




K-Prototypes Clustering Using Vertica's In-Built Machine Learning Functions
K-prototypes is a clustering algorithm that combines k-means and k-modes algorithms. While k-means accepts only numerical data and k-modes only categorical data, k-prototypes accepts mixed data that includes both categorical and numerical features. K-prototypes is available in Vertica 12.0.3 and later and supports mixed data out-of-the-box, so there is no need for additional encoding of the categorical variables.
Cluster analysis is a popular technique in statistical data analysis and applies to many use cases, including spam detection, customer behavior analysis, and identifying groups of insurance policyholders with a high average claim cost.
This article demonstrates how to get started with the k-prototypes algorithm using a simple real-world example and the Vertica vsql client program. We will load data into Vertica, clean it, engineer new features, and train a k-prototypes model. After training the model, we will inspect the resulting clusters.
Dataset
In this article, we conduct customer segmentation on the Customer Personality Analysis dataset available on Kaggle. This dataset includes both numerical and categorical features.
First, we create a table with column names and types matching our data:
CREATE TABLE customer_data_campaign (ID INT, Year_Birth INT, Education VARCHAR, Marital_Status VARCHAR, Income INT, Kids INT, Teens INT, Dt_Customer DATE, Recency INT, Wine INT, Fruits INT, Meat INT, Fish INT, Sweets INT, Gold INT, Deals INT, Web INT, Catalog INT, Store INT, WebVisits INT, Cmp INT, Cmp4 INT, Cmp5 INT, Cmp1 INT, Cmp2 INT, Complain INT, Z_CostContact INT, Z_Revenue INT, Response INT);
Then, we can load the data using the following command:
COPY customer_data_campaign FROM LOCAL 'path-to-data' WITH DELIMITER ',';
Rows Loaded
-------------
2240
(1 row)
Let's take a look at the loaded data:
ID | Year_Birth | Education | Marital_Status | Income | Kids | Teens | Dt_Customer | Recency | Wine | Fruits | Meat | Fish | Sweets | Gold | Deals | Web | Catalog | Store | WebVisits | Cmp | Cmp4 | Cmp5 | Cmp1 | Cmp2 | Complain | Z_CostContact | Z_Revenue | Response ----+------------+------------+----------------+--------+------+-------+-------------+---------+------+--------+------+------+--------+------+-------+-----+---------+-------+-----------+-----+------+------+------+------+----------+---------------+-----------+---------- 0 | 1985 | Graduation | Married | 70951 | 0 | 0 | 2013-05-04 | 66 | 239 | 10 | 554 | 254 | 87 | 54 | 1 | 3 | 4 | 9 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 1 | 1961 | Graduation | Single | 57091 | 0 | 0 | 2014-06-15 | 0 | 464 | 5 | 64 | 7 | 0 | 37 | 1 | 7 | 3 | 7 | 5 | 0 | 0 | 0 | 0 | 1 | 0 | 3 | 11 | 1 9 | 1975 | Master | Single | 46098 | 1 | 1 | 2012-08-18 | 86 | 57 | 0 | 27 | 0 | 0 | 36 | 4 | 3 | 2 | 2 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 13 | 1947 | PhD | Widow | 25358 | 0 | 1 | 2013-07-22 | 57 | 19 | 0 | 5 | 0 | 0 | 8 | 2 | 1 | 0 | 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 17 | 1971 | PhD | Married | 60491 | 0 | 1 | 2013-09-06 | 81 | 637 | 47 | 237 | 12 | 19 | 76 | 4 | 6 | 11 | 7 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0
The data contains basic information about the customers of the shop, like their year of birth (Year_Birth), Education, and their usual shopping habits—including the products they tend to buy (Wine, Fruits, Fish products, Meat products, Sweets and Gold), where they buy them (number of Web, Catalog and Store purchases), monthly website visits (WebVisits), how many of the products they purchased were on sale (Deal), and their responses to various campaigns (Cmp, Cmp4, Cmp5, Cmp1, Cmp2, and Response to the final campaign).
Data Preparation
Before we train the model, we need to make sure that the data is ready for training. Let's look at the summaries of the columns to check if there are any NULL values that we need to deal with:
SELECT SUMMARIZE_NUMCOL(* USING PARAMETERS exclude_columns='ID,Education,Marital_Status,Dt_Customer') OVER() FROM customer_data_campaign;
COLUMN | COUNT | MEAN | STDDEV | MIN | PERC25 | MEDIAN | PERC75 | MAX
---------------+-------+---------------------+--------------------+------+----------+----------+------------------+--------
Catalog | 2240 | 2.66205357142857 | 2.92310065553974 | 0 | 0 | 2 | 4 | 28
Cmp | 2240 | 0.0727678571428571 | 0.259813069921895 | 0 | 0 | 0 | 0 | 1
Cmp1 | 2240 | 0.0642857142857143 | 0.245315974334014 | 0 | 0 | 0 | 0 | 1
Cmp2 | 2240 | 0.0133928571428571 | 0.114975606255484 | 0 | 0 | 0 | 0 | 1
Cmp4 | 2240 | 0.0745535714285715 | 0.262728284853561 | 0 | 0 | 0 | 0 | 1
Cmp5 | 2240 | 0.0727678571428572 | 0.259813069921895 | 0 | 0 | 0 | 0 | 1
Complain | 2240 | 0.00937499999999998 | 0.0963911679444975 | 0 | 0 | 0 | 0 | 1
Deals | 2240 | 2.325 | 1.93223750085598 | 0 | 1 | 2 | 3 | 15
Fish | 2240 | 37.5254464285715 | 54.628979402878 | 0 | 3 | 12 | 50 | 259
Fruits | 2240 | 26.3022321428571 | 39.7734337645785 | 0 | 1 | 8 | 33 | 199
Gold | 2240 | 44.021875 | 52.1674389149974 | 0 | 9 | 24 | 56 | 362
Income | 2216 | 52247.2513537906 | 25173.0766609014 | 1730 | 35297.95 | 51375.25 | 68492.6666666667 | 666666
Kids | 2240 | 0.444196428571429 | 0.538398097734594 | 0 | 0 | 0 | 1 | 2
Meat | 2240 | 166.95 | 225.715372511754 | 0 | 16 | 67 | 232 | 1725
Recency | 2240 | 49.109375 | 28.9624528083782 | 0 | 24 | 49 | 74 | 99
Response | 2240 | 0.149107142857143 | 0.356273586408479 | 0 | 0 | 0 | 0 | 1
Store | 2240 | 5.79017857142857 | 3.25095814567443 | 0 | 3 | 5 | 8 | 13
Sweets | 2240 | 27.0629464285714 | 41.2804984878549 | 0 | 1 | 8 | 33 | 263
Teens | 2240 | 0.506249999999999 | 0.544538230769876 | 0 | 0 | 0 | 1 | 2
Web | 2240 | 4.08482142857144 | 2.7787141473881 | 0 | 2 | 4 | 6 | 27
WebVisits | 2240 | 5.31651785714284 | 2.42664500954728 | 0 | 3 | 6 | 7 | 20
Wine | 2240 | 303.935714285714 | 336.597392605372 | 0 | 23.75 | 173.5 | 504.25 | 1493
Year_Birth | 2240 | 1968.80580357143 | 11.9840694568858 | 1893 | 1959 | 1970 | 1977 | 1996
Z_CostContact | 2240 | 3 | 0 | 3 | 3 | 3 | 3 | 3
Z_Revenue | 2240 | 11 | 0 | 11 | 11 | 11 | 11 | 11
(25 rows)
SELECT SUMMARIZE_CATCOL(Education) OVER() FROM customer_data_campaign;
CATEGORY | COUNT | PERCENT
------------+-------+------------------
| 2240 | 100
Graduation | 1127 | 50.3125
PhD | 486 | 21.6964285714286
Master | 370 | 16.5178571428571
2n Cycle | 203 | 9.0625
Basic | 54 | 2.41071428571429
(6 rows)
SELECT SUMMARIZE_CATCOL(Marital_Status) OVER() FROM customer_data_campaign;
CATEGORY | COUNT | PERCENT
----------+-------+--------------------
| 2240 | 100
Married | 864 | 38.5714285714286
Together | 580 | 25.8928571428571
Single | 480 | 21.4285714285714
Divorced | 232 | 10.3571428571429
Widow | 77 | 3.4375
Alone | 3 | 0.133928571428571
Absurd | 2 | 0.0892857142857143
YOLO | 2 | 0.0892857142857143
(9 rows)
SELECT COUNT(Dt_Customer) FROM customer_data_campaign;
COUNT
-------
2240
(1 row)
We see that count of non-null values for the Income column is smaller than other columns, 2216 instead of 2240. We could apply some more complex techniques to deal with this data, but for simplicity, let's just remove rows where Income is NULL:
DELETE FROM customer_data_campaign WHERE Income IS NULL;
OUTPUT
--------
24
(1 row)
Since there is only one unique value for each of the Z_CostContact and Z_Revenue columns, we will exclude these columns when training the model.
To simplify our analysis, let's create a view for this data with a new CustomerAgeRange categorical column that groups the customers by their age range:
CREATE VIEW customer_data_view AS SELECT *, (CASE WHEN (YEAR(NOW()) - Year_Birth) < 30 THEN '18-29' WHEN (YEAR(NOW()) - Year_Birth) < 50 THEN '30-49' WHEN (YEAR(NOW()) - Year_Birth) < 70 THEN '50-69' ELSE '> 60' END) AS AgeRange FROM customer_data_campaign;
As our variables are of different magnitudes (categorical variables have cost of 0 or 1, while the difference in income can be in thousands), we need to normalize the data before proceeding:
SELECT NORMALIZE_FIT('norm_fit_model', 'customer_data_view', '*', 'minmax' USING PARAMETERS exclude_columns='ID, Dt_Customer, Year_Birth, Education, Marital_Status, AgeRange', output_view='customer_campaign_norm');
NORMALIZE_FIT
---------------
Success
(1 row)
Now our dataset is ready for training a k-prototypes model.
Before we use a model to inform our marketing decisions, we first need to find the optimal number of clusters, which in our case means "how many groups of customers do we have". In some cases, k is known at the start, but here we will use the elbow method to find our k. We train 8 models, each with a different value of k, keeping all other hyper-parameters constant:
SELECT kprototypes('model_k_x', 'customer_data_campaign_norm', '*' , x USING PARAMETERS max_iterations=100, key_columns='ID', exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue');
SELECT get_model_summary(USING parameters model_name='model_k_x');
Here is the output for k =2:
SELECT kprototypes('model_k_2', 'customer_campaign_norm', '*' , 2 USING PARAMETERS max_iterations=100, key_columns='ID', exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue', output_view='clustered_k_2');
kprototypes
----------------------------
Finished in 13 iterations
(1 row)
SELECT get_model_summary(USING parameters model_name='model_k_2');
get_model_summary
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
=======
centers
=======
education |marital_status| income | kids | teens |recency | wine | fruits | meat | fish | sweets | gold | deals | web |catalog | store |webvisits| cmp | cmp4 | cmp5 | cmp1 | cmp2 |complain|response|agerange
----------+--------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+---------+--------+--------+--------+--------+--------+--------+--------+--------
Graduation| Married | 0.07312| 0.22576| 0.32873| 0.49272| 0.18975| 0.11210| 0.07900| 0.11940| 0.08670| 0.12513| 0.17046| 0.15072| 0.08397| 0.43312| 0.27760 | 0.05308| 0.07502| 0.04034| 0.04459| 0.01062| 0.00849| 0.11111| 50-69
Graduation| Together | 0.08100| 0.21233| 0.11893| 0.49923| 0.23004| 0.16824| 0.12815| 0.19093| 0.13214| 0.15779| 0.12752| 0.15235| 0.11550| 0.46930| 0.24545 | 0.10959| 0.07223| 0.13076| 0.09838| 0.01868| 0.01121| 0.21918| 30-49
=======
metrics
=======
Evaluation metrics:
Total Sum of Squares: 5707.2147
Within-Cluster Sum of Squares:
Cluster 0: 2929.7496
Cluster 1: 1953.8979
Total Within-Cluster Sum of Squares: 4883.6475
Between-Cluster Sum of Squares: 823.56717
Between-Cluster SS / Total SS: 14.43%
Number of iterations performed: 13
Converged: True
Call:
kprototypes('public.model_k_2', 'customer_campaign_norm', '*', 2
USING PARAMETERS exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue', max_iterations=100, epsilon=0.0001, gamma=1, init_method='random', distance_method='euclidean', output_view='clustered_k_2', key_columns='ID')
(1 row)
The following plot shows the Total Within-Cluster Sum of Squares for each k. Even though the curve does not have a significant elbow, we can see that increasing k to greater than 4 does not significantly improve the model.
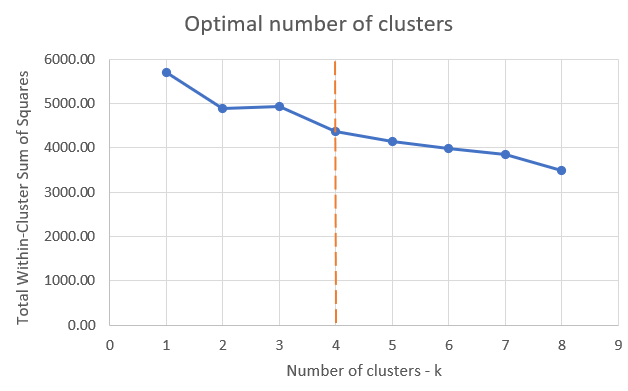
Let's look at the clusters when k=4:
SELECT get_model_attribute(USING parameters model_name='model_k_4', attr_name='centers') ORDER BY income;; education | marital_status | income | kids | teens | recency | wine | fruits | meat | fish | sweets | gold | deals | web | catalog | store | webvisits | cmp | cmp4 | cmp5 | cmp1 | cmp2 | complain | response | agerange ------------+----------------+--------------------+--------------------+--------------------+-------------------+-------------------+--------------------+--------------------+-------------------+--------------------+-------------------+--------------------+-------------------+--------------------+-------------------+-------------------+--------------------+--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+---------- Graduation | Married | 0.0617337131689543 | 0.32492795389049 | 0.147694524495677 | 0.504948621663319 | 0.100241086646425 | 0.0957670195357189 | 0.0580929708056635 | 0.101782515327184 | 0.0713311481180016 | 0.10213489904567 | 0.148030739673391 | 0.118369089550646 | 0.0584088102099629 | 0.364331633784083 | 0.296685878962536 | 0.0734870317002882 | 0.0144092219020173 | 0.00288184438040346 | 0.00144092219020173 | 0.00144092219020173 | 0.0144092219020173 | 0.0749279538904899 | 30-49 Graduation | Married | 0.0750482928810095 | 0.217258883248731 | 0.352791878172589 | 0.486181613085166 | 0.189783116472472 | 0.1241129505395 | 0.0823935849334216 | 0.127515042235854 | 0.0962762041306622 | 0.132653351677025 | 0.17414551607445 | 0.154427523970671 | 0.0892313270485859 | 0.439437719640765 | 0.273045685279188 | 0.065989847715736 | 0.0629441624365482 | 0.0233502538071066 | 0.0314720812182741 | 0.00812182741116751 | 0.00710659898477157 | 0.114720812182741 | 50-69 Master | Together | 0.0859822442467238 | 0.122252747252747 | 0.274725274725275 | 0.531551781551782 | 0.280677962359141 | 0.14390634491137 | 0.123873228221054 | 0.191193941193941 | 0.116265413975338 | 0.162738351990688 | 0.153663003663004 | 0.178876678876679 | 0.125686813186813 | 0.540786136939983 | 0.234752747252747 | 0.0412087912087912 | 0.0851648351648352 | 0.043956043956044 | 0.0302197802197802 | 0.00549450549450549 | 0.00824175824175824 | 0.104395604395604 | > 60 Graduation | Married | 0.117301123543308 | 0.0317919075144509 | 0.0578034682080925 | 0.429380510305366 | 0.544305022668406 | 0.302872745229035 | 0.277255591857251 | 0.324815319034972 | 0.242509817764638 | 0.24698827724056 | 0.0755298651252408 | 0.207664311710554 | 0.215111478117258 | 0.614495331258337 | 0.167919075144509 | 0.184971098265896 | 0.352601156069364 | 0.699421965317919 | 0.572254335260116 | 0.109826589595376 | 0.00578034682080925 | 0.751445086705202 | 30-49 (4 rows)
The data is still normalized, so let's reverse the normalization:
CREATE TABLE centers AS SELECT get_model_attribute(USING parameters model_name='model_k_4', attr_name='centers'); SELECT REVERSE_NORMALIZE(* USING PARAMETERS model_name='norm_fit_model') FROM centers ORDER BY income; education | marital_status | income | kids | teens | recency | wine | fruits | meat | fish | sweets | gold | deals | web | catalog | store | webvisits | cmp | cmp4 | cmp5 | cmp1 | cmp2 | complain | response | agerange ------------+----------------+------------------+--------------------+-------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+--------------------+--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+---------- Graduation | Married | 42778.9682997118 | 0.64985590778098 | 0.295389048991354 | 49.9899135446686 | 149.659942363112 | 19.0576368876081 | 100.210374639769 | 26.3616714697406 | 18.6887608069164 | 32.7853025936599 | 2.22046109510087 | 3.19596541786744 | 1.63544668587896 | 4.73631123919308 | 5.93371757925072 | 0.0734870317002882 | 0.0144092219020173 | 0.00288184438040346 | 0.00144092219020173 | 0.00144092219020173 | 0.0144092219020173 | 0.0749279538904899 | 30-49 Graduation | Married | 51632.3116751269 | 0.434517766497462 | 0.705583756345178 | 48.1319796954315 | 283.346192893401 | 24.6984771573604 | 142.128934010152 | 33.0263959390863 | 25.2243654822335 | 42.5817258883249 | 2.61218274111675 | 4.16954314720812 | 2.49847715736041 | 5.71269035532995 | 5.46091370558376 | 0.065989847715736 | 0.0629441624365482 | 0.0233502538071066 | 0.0314720812182741 | 0.00812182741116751 | 0.00710659898477157 | 0.114720812182741 | 50-69 Master | Together | 58902.6895604396 | 0.244505494505494 | 0.549450549450549 | 52.6236263736264 | 419.052197802198 | 28.6373626373626 | 213.681318681319 | 49.5192307692308 | 30.4615384615385 | 52.239010989011 | 2.30494505494506 | 4.82967032967033 | 3.51923076923077 | 7.03021978021978 | 4.69505494505495 | 0.0412087912087912 | 0.0851648351648352 | 0.043956043956044 | 0.0302197802197802 | 0.00549450549450549 | 0.00824175824175824 | 0.104395604395604 | > 60 Graduation | Married | 79727.7398843931 | 0.0635838150289017 | 0.115606936416185 | 42.5086705202312 | 812.647398843931 | 60.271676300578 | 478.265895953757 | 84.1271676300578 | 63.5375722543353 | 79.2832369942197 | 1.13294797687861 | 5.60693641618497 | 6.02312138728324 | 7.98843930635838 | 3.35838150289017 | 0.184971098265896 | 0.352601156069364 | 0.699421965317919 | 0.572254335260116 | 0.109826589595376 | 0.00578034682080925 | 0.751445086705202 | 30-49 (4 rows)
We can now take a look at the different clusters, hopefully identifying trends within each group of customers that can lead to separate campaigns. For example, the first cluster consists of customers who are mainly younger, married, and lower-income couples with kids, who generally buy less than other groups of customers. Inspecting this cluster further, we see that this group visits the company's website quite often, which indicates that this might be the best venue for marketing campaigns for this group. Now looking at the second group of customers, we notice they are not very responsive to marketing campaigns, but they do seem to follow the deals. The customers from the third cluster tend to be Master's graduates who buy a significant amount of products from the store. However, these customers do not respond to marketing campaigns and most of their purchases are in-store. In the last cluster, we have a high-earner, high-spender group of customers. This group shops a lot and is quite responsive to all campaigns, but does not shop based on sales.
Summary
K-means is one of the most popular machine learning algorithms, but it can be limited due to its restriction to only numerical data. K-prototypes avoids this restriction by allowing the clustering of mixed datasets that include both categorical and numerical features.
In this article, we loaded data into Vertica, cleaned and normalized the data, and found the optimal k by training multiple models. Throughout this article, we focused on the clustering of customers of a store, but k-prototypes can be used on any mixed data set. Other possible use cases include clustering of trips on a ride-sharing app, user behavior on a website, and analysis of injuries in truck crashes.

