




Vertica Integration with Looker: Tips and Techniques
About Vertica Tips and Techniques
Vertica develops Tips and Techniques documents to provide you with the information you need to use Vertica with third-party products. This document provides guidance using one specific version of Vertica and one version of the third-party vendor's software. While other combinations are likely to work, those versions may not have been tested.
Document Overview
This document provides in-depth guidance for configuring Looker to connect to Vertica. Looker uses the JDBC client driver to connect to Vertica. Engineers have tested:
- Looker on-premises connecting to Vertica on-premises and in the cloud.
- Looker in the cloud connecting to Vertica on-premises and in the cloud.
For more information about connecting Looker to Vertica, see the Vertica Integration with Looker: Connection Guide.
Looker Tips and Recommendations
Derived Tables
Looker has two types of derived tables. These tables are frequently used to generate complex queries with pre-aggregated data and calculations:
- Ephemeral derived table
- Persistent derived table (PDT)
Note For optimal query performance, we recommend using the Vertica tuning techniques described in this document before considering persistent derived tables (PDTs).
For more information on derived tables, see the Looker documentation.
Ephemeral Derived Tables
Ephemeral derived tables are built at query time and only exist for the duration of the query. Ephemeral derived tables are similar to subqueries and are not written to disk. When designing an ephemeral derived table, first execute the query using vsql in Vertica. This allows you to verify that your queries are optimized and run efficiently. After verification, you can create the ephemeral derived table in Looker. We recommend starting with ephemeral derived tables, because they do not require any special Vertica permissions for writing data to disk.
If the performance of the ephemeral derived table becomes too slow over time, use the Vertica tuning techniques to optimize the query before considering creating a Persistent Derived Table (PDT).
For more information about derived tables, see the Looker documentation.
Persistent Derived Tables (PDTs)
PDTs write the results of a query to a Vertica scratch schema. Specify this schema when creating the Looker connection to Vertica. The database user must have write permissions to the schema. For instructions on how to create a scratch schema in Vertica, see the Looker Connecting to Vertica documentation.
PDTs are written to disk and are regenerated at user-specified intervals. As a result, consider the following implications when using a PDT.
- You may incur additional disk storage costs, because additional tables are created and the query results are stored in the database.
- There may be an impact on Vertica licensing, because licensing is based on the volume of data.
- Additional updates to the database configuration, resource management, and user permissions may be required. Also, more database maintenance by the database administrator may be necessary.
- There may be impact on other user’s queries, due to the load of scheduled PDT queries.
- Data in PDTs is as current as the PDT schedule.
- Refresh scheduling may affect performance depending on how long the PDTs take to build, and how many are being built.
- Carefully consider performance when using nested PDTs. This creates additional overhead, as they must be built sequentially
Use the PDT Panel to monitor the PDTs in your application. This panel provides an overview for the current state of all PDTs. For example:
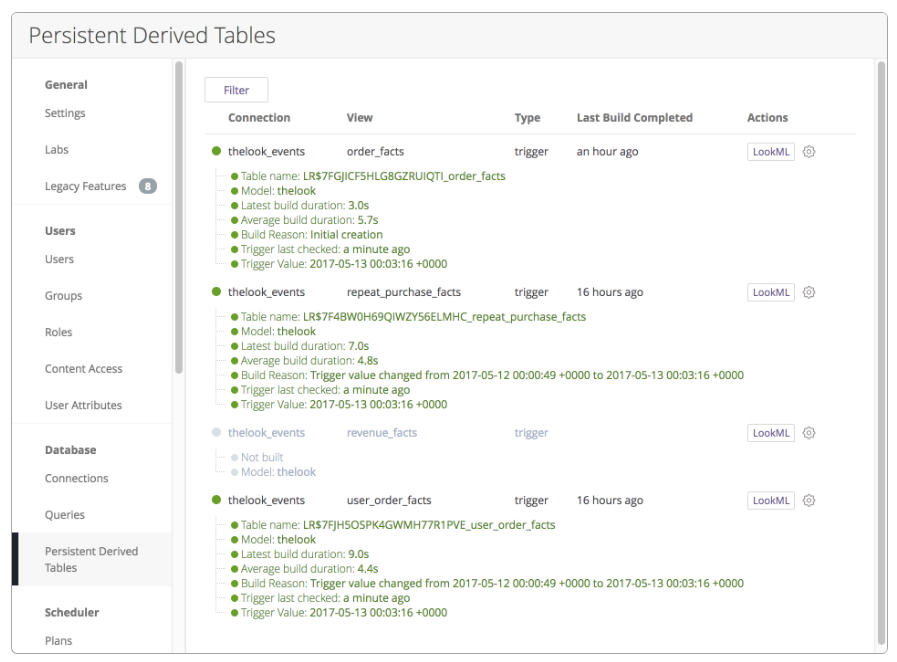
For more information on PDTs, see the Looker documentation.
Looker View Files
Looker can automatically create view files based on tables in your database. However, Looker does not create Looker View Files from views in the database, like flex tables. If you need to connect to a view in Vertica, you must manually change the name of the table to correspond with the name of the view in the view file.
For more information on adding view files, see the Looker documentation.
Table Joins and Relationships
If the Looker administrator specified multiple tables to be included at the time that a new project is generated, Looker will infer the relationships between tables based on column naming conventions. Carefully review the generated LookML model to verify that the relationships Looker created are correct.
You can modify the relationships generated by Looker, and add any that the LookML generator may have missed.
For more information on generating a LookML model, see the Looker documentation.
Caching Behavior
By default, Looker caches query results for one hour. After the query results are in the cache, an identical query returns data from the cache instead of requesting the data from Vertica. If the query requests data that is not in the cache, or if the cache has exceeded its expiration window, the data will be queried from Vertica. Users do not receive updated data for queries that return data in the cache within the specified window.
You can increase or decrease the cache value based on whether or not your data gets updated frequently, and if you need the most recent data.
Note Decreasing the cache value may cause queries to execute more slowly.
If you want Looker to ignore the cache and execute the query in Vertica, select Clear Cache & Run from the context menu.
![]()
For more information on managing cache frequency, see the Looker documentation.
GitHub Integration
Looker is highly integrated with GitHub. The GitHub repositories contain LookML files for your Looker project. LookML is a language for modeling dimensions, fields, aggregates, and relationships. Looker uses models written in LookML to write SQL queries against Vertica.
For an example of Looker working with Vertica, you can download the QuickStart application from GitHub into your Looker instance GitHub site for Vertica QuickStart for Looker. This application uses Vertica VMart sample database.
For more information, see the Vertica QuickStart for Looker document.
For more information on Git integration, see the Looker documentation.
Looker Table Calculations
Looker allows users to create custom calculations using Excel-style syntax. In some cases, such as creating running totals, Table Calculations provide a great way to provide results that may be difficult to attain using SQL only. When possible, fields should be defined within the LookML model by a Data Analyst to ensure that they are optimized for performance, calculated correctly, and are reusable within the organization. Table Calculations are not executed in Vertica, but instead they are resolved within Looker based on the result set of the query.
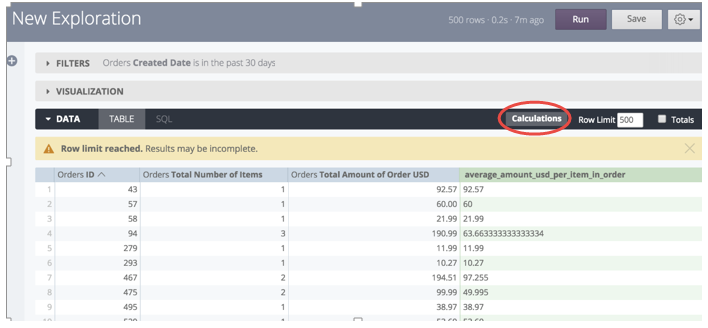
For more information, see the Looker documentation.
Vertica Tuning Recommendations
Vertica has tuning mechanisms that optimize query performance and leverage the speed of your database. This section details those recommendations.
Create a Physical Design with Database Designer
To get the best performance from your Vertica database, create a physical design for your database that optimizes both query performance and data compression. The Vertica Database Designer automatically optimizes your physical design in the following ways:
- Analyzes your logical schema, sample data, and sample queries.
- Creates a physical schema design (projections) that can be deployed automatically or manually.
- Can be run any time for additional optimization without stopping the database.
- Uses strategies to provide optimal query performance and data compression.
Database Designer minimizes the time you spend on manual database tuning and provides the ability to redesign the database incrementally to optimize for changing workloads over time.
For more information, see Workflow for Running Database Designer in the Vertica documentation. If you cannot run Database Designer, follow the recommendations in Redesigning Projections for Query Optimization.
Create a Separate Resource Pool for Looker
To verify that resources are allocated and available for Looker, and not impacted by other processes running on Vertica, create a separate resource pool and user for your Looker application. Creating a separate resource pool isolates the Looker-related workload from other workloads. This resource pool can manage the resources assigned to and needed by Looker. The actual impact of using a separate resource pool depends on the amount of memory on the machine and other factors, such as how many other resource pools are created for other users.
When creating this resource pool, consider the following:
- The amount of memory needed exclusively for Looker (MEMSIZE parameter).
- The amount of memory each node can borrow from another process (MAXMEMORYSIZE parameter).
- The number of reports you need to execute concurrently (MAXCONCURRENCY parameter). MAXCONCURRENCY refers to the maximum concurrent queries. Do not set this parameter to a value higher than the number of machine cores. Consider that other user's pools may be running statements at the same time.
For details on the resource pool parameters, see CREATE RESOURCE POOL in the Vertica documentation.
The following example shows how to create and manage access to the LOOKER_POOL resource pool. This example also shows the commands a database administrator could execute using VSQL:
=> CREATE RESOURCE POOL LOOKER_POOL
MEMORY SIZE ‘4G’ MAXMEMORYSIZE ‘84G’
MAXCONCURRENCY 16;
=> DROP USER looker;
=> DROP SCHEMA looker_s;
=> CREATE SCHEMA looker_s;
=> CREATE USER looker
IDENTIFIED BY ‘my_password’ SEARCH_PATH looker_s;
=> GRANT USAGE ON SCHEMA looker_s TO looker;
=> GRANT USAGE ON SCHEMA PUBLIC TO looker;
=> GRANT USAGE ON SCHEMA online_sales TO looker;
=> GRANT USAGE ON SCHEMA store TO looker;
=> GRANT SELECT ON ALL TABLES IN SCHEMA PUBLIC TO looker;
=> GRANT SELECT ON ALL TABLES IN SCHEMA store TO looker;
=> GRANT SELECT ON ALL TABLES IN SCHEMA
online_sales TO looker;
=> GRANT ALL PRIVILEGES ON SCHEMA looker_s
TO looker WITH GRANT OPTION;
=> GRANT CREATE ON SCHEMA looker_s TO looker;
=> GRANT USAGE ON RESOURCE POOL LOOKER_POOL TO looker;
=> ALTER USER looker RESOURCE POOL LOOKER_POOL;
For more information about resource pools, see Resource Manager in the Vertica documentation.
Enable Native Connection Load Balancing
Native connection load balancing is a Vertica feature that distributes the overhead of query planning among the nodes. Native connection load balancing also spreads the CPU and memory overhead caused by client connections across the hosts in the database. By default, Vertica does not use native connection load balancing.
If you want to use native connection load balancing, you must enable it on both the server side and the client side. To enable native connection load balancing on the server side, follow the steps in About Native Connection Load Balancing in the Vertica documentation.
To enable connection load balancing on the client side, you must enable it when you create a connection to Vertica. See the Vertica Integration with Looker: Connection Guide for steps on connecting to Vertica.
Enable connection load balancing using the JDBC connection parameter ConnectionLoadBalance=1.
You can pass several parameters one after another, separated by an ampersand, as shown here:
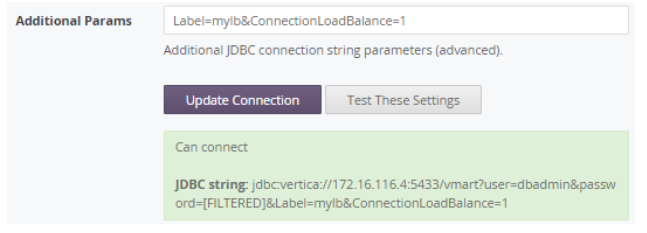
Use Live Aggregate Projections
When you create a live aggregate projection for a table, Vertica automatically aggregates data from that anchor table and loads it into the live aggregate projection. Because the data is already aggregated, retrieving the data directly from the live aggregate projection is faster than retrieving it from the anchor table.
For more information, see Live Aggregate Projections in the Vertica documentation.
Use Flattened Tables to Optimize Join Performance
You can speed up your queries significantly by denormalizing your schema using Vertica flattened tables.
Consider using flattened tables if your queries operate on a large fact table and require many joins from multiple dimension tables. Vertica flattened table functionality allows you to add the columns from your dimension tables into the fact table at load time, avoiding joins at execution time.
Here are some considerations when using flattened tables:
- Denormalized columns use additional disk storage because they query the dimension table for its values and materialize them in the flattened table.
- Data in denormalized columns does not count towards your raw data license limit.
- Data changes in the source tables are not automatically propagated to the flattened table. If data changes in the source tables, your flattened table won’t be immediately updated.
- Denormalized columns created as DEFAULT columns are populated with every new INSERT into the flattened table.
- Denormalized columns created as SET USING columns allow you to decide when to refresh the denormalized data. You can refresh the flattened table at a convenient time with minimal impact to your database.
For more information, see Flattened Tables in the Vertica documentation.

