




Eon Mode Hot Backup
Overview
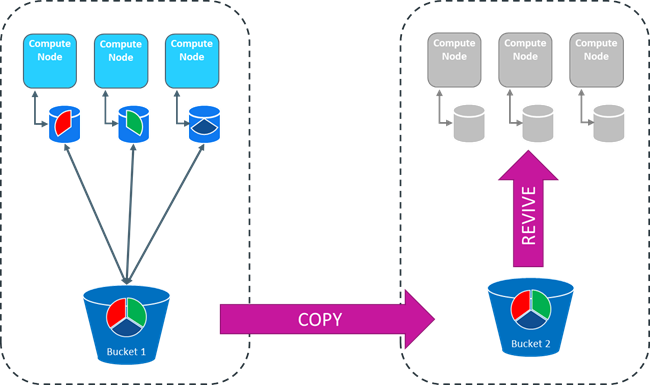
In an Eon Mode database, data storage is separated from compute resources. Vertica in Eon Mode can be deployed in a cloud environment such as AWS S3 and on-premises in an object store such as Pure Storage on Flashblade, HDFS, etc. This separation of compute from storage may incline DevOps to back up the Eon mode database by simply copying from the communal storage and reviving this copy. This could be a backup or a replication strategy. Conceptually, this is a great idea and will work. However, there are some important details to consider. This article provides recommendations for backups and steps to perform an Eon Mode hot back up which may be more beneficial.
Eon Mode “Hot Backup” process was available as a beta feature from Vertica version 10.x and is now supported from version 11.0 and later.
Common Use Cases
The following is a list of common use cases:
- On-going incremental back-up: Revive the database and use it like a restored back-up.
- Upgrade Support: Create a replica through a "snapshot". You can revive the replica in an upgraded Vertica version, review it, and then move the workload from the old database and old version to the new database replica and new version.
- Bucket replication: Use on-prem or cloud storage bucket replication utilities to move data from one bucket to another via fast data sync while keeping data consistency.
- Keeping Eon Mode DB snapshot consistent: Use repeated Sync and Suspend Eon Mode DB.
- Fast Eon Mode DB snapshot: Provides the following advantages over a remote host backup:
- Speed: Creating a database snapshot using one of the storage utilities, such as Pure Storage fast-copy snapshot, is significantly faster than a remote host full backup. This can be used as an alternative to EE Hard-Link Local Backup which does not exist on S3 Object Storage.
- Reduced network activities: Snapshot via Eon Mode Hot Backup minimizes network load because it does not require rsync to copy files to a remote backup host.
Consistency Considerations
The Eon Mode Catalog is a metadata store maintained in the memory of each of the nodes of the cluster. The metadata describes objects in a database, such as tables, projections, checkpoints, transaction logs, and more. The catalog is periodically written to communal storage (“synchronized”), either on a default cadence every five (5) minutes or when certain commands execute. Immediately after the catalog is written, the database in communal storage is consistent. However, synchronization does not last long with an operational database, thus consistency does not last long.
It might be acceptable for the catalog to become inconsistent with the latest changes if the underlying data files (ROS files) are unchanged. Knowing that ROS files are immutable gives some confidence that the catalog refers to data that will not change. Knowing that new data is loaded into new files should not matter to the consistency of a copy taken in the past. However, it is the old ROS files that we must consider. ROS files are deleted when data is compacted (“mergeout”) and deleted when objects are deleted. Therefore, it is important that the copy process be a true “snapshot” and that no part of the copy process runs independently. For example, it is not a good idea to leverage a storage vendor’s background bucket replication because it is likely to delete ROS files in the target bucket (as they are deleted in the source bucket) when those ROS files remain critical to the backup.
We recommend you to preserve all the files with the catalog as a single operation to maintain consistency. For this, you need to freeze catalog operations while taking the copy. Following are commands to change the catalog sync interval, force a catalog sync, and monitor the sync:
- Change the catalog sync interval by updating CatalogSyncInterval
- Force a catalog sync by calling sync_catalog()
- Monitor the sync process via Vertica System table dc_catalog_persistence_events
Before starting the backup or snapshot, you must ensure that the persistent copy of the catalog contains all recent changes and then stop its progress on the communal storage. You can use the following processes to make sure the database's catalog is up to date to the time when backup starts by stopping the catalog sync between the nodes and its communal storage copy. While the backup is running, the local catalog copy on each node continues to advance, but the catalog copy on the communal storage does not until after the backup or snapshot is created.
- To start a Hot Backup, you must finish the latest catalog sync and then postpone catalog sync for a few hours.
- To end a Hot Backup, you must enable the catalog sync automation default again.
Other Considerations
- In Enterprise Mode you can recover a database to a consistent state as of Last Good Epoch (LGE). In EON Mode there is no LGE. When you revive the Eon Mode database clone, its catalog version will be the one when sync is done right before the clone. All catalog and database changes after catalog sync paused are not cloned.
- If your cluster crashes during the time the catalog sync is disabled, you could only revive to the catalog version before catalog sync was disabled. The longer you pause the sync, the more catalog and database transactions you may lose if your local catalog is corrupted, and you will need to revive from the communal storage.
- Local catalog on the nodes is always up to date after commit regardless of the sync state.
- Even if Vertica process crashes or Vertica cluster goes down, long sync interval will not cause damage, however hardware failure matters.
- If one node goes down it does not matter because every shard is subscribed by two nodes assuming K-Safe is 1.
- It is the Eon Mode database administrator’s responsibility to verify catalog sync renewal after backup or snapshot ends.
Important: Routinely Check Catalog Sync
The longer you pause the sync, the more catalog and database transactions you may lose if your local catalog is corrupted or deleted. To reduce the risk, we recommend you to check if the catalog sync is paused as a daily routine.
In the following check example, notice that the last sync for nodes 01 - 24 was in the last 5 minutes time frame.
Nodes with sync_catalog_version value -1 were not synchronized. Thus, nodes 25 - 30 never synchronized, because those nodes are part of a secondary subcluster.
select * from catalog_sync_state; node_name sync_catalog_version earliest_checkpoint_version sync_trailing_interval last_sync_at ------------------- -------------------- --------------------------- ---------------------- ------------------- v_mydb_node0001 194529968 193747480 2256 2021-09-05 14:26:56 v_mydb_node0002 194528984 193714726 3240 2021-09-05 14:23:59 v_mydb_node0003 194529844 193742734 2380 2021-09-05 14:26:29 v_mydb_node0004 194529797 193760761 2427 2021-09-05 14:25:48 v_mydb_node0005 194529968 193748543 2256 2021-09-05 14:26:55 v_mydb_node0006 194529970 193742132 2254 2021-09-05 14:27:09 v_mydb_node0007 194529968 193783489 2256 2021-09-05 14:26:53 v_mydb_node0008 194529828 193780272 2396 2021-09-05 14:26:19 v_mydb_node0009 194529967 193756834 2257 2021-09-05 14:26:49 v_mydb_node0010 194529495 193766752 2729 2021-09-05 14:25:18 v_mydb_node0011 194529822 193782671 2402 2021-09-05 14:26:16 v_mydb_node0012 194529967 193789813 2257 2021-09-05 14:26:47 v_mydb_node0013 194529967 193788900 2257 2021-09-05 14:26:47 v_mydb_node0014 194529968 193367115 2256 2021-09-05 14:27:03 v_mydb_node0015 194529807 193792960 2417 2021-09-05 14:26:01 v_mydb_node0016 194529963 193776940 2261 2021-09-05 14:26:33 v_mydb_node0017 194529815 193751857 2409 2021-09-05 14:26:07 v_mydb_node0018 194529819 193315002 2405 2021-09-05 14:26:12 v_mydb_node0019 194529969 193324735 2255 2021-09-05 14:27:05 v_mydb_node0020 194529822 193761734 2402 2021-09-05 14:26:15 v_mydb_node0021 194529373 193406043 2851 2021-09-05 14:25:14 v_mydb_node0022 194529355 193776027 2869 2021-09-05 14:25:12 v_mydb_node0023 194529968 193760761 2256 2021-09-05 14:26:57 v_mydb_node0024 194529971 193321333 2253 2021-09-05 14:27:17 v_mydb_node0025 -1 -1 194532225 2000-01-01 02:00:00 v_mydb_node0026 -1 -1 194532225 2000-01-01 02:00:00 v_mydb_node0027 -1 -1 194532225 2000-01-01 02:00:00 v_mydb_node0028 -1 -1 194532225 2000-01-01 02:00:00 v_mydb_node0029 -1 -1 194532225 2000-01-01 02:00:00 v_mydb_node0030 -1 -1 194532225 2000-01-01 02:00:00
Creating Database Replica via Pure Storage S3 Fast Copy
Pure Storage S3 copy processes within the same FlashBlade Bucket now use “reference-based copies” where data is not physically copied so the process is faster. Pure Fast Copy does not apply to S3 uploads and copying or copying between different buckets.
Using Eon Mode Hot Backup with Pure Storage Purity//FB FlashBlade operating system V3.x can use FlashBlade Pure’s unified scale-out object storage systems. Two FlashBlade arrays or a FlashBlade and an AWS S3 target can be connected, which enables asynchronous object replication from one bucket on the array to a bucket on the second array or S3 target.
Creating a Full S3 Bucket Replica via Pure’s Fast-Copy Snapshot on Another Cluster
- Stop syncing original database.
For example,
alter database default SET CatalogSyncInterval = '6 hours';
select hurry_service('System','TxnLogSyncTask');Wait until the following count is zero:
select count(*) from system_services where service_name='TxnLogSyncTask' and last_run_end is null;
- Replicate via Pure Storage fast-copy utility (keep files for reference to ensure that no deletes are initiated by Pure).
- Renew sync.
alter database default clear CatalogSyncInterval; select hurry_service('System','TxnLogSyncTask'); - Stop the database.
- Drop the database.
- Revive the database on the new replica.
admintools -t revive_db -x auth_params.conf \ --communal-storage-location=s3://communal_store_path \ -s host1_ip,... -d database_name
- Start the database from the new replica to check it.
- Stop the database on the new replica.
- Revive from the original database.
- Start the original database.
Note If you plan to stop/drop the database or VER-78750 is installed, hurry_service call is not necessary after resetting the CatalogSyncInterval knob.
Pure Fast-Copy Snapshot Process Transcript
# Stop catalog sync on our prod db named soda
# And set sync interval to 6 hours, as clone usually runs about 5 minutes
alter database default set CatalogSyncInterval = '6 hours';
select hurry_service('System','TxnLogSyncTask');
select count(*) from system_services where service_name='TxnLogSyncTask' and last_run_end is null;
# Make sure the above returns zero
# Create the clone
docker run -d --network=host --name=s5cmd -v /home/rgolovak/.aws:/root/.aws peakcom/s5cmd --endpoint-url=http://<pure_ip> cp 's3://vertica/prod/soda/*' s3://vertica/clones/revive/soda/
# For this to work properly , need to set sysctls (make sure return code is 0):
sysctl net.ipv4.ip_local_port_range="16384 65535"
sysctl net.ipv4.tcp_fin_timeout=20
sysctl net.ipv4.tcp_tw_reuse=1
# Resume catalog sync:
alter database default clear CatalogSyncInterval;
select hurry_service('System','TxnLogSyncTask');
# Stop DB:
admintools -t stop_db -d soda -p <db_pass> -F
# Drop DB:
admintools -t drop_db -d soda
# Manually delete depot path on all nodes:
# NOTE: In the future this will be done automatically as part of the drop DB process
rm -rf /date/depot/soda
# Revive from clone path:
admintools -t revive_db --communal-storage-location=s3://vertica/clones/revive/soda -s <our_cluster_spread_ips> -d soda -x /home/dbadmin/auth_params.conf
# NOTE: remove --force so that revive is much faster (depot must be clean)
# Start DB on the new replica
admintools -t start_db -d soda -p <db_pass> -F
# After validating data is good you can stop, drop, delete depot of clone instance, and revive back to original prod DB.
Eon Mode on HDFS Hot Backup Process Transcript
# Python script example to create an Eon Mode DB backup on-prem HDFS on any
# storage infrastructure. Eon Mode on HDFS and Eon Mode FS for fast backup
# use HDFS snapshot capabilities to get fast and as many snapshots as you
# want without the need for a full backup nor copy files to
# external storage or bucket.
import vertica_python
import sys
import pyhdfs
import time
queries = {
"Disable automatic sync": "ALTER DATABASE default SET CatalogSyncInterval = '10 years';",
"Hurry_catalog_sync": "SELECT hurry_service('System','TxnLogSyncTask');",
"Check_if_can_sync": "SELECT count(*) FROM system_services "
"WHERE service_name='TxnLogSyncTask' AND last_run_end IS NULL;",
"Sync catalog": "SELECT sync_catalog();",
"get_communal_location": "SELECT location_path FROM storage_locations WHERE sharing_type='COMMUNAL';",
"Enable sync": "ALTER DATABASE default clear CatalogSyncInterval;",
}
def get_vertica_conn(db, user, passwd, host, port, session_label):
try:
# Vertica connection
connection_config_dict = {
'user': user,
'password': passwd,
'host': host,
'port': port,
'database': db,
# autogenerated session label by default,
'session_label': session_label
}
return vertica_python.connect(**connection_config_dict)
except Exception as e:
print("Failed to return a connection to {}: {}".format(host, e), flush=True)
sys.exit(1)
def disable_catalog_sync(vrt_conn):
print("Disabling catalog sync service ...")
query_name = "Disable automatic sync"
vrt_conn.execute(queries[query_name])
query_name = 'Hurry_catalog_sync'
vrt_conn.execute(queries[query_name])
query_name = 'Check_if_can_sync'
res = vrt_conn.execute(queries[query_name])
while int(res.fetchone()[0]) != 0:
time.sleep(5)
res = vrt_conn.execute(queries[query_name])
# Manually sync catalog to communal storage again to ensure
# revive version is bumped to the latest
query_name = 'Sync catalog'
res = vrt_conn.execute(queries[query_name])
print(res.fetchone()[0])
def enable_catalog_sync(vrt_conn):
print("Enabling catalog sync service")
query_name = 'Enable sync'
vrt_conn.execute(queries[query_name])
query_name = 'Hurry_catalog_sync'
vrt_conn.execute(queries[query_name])
def get_communal_location(vrt_conn):
query_name = 'get_communal_location'
res = vrt_conn.execute(queries[query_name]).fetchone()
hdfs_location = res[0]
print("hdfs location = {}".format(hdfs_location))
return hdfs_location
# Creating hdfs snapshot backup
def run_backup(cluster, hdfs_location):
print("Starting hdfs backup for vertica cluster {}.format(cluster)")
snapshot_name = f"{cluster}_{time.strftime('%Y%m%d-T%H%M%S')}"
hdfs_client = pyhdfs.HdfsClient(user_name='dbadmin')
hdfs_client.create_snapshot(path=hdfs_location, snapshotname=snapshot_name)
print(f"Created snapshot {snapshot_name}")
return snapshot_name
def main():
print("START BACKUP EON JOB")
# init Vertica connection
try:
conn_vertica = get_vertica_conn(db='XXX', user='dbadmin', passwd='XXX', host='XXX', port=5433, session_label='eon_hotbackup')
vrt_conn = conn_vertica.cursor()
except Exception as err:
print("failed to connect to vertica cluster")
exit(2)
# Get communal storage path
hdfs_location = get_communal_location(vrt_conn)
# Disable catalog sync service
disable_catalog_sync(vrt_conn)
# Execute the hot backup command
snapshot_name = run_backup('vrta', hdfs_location)
# Enable catalog sync service back
enable_catalog_sync(vrt_conn)
# close Vertica connection
conn_vertica.close()
print("END BACKUP EON JOB")
if __name__ == '__main__':
try:
main()
except Exception as err:
print ('Backup EON exception: %s' % str(err))
sys.exit(2)

