




ETL Considerations for Vertica in Eon Mode
Overview
In an Enterprise Mode, data is stored locally and distributed across all nodes to reduce query times. Vertica's Eon Mode uses Amazon S3 for storing data. Amazon S3 provides a different kind of storage paradigm. The Eon Mode is a subscription-based model where data storage is separated from computing and the cost of storage is low. Additionally, users are not responsible for tasks such as backup and data life cycle management. What needs more attention here is the financial and performance cost of data access as seen at Amazon S3 Pricing. In most cases, data access is the main objective of storing data.
When designing workloads against storage systems like S3, pay attention to ETL processes which require significant and frequent data access. If data access is not efficient it can wipe out the savings gained from data storage and lead to poor performance.
This article provides some pointers to minimize data access and improve performance for ETL processing in Vertica.
Traditional Storage versus S3
Following are some technical differences between traditional storage (such as RAID storage) and S3 storage:
- Access to S3 consumes network bandwidth and has considerably more latency when compared to direct attached storage.
- The consistency model can pose some interesting challenges for distributed databases that must provide ACID characteristics when using an eventually consistent and immutable storage system like S3.
- Traditional storage does not have a per access cost. There is a cost involved each time you read data from S3.
Key Considerations for Deploying Storage System in Eon Mode
In an Eon Mode database additional care is needed when loading, modifying, and accessing data compared to an Enterprise mode database.
- Certain database operations that were traditionally synchronous are now asynchronous in Eon Mode such as drop, truncate, and container delete (for TM MergeOut). It’s usually adequate to defer these operations to a certain degree in order to allow for the notion of real-time performance. However, this essentially entails an interesting trade-off between how far the shared communal storage lags the current cluster state with respect to removal of deleted data.
- Operations such as insert or copy are immediate writes to the shared storage and are not deferred till a client Commits. This means that an insert results in an immediate upload to S3. When a client finally "Commits" the transactions, it only causes the transaction Log to be updated to include the files that were previously uploaded. This provides good performance on the Commit operation over a slow storage system.
- Finally, since shared storage is immutable, the transaction log updates are batched and not streamed. Traditionally, databases were shutdown cleanly so that data in memory could be written to disk. This same requirement applies to a Vertica Eon Mode database to allow the transaction logs to persist (synced) on shared storage.
Symbols Used
The following symbols are for your reference. These symbols are used in images throughout this best practice.

Eon Mode Transaction Example
To understand an Eon Mode transaction, let us consider an example to see what happens when a user creates a table and commits some data. This example is explained step by step in the following sections.
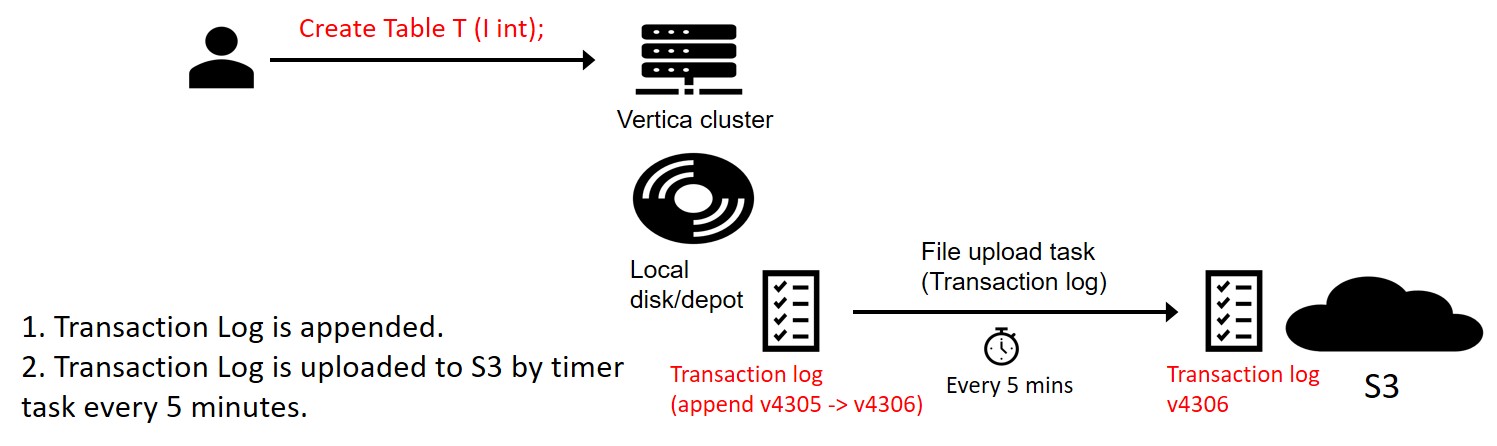
Step 1: DDL Statement
Create Table T (I int);
A transaction log file is a file that tracks all transactions attempted on a database system. This file is typically only appended to as transactions occur, and there is a monotonically increasing sequence value with every committed transaction.
A DDL statement is considered to be a transaction and causes this sequence number to increment. This creates the table locally but is not synced right away from the local file system to S3. These syncs are batched periodically (every 5 minutes) for efficiency reasons.
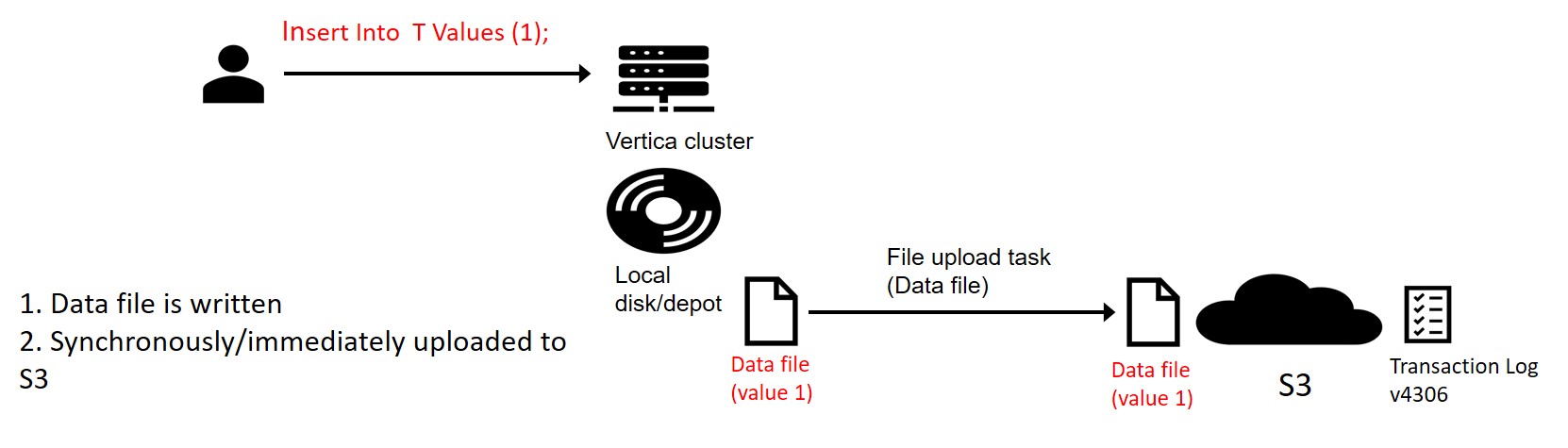
Step 2: DML (Insert/Update/Delete/Merge) Statement
Insert Into T Values (1);
Typically an insert or copy statement creates a new data file. This file is created on the local storage and uploaded to S3 immediately (synchronously). Also, this statement increments the sequence number of the session transaction should the user commit in the future.
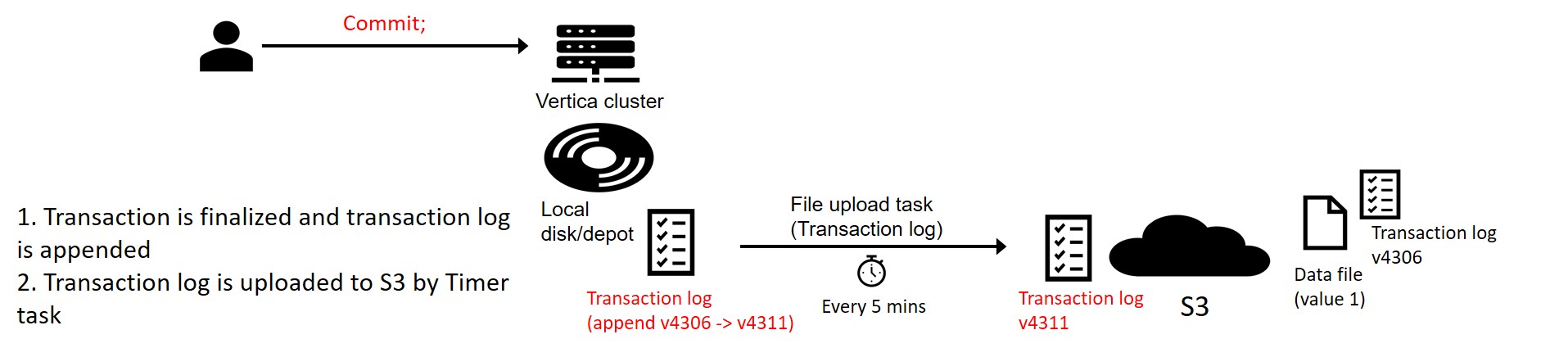
Step 3: Commit Statement
Commit;
The commit statement persists the sequence number on the transaction log files thereby making the reference to the new data file (added in the previous step) permanent.
Step 4: Drop/Truncate Object
Drop Table T;
A drop table statement appends to the transaction log file and increments the sequence number of the transaction log. The transaction log now references the files that were removed. Ultimately, the references to these files will be removed from the database catalog and the files will be deleted.
However, the data files are not deleted or removed from S3 synchronously. The files are queued for delete at a later time. This queue is called the "Reaper Queue".
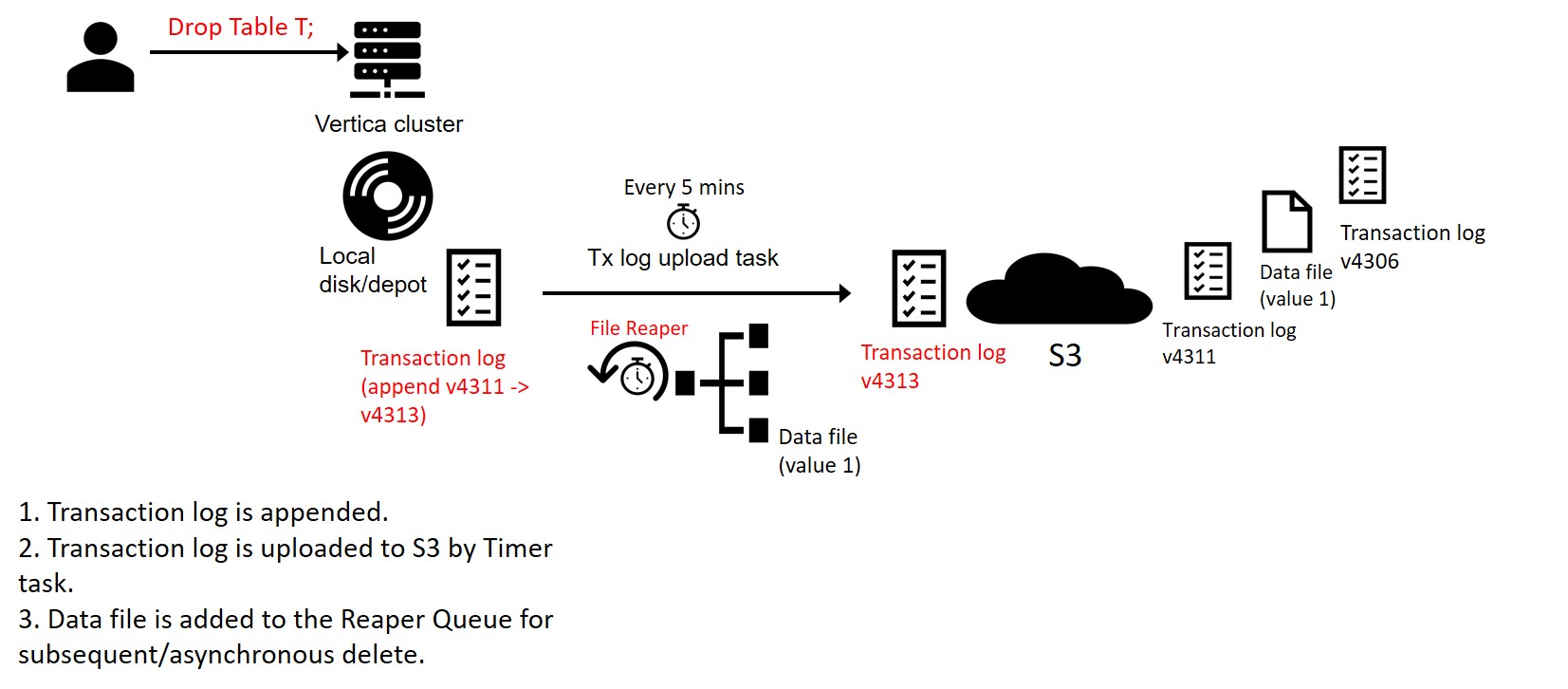
A Reaper Process checks every 5 minutes and deletes files that have become eligible for removal (both locally and from S3) . Again, this is done for performance reasons to provide the notion of real-time performance on DROP/TRUNCATE/DELETE (via TM MergeOut) statements.
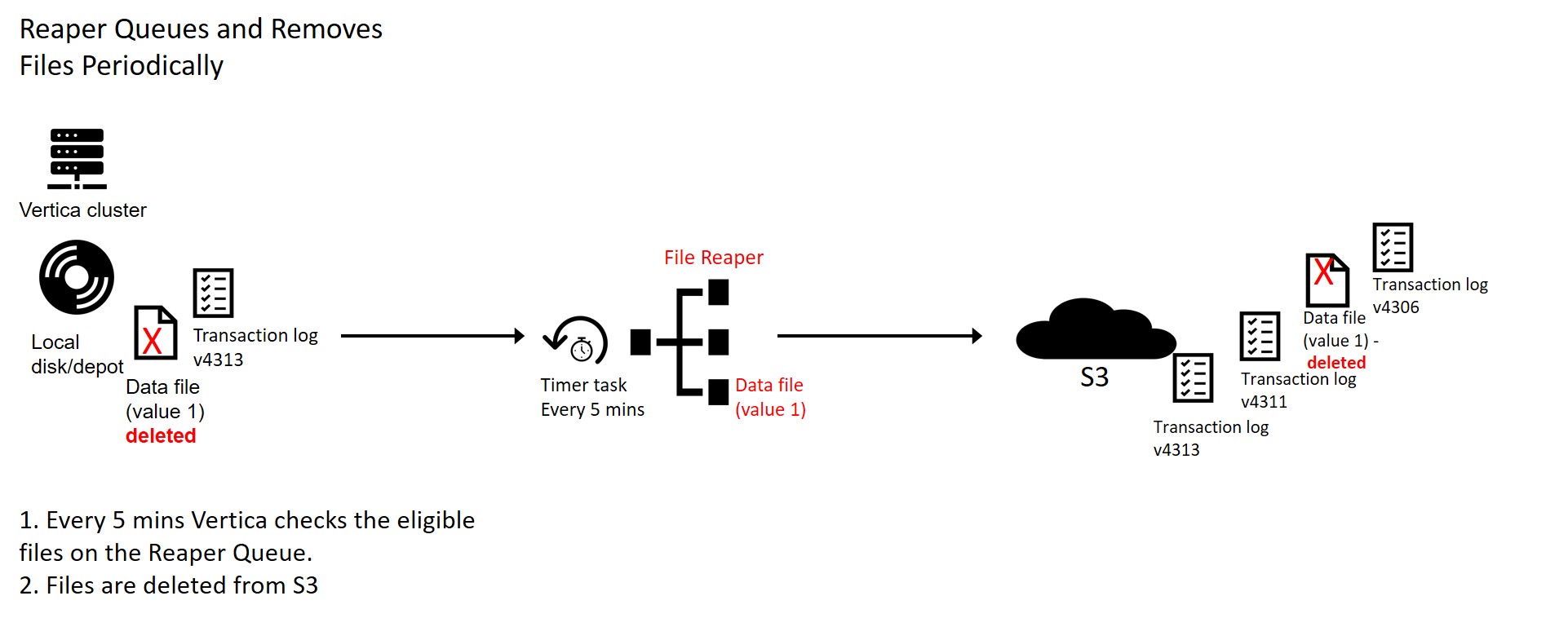
When Vertica is stopped, a parameter is provided to ensure that the reaper process has enough time to delete files in the reaper queue.
However, there may be cases where the instance is terminated, rebooted, or the Vertica process is force killed and the reaper process may not have had the chance to delete the files in S3. Hence, it is very important to cleanly stop a database.
Recommendations for ETL in Eon Mode
We highly recommend the following practices for an ETL transaction in Eon Mode:
Using Temporary Tables
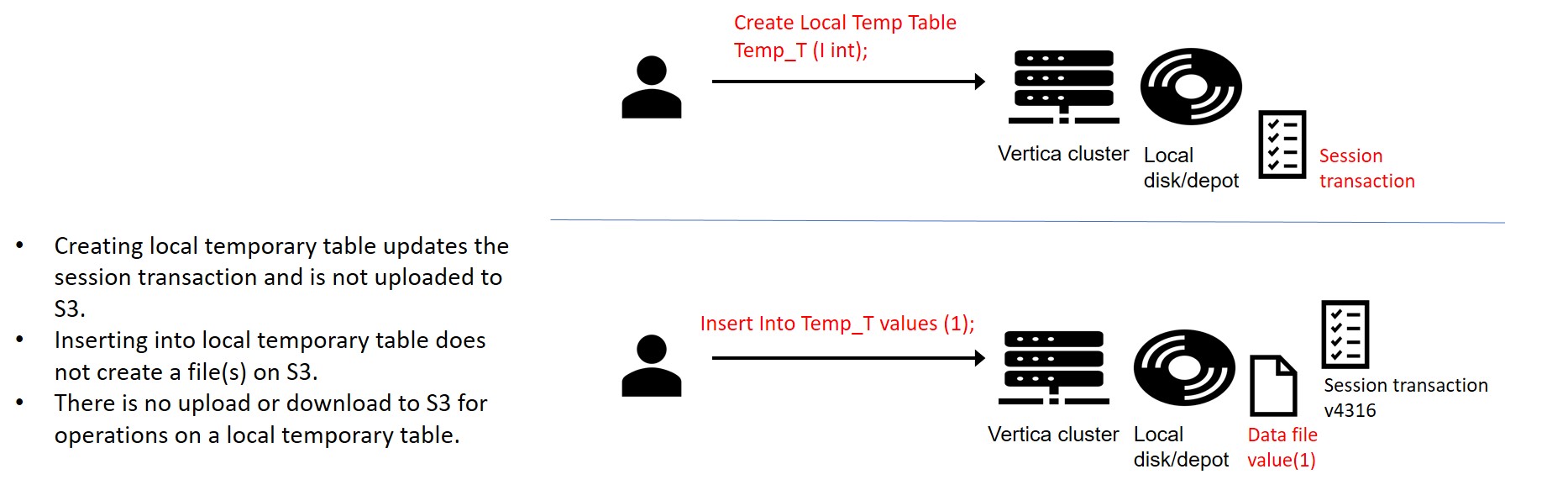
In Eon Mode, we highly recommend using temporary tables for staging, merging, and transforming data that may eventually be deleted or truncated. Temporary tables are session scoped and do not create objects on S3. Consequently, they perform better and save S3 access costs. The TEMPSPACE can be a fast ephemeral volume for best results and is included with the instance at no additional cost.
For more information about creating temporary tables, see Creating Temporary Tables.
Benefits:
Following are the benefits of using temporary tables for ETL and staging data:
• Faster INSERTS/UPDATES/DELETES as no data is written to S3
• Saving network bandwidth
• Saving S3 Read/Write and access cost
• Saving S3 API calls cost
• Saving S3 storage cost
• Temporary tables do not create files in communal storage and hence, eliminate some cleanup overhead during instance termination and does not use the reaper queue.
Example:
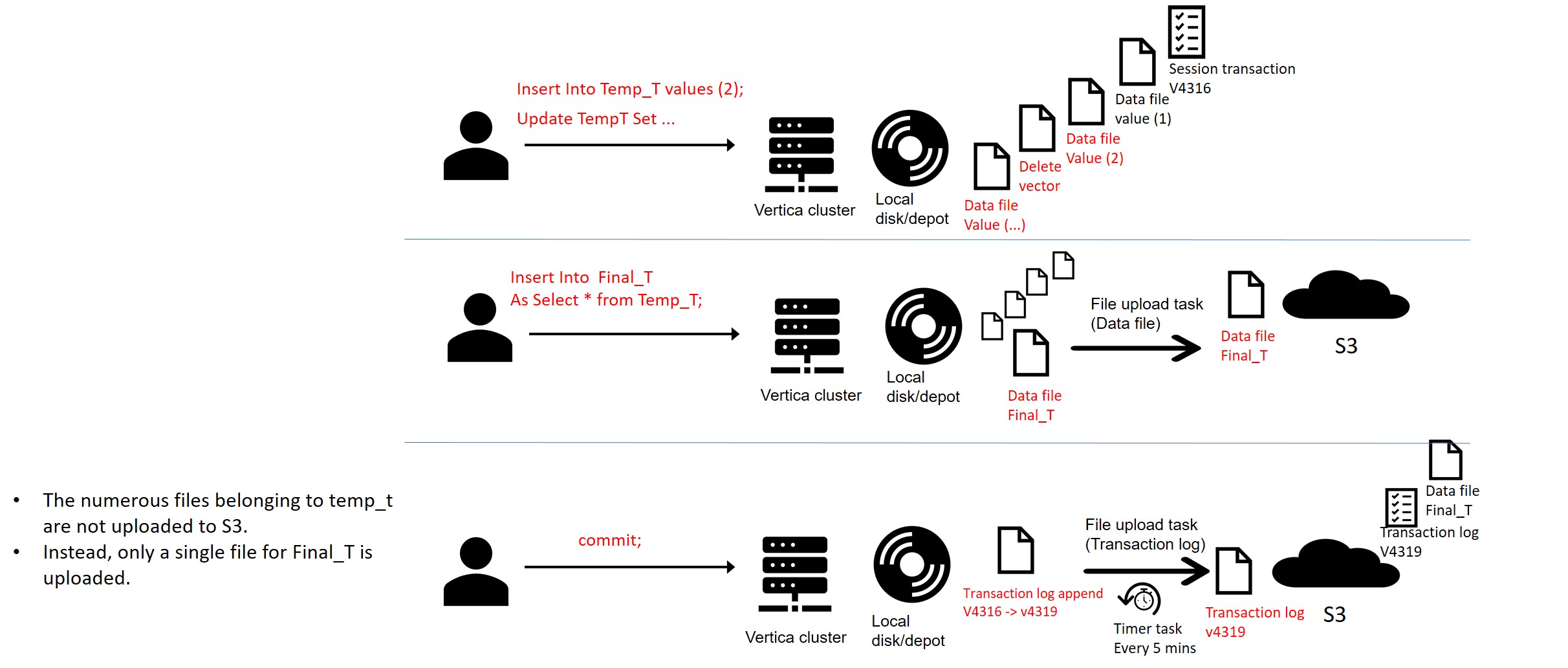
The following example illustrates the use of local temporary tables to accomplish a trivial workload.
Here, there is no download or upload (access) to S3 for commands running on Temporary Tables. After the data is transformed, updated, merged, and processed, a final insert+select will update the files in S3.
Shutdowns and Abrupt Process Terminations
Eon Mode database must always be terminated cleanly. Abrupt termination of an Eon Mode database may result in lost commits, since the transaction logs only sync every 5 minutes. Commits made in the last 5 minutes can potentially be lost in the event of an abnormal termination.
Furthermore, if the reaper process has not been allowed to delete the files in the reaper queue, those files will be left behind in S3 and have to be manually deleted (contact Support for a script or instructions on how to delete these files).
Conversely, it helps not to create files in S3 that were not meant to persist, that is, by the use of temporary tables as mentioned above.
Tuple Mover Activity
The Tuple Mover consolidates ROS data storage and performs an important function Mergeout. For more information about Tuple Mover, see Tuple Mover Operations in the Vertica documentation.
In Eon Mode, it is recommended not to load into inactive partitions of a partitioned table.
Partitioning and MergeOuts
The Tuple Mover assumes that all loads and updates to a partitioned table are targeted to one or more partitions that are identified as active.
In general, the partitions with the latest partition keys—typically, the most recently created partitions—are regarded as active. As the partition ages, it commonly transitions to a mostly read-only workload and requires much less activity. That is, the partition becomes inactive.
Recommended reads:
The Tuple Mover merges ROS containers for inactive partitions into a single ROS container. This can cause a lot of read/write from S3 and may incur S3 access costs.
Example:
Here is an example that starts with Active Partition Key=4 and Active Partition Count=1.
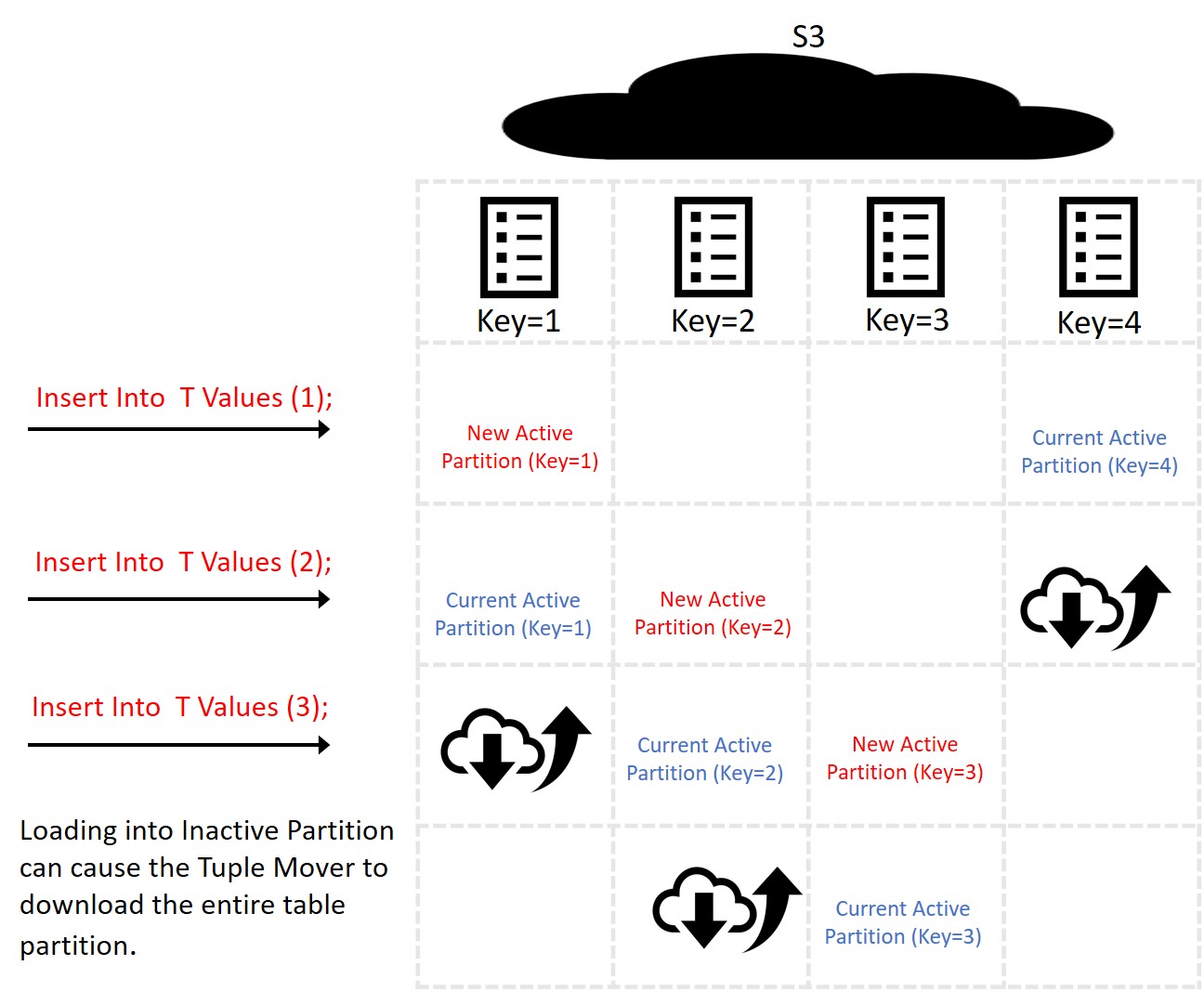
In this example, we have loaded into the partition with key=1. This creates a container each time we load. Also, this changes the active partition key to 1.
As soon as you load into the next partition (key=2), this partition becomes active. Now, the active partition key=2, which means the TM will merge all containers for partition key=1. This merge happens asynchronously. Hence, the final state is that all files for partition key 1 are merged into one file.
In Eon Mode this requires
- Downloading the entire inactive partition (key=1) from S3.
- Merging it locally.
- Uploading a single file.
- Deleting the old partition files via the reaper process
Consider a case where you have 4 partitions and the active partition count is set to 1. For example, Partition Key=(1,2,3) are considered inactive, and Partition Key=4 is active. Vertica expects you to load only into the one active partition Key=4.
Let’s assume, you decide to load into all partitions, here is what happens:
-
Current Active Partition Key =4 , Inactive Partition Key = 1,2,3. Load into Inactive Partition with Key =1, Vertica uploads new container with partition key=1
-
Now Active Partition Key =1 , Inactive Partition Key = 2,3,4. TM will download all containers for Inactive Partition with Key=4 and merge it into a single file and delete all old files.
-
Current Active Partition Key =1 , Inactive Partition Key = 2,3,4. Load into Inactive with Partition Key =2, Vertica uploads new container with partition key=2
-
Now Active Partition Key =2 , Inactive Partition Key = 1,3,4. TM will download all containers for Inactive Partition with Key=1 and merge it into a single file and delete all old files.
-
Current Active Partition Key =2 , Inactive Partition Key = 1,3,4. Load into Inactive Partition with Key =3, Vertica uploads new container with partition key=3
-
Now Active Partition Key =3 , Inactive Partition Key = 1,2,4. TM will download all containers for Inactive Partition with Key=2 and merge it into a single file and delete all old files.
The problem here is that each load into an inactive partition, downloads the old partition file(s), merges it with the new data creating a new file(s), uploads new file(s), and then deletes the old file(s).
It’s even more important in Eon Mode not to load into inactive partitions. Partitions need to be used to as per best practices and primarily to manage data retention. Incorrect use of partitions can incur a lot of AWS access costs.
For example, if you are going to be loading data generated in the past three days concurrently at any given time, partitioning by day and having active partition count=1 (default) is probably not the right thing.
You must do either one of the following so that the last three days always load into an active partition:
- Partition by Day (but set Active Partition Count = 3) or
- Partition by week (and set Active Partition Count = 2)
Note It’s very beneficial to use move, copy, and swap partition functions in Eon Mode, since they do not cause any movement of data files. It’s purely a catalog (DDL) operation.
More Information
For more details about other tunable parameters, see Eon Mode Parameters.

