




Implement Multi-Tenancy Using Vertica
Overview
Vertica allows you to design and implement multi-tenancy systems to service multiple customers. Evaluate your performance, storage, and security needs to choose a model that best suits your data design and workload. Carefully consider the number of tables and columns that each tenant requires over time. Tables and columns translate into catalog objects. If the storage requirements for catalog objects increase, the memory size increases. In addition, a larger catalog can negatively affect database performance.
This document provides best practices for Vertica multi-tenant environment. The document describes why you might implement multi-tenancy and three approaches for configuring your Vertica database to support multiple tenants.
- About multi-tenancy
- Advantages and disadvantages of multi-tenancy
- Using Vertica for multi-tenancy
- Multiple schemas: One schema per tenant
- One schema: Add tenant_id field to base tables
- Multiple clusters: One cluster per tenant
Introduction to Multi-Tenancy
In a Vertica multi-tenant environment, one instance of a Vertica database supports multiple tenants accessing the data. Each tenant may access its own data set or multiple tenants may share specific data sets.
Software as a Service (SaaS) environments use multi-tenancy. A Vertica customer has database that provides services to several customers. Typically, the database has multiple data sets, each of which corresponds to a custom service provided to each customer (tenant).
Consider an example: XYZ Company has a domain www.xyz.com. XYZ Company has multiple customers that share that web space, but use their own URLs. ABC Company owns www.abc.com, and DEF Company owns www.def.com. XYZ Company configures a Vertica database such that each domain has its own data set, defined as schemas, in that database. Each customer can load, manipulate, and analyze only their own data. They cannot access data in any other schema.
This configuration saves money for customers of the XYZ Company. The XYZ Company incurs the costs of purchasing a Vertica database and hiring database administrators instead of its customers. The XYZ Company manages the database and provides services to its customers.
Advantages and Disadvantages of Using Vertica for Multi-Tenancy
Use Vertica multi-tenancy if it suits your business needs.
| Advantages | Disadvantages |
|---|---|
|
With Vertica you can create a multi-tenant environment using these features:
|
If your environment requires a SaaS multi-tenancy model, take into consideration the following issues with Vertica and multi-tenancy:
|
Three Approaches to Multi-Tenancy in Vertica
You can choose from three approaches to configure multi-tenancy in a Vertica database. Each approach has its advantages and disadvantages. Vertica recommends that you carefully evaluate each approach to see which approach best suits your environment.
Multiple Schemas: One Schema per Tenant
In this approach, you create a schema for each tenant. You configure role-level and user-level security to ensure that each tenant has access to only its specific data.
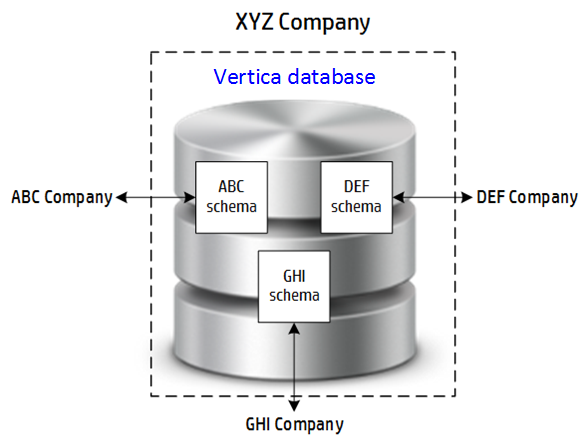
When to Use
Use the one schema per tenant approach for true multi-tenancy. This approach balances risk, flexibility, performance, and cost for a Vertica multi-tenancy environment. It is easy to set up and manage. You can use user-defined resource pools because the tenant workload is predictable. This approach is appropriate when tenants require direct and secure access to the database from their applications or clients.
Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
|
|
One Schema: Add tenant_id Field to Base Tables
In this approach, you assign a unique ID to each tenant. Each table contains a tenant_id field and stores data for all the tenants. The tenants access data they have read permissions to, because every query specifies the tenant_id. You must implement security filters at the record level or at the role level to maintain data privacy across tenants.
The following query returns all rows in the click_data table for tenant ABC:
SELECT * FROM click_data WHERE tenant_id="ABC";
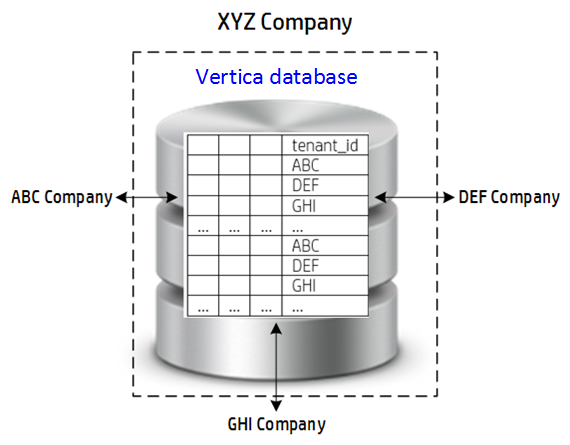
When to Use
Use the one-schema approach when Vertica is a backend database for hosted tenants. In this approach, the same table stores related records, regardless of tenant_id. If you want to analyze all the data from all the tenants, that data is available in a single table.
For example, for the XYZ Company, the click_data table records the number of clicks per day per tenant. You need to access only click_data table to analyze this data across all the tenants. For less than 10 tenants, you can achieve excellent performance by implementing RLE encoding and using ORDER BY tenant_id. This approach accommodates many tenants. However, you must evaluate the impact of the workloads and the catalog sizes of individual tenants.
The one-schema approach is effective when the tenant workloads use queries with memory of less than 5 GB. Tenants in different geographical time zones do not require resources concurrently. The tenants with same physical projections can affect other tenants service-level agreements (SLAs). The tenants sharing same schema and tables are less secure. The one-schema approach is suited to fixed applications where the data and the reports are secure and controlled by one application.
Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
|
|
Multiple Clusters: One Cluster per Tenant
In this approach, you set up multiple clusters, one for each tenant. Each cluster has an instance of Vertica running on it. Each tenant has full isolation from other clients and full access to the resources on their cluster.
Using multiple clusters automates cluster provisioning and scales clusters effectively. It is easy and inexpensive in the cloud to add new clusters. Separate clusters for each tenant provides full isolation for each tenant. Isolating tenants eliminates impact from noisy neighbors.

When to Use
Use the multiple-cluster approach to multi-tenancy when Vertica is hosted in the cloud. This approach is favorable when tenant workloads are varied and unpredictable.
Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
|
|
Conclusion
We saw three approaches, each with its advantages and disadvantages:
- Multiple schemas: One schema per tenant: A design with independent schemas is easy to maintain but has limitations on the number of tenants you can host in the same cluster.
- One schema: Add tenant_id field to base tables: A design with one schema where all tables have a
tenant_idfield makes cross-tenant data analysis easy. However, this approach requires careful access management for each tenant's data for security and database performance. - Multiple clusters: One cluster per tenant: A design with a separate cluster per client can be expensive and time-consuming to implement and maintain.
Make sure to review this information and evaluate your database needs in order to implement a design that works best for your use case.

