first operator. |
|
|
Scan |
Reads data from the disk for applying filters. |
|
|
Sort |
Sorts data stream. |
|
|
StorageMerge |
Combines data storage while maintaining the sort order. |
|
|
StorageUnion |
Combines data storage without maintaining the sort order. |
|
|
Top-K |
Analytic function that returns the Top-K tuples. |
|
|
ValExpr |
Evaluates join expressions. |
Next, let’s examine in detail the three operators for the example query.
- Send or Recv: A green section of send and receive in the middle of the plan indicates network operations, such as broadcast or segmentation, which can indicate an incorrect projection design.

In the graph, as the color indicates, data moves single threaded through the network. In the middle of the plan, this single threading slows the query because the operators above this operation cannot complete execution until the first Send operation completes.
In addition, this network operation requires more memory because each Send/Recv combination needs a network buffer to hold the tuples. The more nodes your cluster has, the more buffer is required. Avoid using Send/Recv operators. To do so, redesign your projections so that data is available in the nodes when executing joins or group by.
- GROUPBYHASH: A GROUPBYHASH is a single-threaded operation, not a data-streaming operation. Vertica must complete the whole GROUPBY calculation to be able to send information to the operators above the GROUPBYHASH operator. In the graph plan, you can see the following sequence:

In this case, when Vertica executes a GROUPBYHASH operation in the same path, it also executes GROUPBYPIPE to start the aggregation from the storage containers. STORAGEUNIONSTEP (purple box) combines the results of these operators to send data to the GROUPBYHASH to complete the aggregation of the statement in this path. These details are available only in the graphical plan and do not appear in the textual query plan.
- SIP: The graphical plan also provides information about Sidewise Information Passing (SIP). In a graphical plan, SIP shows the filters Vertica can use to reduce tuples derivatives. Reducing the number of tuples that pass through a JOIN operator can lower the resource consumption and thus improve query performance.

EXPLAIN LOCAL VERBOSE Results
EXPLAIN LOCAL VERBOSE is another way to review details about the optimizer recommendations for executing the query. The EXPLAIN LOCAL VERBOSE option adds more information that is useful for reviewing complex queries. The EXPLAIN LOCAL VERBOSE output provides detailed information about the following:
- Textual output: A plain-text representation of the query plan. The query plan lists the step details, and Vertica executes the query plan with a bottom-to-top approach. This plan has the same operators and paths that appear in the EXPLAIN output. However, it also contains more details, such as cost, memory, and network information for each operator.
- Graphical output: The query plan is in the .DOT language.
- You can use the Management Console to view the tree path.
- You can use the web visualization tools like Graphviz to view the graphical representation.
The graphical representation gives more details than the plain-text plan and provides better readability and presentation for complex queries. EXPLAIN LOCAL VERBOSE option generates several graphical plans. Each of the following is an individual graphical plan.
- Simplified join order: The simplified plan contains only minimum join information necessary for understanding the query. Viewing this plan is useful for understanding complex statements. The next section contains an example of a simplified join order.
- JOIN graph: The plan consists of descriptions of joins in the query plan.
- Plan for each node
- Initiator node
- Executor nodes. If you have multiple nodes you will have multiple plans—one for each node.
- Resource information for each node: Detailed information about resources to execute the plan on each node. The optimizer calculates the resources, and the execution engine allocates the resources. The next section contains an example that shows the resource information for a given node.
Consider the following query with the EXPLAIN statement.
EXPLAIN LOCAL VERBOSE SELECT DISTINCT s.product_key, p.product_description FROM store.store_sales_fact s, public.product_dimension p WHERE s.product_key = p.product_key AND s.product_version = p.product_version AND s.store_key IN ( SELECT store_key FROM store.store_dimension WHERE store_state = 'MA') ORDER BY s.product_key;
Textual Output for EXPLAIN LOCAL VERBOSE
EXPLAIN LOCAL VERBOSE returns a query plan that has the same information as the query plan for EXPLAIN, with additional details such as costs and the weight for different resources. In the following sample, the text in bold identifies the additional costs, network, and memory usage per resource.
Access Path: Sort Key: (store_sales_fact.product_key, product_dimension.product_description) LDISTRIB_UNSEGMENTED +-GROUPBY HASH (SORT OUTPUT) (GLOBAL RESEGMENT GROUPS) (LOCAL RESEGMENT GROUPS) [Cost: 2662115.000000, Rows: 15000000.000000 Disk(B): 2400000000.000000 CPU(B): 2280000000.000000 Memory(B): 4560000000.000000 Netwrk(B): 4440000000.000000 Parallelism: 3.000000] [OutRowSz (B): 144] (PATH ID: 2) | Group By: s.product_key, p.product_description | Execute on: All Nodes | Sort Key: (store_sales_fact.product_key, product_dimension.product_description) | LDISTRIB_SEGMENTED | +---> JOIN HASH [Semi] [Cost: 1387361.000000, Rows: 15000000.000000 Disk(B): 5436997632.000000 CPU(B): 4800001024.000000 Memory(B): 2304.000000 Netwrk(B): 768.000000 Parallelism: 3.000000] [OutRowSz (B): 152] (PATH ID: 3) Inner (BROADCAST)
Graphical Output for EXPLAIN LOCAL VERBOSE
The following figure shows how a graph visualization tool, Graphviz, displays the graph of the example query from earlier in this document. Each box provides more detailed information than the graphical output for the EXPLAIN statement. The following graph is a snippet of the complete graph.

Simplified Join Order for EXPLAIN LOCAL VERBOSE
The Simplified Join Order boxes provide information about operators (SORT, JOIN, MERGE, and GROUPBY) in an easy-to-read format. In complex queries with several joins, this plan can help you understand query execution.

Resource Information for EXPLAIN LOCAL VERBOSE
The EXPLAIN LOCAL VERBOSE option returns resource information about each node. The query plan generates the estimated resources. The following example shows the estimated resources that the initiator node would require to execute the query.
Estimated resources for plan: ----------------------------- Scratch Memory MB: 1474 File Handles: 64 Worker Threads: 38 Blocking Threads: 22 Externalizing Ops: 4 Unbounded Mem Ops: 2 Max Threads: 2

