




ROS Bundling
Prior to Vertica 7.2, there were two files per column – a data file and an index file. As of Vertica 7.2, this format no longer exists. Instead, both parts are now stored in one file. Additionally, multiple data files and index files can also be stored in one file.
Vertica file architecture
The following graphic illustrates the Vertica file architecture, and how tables and projections are boiled down to files:
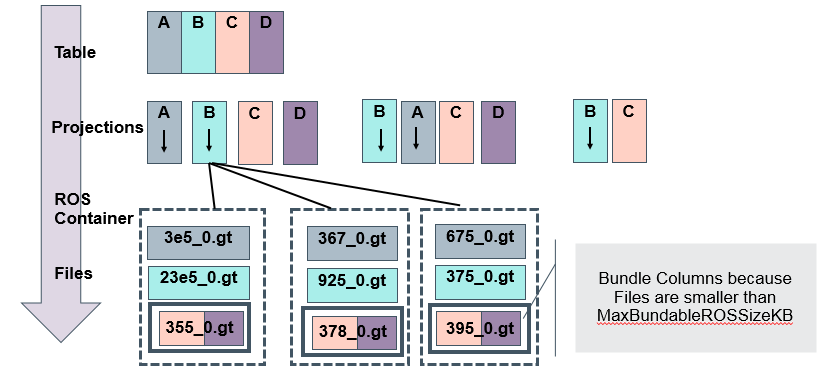
New storage format
Vertica is designed to handle large data sets. File sizes on disks range from hundreds of megabytes to hundreds of gigabytes. The Tuple Mover helps to manage data storage. In-memory buffers absorb trickle loads, and the Tuple Mover moveout operation writes data into ROS containers as the memory buffer fills up. To manage the number of files on disk, the Tuple Mover mergeout operation merges ROS containers of a similar size to create larger containers. For more information, see Tuple Mover Best Practices.
While this method works well with most tables, it can present issues on tables that have a large number of small files. This can happen if any of the following is true of your data set:
- Wide column tables contain NULL value columns
- Partition ranges are small, such as partitioning by minute. This is not a recommended practice.
- Local segmentation is enabled and the factor is set to a higher number. This is not a recommended practice.
These factors create tiny files on-disk, causing a lot of fragmentation that can affect node recovery and backup operations. To resolve this issue, Vertica engineers developed the new on-disk storage format and layout, which reduces the number of files stored on disk.
How is the new format different?
The data file and its index file are now stored in one file. For example, before Vertica 7.2, a storage container with a two-column projection stored six files. In Vertica 7.2 and later, the container stores three files. If those files are smaller than 1MB, Vertica bundles them together, and stores them as one file.
Does the new functionality bundle all projection files?
No, bundling occurs only within a storage container and within a storage location. Column files that are smaller than MaxBundleableROSSizeKB are bundled together; other column files are kept as independent column files in a storage container.
Why is ROS bundling useful?
Bundling reduces the number of files in your storage containers, thus reducing the pressure on the underlying file system, and facilitates faster backup and restore operations, as well as recovery. Bundling does not reduce the size of the catalog, and it does not eliminate the ROS pushback error. Bundling does not change the number of file handles used when reading the column files.
What configuration parameters are associated with the bundling functionality?
| Parameter | Data Type/Default | Description |
| EnableStorageBundling | Boolean/True | Enables or disables storage bundling. |
| MaxBundleableROSSizeKB | Integer/1024 | Can be set up to 1024 KB. If more than one data file is under this size limit, in the same container and storage location, the files are bundled together. |
| CompactStorageJobSizeMB | Integer/2048 | Controls a job size of the function COMPACT_STORAGE(). |
What is the upgrade impact from Vertica 7.1 to Vertica 7.2?
Upgrading does not automatically convert existing files from the old format to the new format. After you upgrade, you can use the function COMPACT_STORAGE() to convert the file format of existing files. If EnableStorageBundling is set to true, the following behavior applies:
- All new loads and inserts are written in the new storage format.
- Existing storage that is merged out is written in the new storage format.
Are the old and new formats compatible?
Yes. If you upgrade your database and a table contains both small and large files, you can selectively move small files to the new format, and leave large files in the old format.
How can I move data from the old storage format to the new format?
Use COMPACT_STORAGE() , as shown in the following example:
=> SELECT COMPACT_STORAGE(object-name,
object-name,
min-ros-filesize-kb,
small-or-all-files,
simulate);
The sample output of this function looks like the following:
compact_storage
---------------------------------------------------------------------------------------------------------------
Task: compact_storage
On node node01:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node node02:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node node03:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
Success
What if I specify a different value for min_ros_filesize_kb than the current MaxBundleableROSSizeKB?
The COMPACT_STORAGE() function parameter min_ros_filesize_kb is independent of the MaxBundleableROSSizeKB configuration parameter. The function uses the value you specify for min_ros_filesize_kb. This has no impact on the value of MaxBundleableROSSizeKB. If you want to bundle files of a larger size in new mergeouts and loads, you must change the value of MaxBundleableROSSizeKB.
When is the best time to convert to the new storage format?
For best results, convert existing files after you upgrade your Vertica database to 7.2, but before you perform the first backup. This helps with backup and restore for two reasons:
- Reduces the number of files, resulting in a faster backup.
- Transfers new storage, so subsequent backups can run faster.
You can use the database while running compact_storage.
Does COMPACT_STORAGE() affect query performance?
COMPACT_STORAGE() reads and writes files at the storage container level. It uses less memory when compared with the mergeout operation, but competes with disk I/O.
How long does COMPACT_STORAGE() take to run?
Because this function rewrites files, execution time varies depending on how much data changes. Run a simulation by setting the COMPACT_STORAGE() function parameter simulate to TRUE, to determine how much storage will change.
You can rewrite storage formats incrementally by running COMPACT_STORAGE() iteratively at the table or projection level.
How can I know if my database will benefit from this functionality?
If backup and restore operations are slow, you probably have many large files that are not getting merged. You can run the following query to find the median file size of a projection on a node:
=> SELECT MEDIAN(size) OVER() AS median_fsize
FROM vs_ros AS ros, storage_containers AS cont
WHERE ros.delid=cont.storage_oid
AND cont.node_name=‘node'
AND cont.projection_name=‘proj_name' limit 1;
You can also run COMPACT_STORAGE() in simulation mode to see how many files it can reduce:
=> SELECT COMPACT_STORAGE(‘table_or_proj_name’, 1024, ‘small’, ‘true’);
What system table can I use to see what storage containers are bundled?
Query the system table VS_BUNDLED_ROS to see which column files are bundled:
node_name| projection_id | sal_storage_id | ros_id | size_bytes | storage_id
---------+-------------------+--------------------------------------------------+-------------------+------------+-------------------
initiator| 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721409 | 5 | 45035996273721409
initiator| 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721413 | 5 | 45035996273721409
initiator| 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721417 | 48 | 45035996273721409
(3 rows)
If I have large storage containers, can I use 100MB as the value for min_ros_filesize_kb?
To determine the value of min_ros_filesize_kb, run COMPACT_STORAGE() in simulation mode to determine resource usage. For example, if you have a storage container with 100 data files, each less than 1MB, COMPACT_STORAGE() changes these from 200 files to 1 file. In this case, specifying 100MB or 1MB for the value of min_ros_filesize_kb makes no difference.
If you have another container with 100 data files, each about 40MB, COMPACT_STORAGE() changes these from 200 files to 1 file. In this case, specifying 100MB makes a positive difference. If we specified 1MB, the container goes from 200 files to 100 files.
To determine what value to set for min_ros_filesize_kb, follow this procedure:
- Pick a projection.
- Determine the number of files and the median file size of the projection.
- Run COMPACT_STORAGE() in simulation mode, with values that range from the median size to 100MB.
- Determine the sweet spot for your database, based on the values produced from the simulation.
The following example shows how to analyze the need and impact of compact_storage on an updated Vertica database, and determine an optimal value for min_ros_filesize_kb:
Check that the file counts are not bundled:
=> SELECT COUNT(distinct (salstorageid))
* 2 /* one fdb and one pidx */
FROM v_internal.vs_ros
WHERE bundleindex < 0; -- older versions dont have bundleindex
count
---------
1379533
(1 row)
Find the size and number of files that are not bundled, group by projection and node:
=> SELECT CASE WHEN segment_lower_bound is not null THEN 'SEGMENTED' ELSE 'REPLICATED' END AS type,
schema_name,
projection_name,
max(used_bytes) max_used_bytes,
min(used_bytes) min_used_bytes,
CASE WHEN segment_lower_bound is not null THEN count (distinct colid) ELSE count (distinct colid), count(distinct rosid) AS nFiles
FROM storage_containers join v_internal.vs_ros ON (delid = storage_oid)
WHERE bundleindex < 0 -- older versions dont have bundleindex
GROUP BY 1,2,3 ,segment_lower_bound
ORDER BY 7 desc
;
type | schema_name | projection_name | max_used_bytes | min_used_bytes | nCols | nFiles
----------+-------------+-----------------+----------------+----------------+-------+--------
SEGMENTED | schema | clients_b1 | 92368520 | 14778 | 13 | 650
SEGMENTED | schema | clients_b0 | 47906279 | 14728 | 13 | 611
SEGMENTED | schema | clients_b0 | 100868741 | 18776 | 13 | 572
SEGMENTED | schema | clients_b0 | 59835832 | 15173 | 13 | 572
SEGMENTED | schema | clients_b1 | 58541167 | 15441 | 13 | 507
SEGMENTED | schema | clients_b1 | 61792636 | 14728 | 13 | 507
Allocate file sizes in different buckets to see the distribution:
=> SELECT
WIDTH_BUCKET (used_bytes, 0, 1024*1024*1024, 999) AS bucket, -- 1GB size of max bucket, 1000 buckets, (i.e. 1MB each bucket)
count(rosid) fileCnt
FROM
storage_containers JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE
schema_name = 'schema'
AND projection_name='clients_b1'
AND bundleindex < 0 -- older versions dont have bundleindex
GROUP BY 1
ORDER BY 1
;
bucket | fileCnt
-------+---------
1 | 715 <=== so many small 1 MB or less files
4 | 13
5 | 26
10 | 26
14 | 39
15 | 52
16 | 65
17 | 26
18 | 52
19 | 39
20 | 299
21 | 39
23 | 13
24 | 13
25 | 13
29 | 13
31 | 13
32 | 39
40 | 26
41 | 13
42 | 13
44 | 13
45 | 39
48 | 13
49 | 13
55 | 13
58 | 13
86 | 13
(28 rows)
In this case, we chose 5MB as the size to compact the storage. First, execute the dry run to see the impact:
=> SELECT COMPACT_STORAGE('schema.clients_b1', 5*1024, 'SMALL', true); - compact_storage
----------------------------------------------------------------------------------------------------------------
Task: compact_storage
On node v_scrutinload_node0001:
Projection Name :schema.clients_b1 | selected_storage_containers :50 | selected_files_to_compact :1012 | files_after_compact : 50 | modified_storage_KB :35584
On node v_scrutinload_node0002:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :730 | files_after_compact : 39 | modified_storage_KB :16566
On node v_scrutinload_node0003:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :728 | files_after_compact : 39 | modified_storage_KB :23126
Success
Execute COMPACT_STORAGE() . This uses IO and resources. Performing this by projection allows more control on when it is executed:
=> SELECT COMPACT_STORAGE('schema.clients_b1', 5*1024, 'SMALL', false);compact_storage
----------------------------------------------------------------------------------------------------------------
Task: compact_storage
On node v_scrutinload_node0001:
Projection Name :schema.clients_b1 | selected_storage_containers :50 | selected_files_to_compact :1212 | files_after_compact : 50 | modified_storage_KB :230564
On node v_scrutinload_node0002:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :928 | files_after_compact : 39 | modified_storage_KB :221211
On node v_scrutinload_node0003:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :926 | files_after_compact : 39 | modified_storage_KB :227449
Success
View the new distribution of files:
=> SELECT
WIDTH_BUCKET (used_bytes, 0, 1024*1024*1024, 999) AS bucket, -- 1GB size OF max bucket, 1000 buckets, (i.e. 1MB each bucket)
count(rosid) fileCnt
FROM
storage_containers JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE
schema_name = 'schema'
AND projection_name='clients_b1'
AND bundleindex < 0 -- older versions dont have bundleindex
GROUP BY 1
ORDER BY 1
;
bucket | fileCnt
-------+---------
14 | 1 <== small files are gone, largest one is 14MB ....
15 | 3
16 | 7
17 | 4
18 | 6
19 | 6
20 | 46
21 | 4
23 | 2
24 | 2
25 | 2
29 | 2
31 | 2
32 | 6
40 | 4
41 | 2
42 | 2
44 | 2
45 | 9
48 | 3
49 | 3
55 | 3
58 | 3
86 | 7
(24 rows)
Compare the buddy projection (b1) to see the impact:
=> SELECT
CASE WHEN segment_lower_bound is not null THEN 'SEGMENTED' ELSE 'REPLICATED' END AS type,
schema_name,
projection_name,
max(used_bytes) max_used_bytes,
min(used_bytes) min_used_bytes,
CASE WHEN segment_lower_bound is not null THEN count (distinct colid) ELSE count (distinct colid) END as nCols,
count(distinct rosid) as nFiles
FROM storage_containers JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE bundleindex < 0 -- older versions dont have bundleindex
GROUP BY 1,2,3 ,segment_lower_bound
ORDER BY 7 desc;
type | schema_ | projection_| max_used_bytes | min_used_bytes | nCols | nFiles
----------+---------+------------+----------------+----------------+-------+--------
SEGMENTED | schema | clients_b0 | 47906279 | 14728 | 13 | 611
SEGMENTED | schema | clients_b0 | 100868741 | 18776 | 13 | 572
SEGMENTED | schema | clients_b0 | 59835832 | 15173 | 13 | 572
SEGMENTED | schema | clients_b1 | 61792636 | 16300430 | 3 | 44 <=== better !
SEGMENTED | schema | clients_b1 | 92368520 | 14086909 | 7 | 44
SEGMENTED | schema | clients_b1 | 58541167 | 15202738 | 3 | 43
(6 rows)

