




Enhancing Your Data Discovery Journey: Using DataHub Vertica Plugin
DataHub is a metadata platform for end-to-end lineage and data discovery. This video demonstrates how to effectively incorporate Vertica data in DataHub using the DataHub Vertica Plugin, enabling you to leverage the platform's advanced capabilities for gaining deeper insights.
DataHub is an open-source metadata platform for the modern data stack. It is a data catalog built to enable end-to-end data discovery, data observability, and data governance. This extensible metadata platform is built for developers to tame the complexity of their rapidly evolving data ecosystems and for data practitioners to leverage the total value of data within their organization.
DataHub Vertica Plugin
As of December 2022, DataHub supported ingesting metadata from various data sources, including databases such as PostgreSQL, Snowflake, Vertica, and so on. The beta Vertica DataHub Plugin was originally a community contribution by the DataHub community. The beta plugin only supports ingestion of metadata for tables, views, and data platforms.
Currently the Vertica plugin uses sqlalchemy dialect to connect to Vertica.
However, the plugin was missing important metadata information such as Projections, MLModels, EON mode information, OAuth metadata, and Table-View-Projection lineage. We undertook a project to write a plugin for Vertica that can pull this information. This also required a re-write of the SQLAlchemy Vertica Dialect as DataHub uses SQLAlchemy dialects to connect to Databases.
DataHub plugin for Vertica now has a certified ingestion plugin for DataHub that can be used to ingest metadata into DataHub. This now allows data practitioners to have Vertica metadata within their Datahub instance alongside other metadata, so that they can take advantage of DataHub's end-to-end data discovery and observability. They can derive meaningful insights about the usage of Vertica Objects such as Tables, Views, and Projections and visualize the lineage relationship.
This document provides an example of a metadata ingestion using Vertica and includes the steps to configure the environment and connect to Vertica using the DataHub Vertica plugin.
Test Environment
-
DataHub 0.10.5.4
-
RHEL 8.3
-
Vertica Python driver 1.3.4
-
Vertica Server 23.3
Configuring the Environment to Use DataHub with Vertica
This section explains how to install the DataHub Vertica plugin and initialize a project. The configuration is based on a Linux (RHEL) environment.
Prerequisites
To ingest metadata from Vertica, you will need
-
Vertica Server Version 10.1.1-0 and above. It may also work for older versions.
-
Vertica Credentials (Username/Password)
-
Docker for Linux
-
Docker Compose
-
Python 3.7 or later
Installing the DataHub Vertica Plugin
-
Install Docker and Docker Compose v2 for your platform.
-
On Linux, install Docker for Linux and Docker Compose.
-
Launch the Docker Engine from the command line or the desktop app.
-
Install DataHub CLI.
-
Ensure you have Python 3.7+ installed and configured. (Check using the command python3 --version).
-
Run the following commands in your terminal.
python3 -m pip install --upgrade pip wheel setuptools python3 -m pip install --upgrade acryl-datahub datahub version
-
-
To deploy a DataHub instance locally, run the following CLI command from your terminal.
datahub docker quickstart
-
To install the Vertica plugin, run the following command from the command line:
pip install 'acryl-datahub[vertica]'
Note This command will automatically install Vertica-python client driver and Vertica- SQLAlchemy dialect. You do not need to install them manually.
See the DataHub Quickstart Guide for more details.
GUI Based Ingestion
To run the ingestion from GUI:
-
Go to localhost:9002.
-
Enter your credentials to login.
-
On the top right, click Ingestion. In Sources, click Create new source , and select Vertica
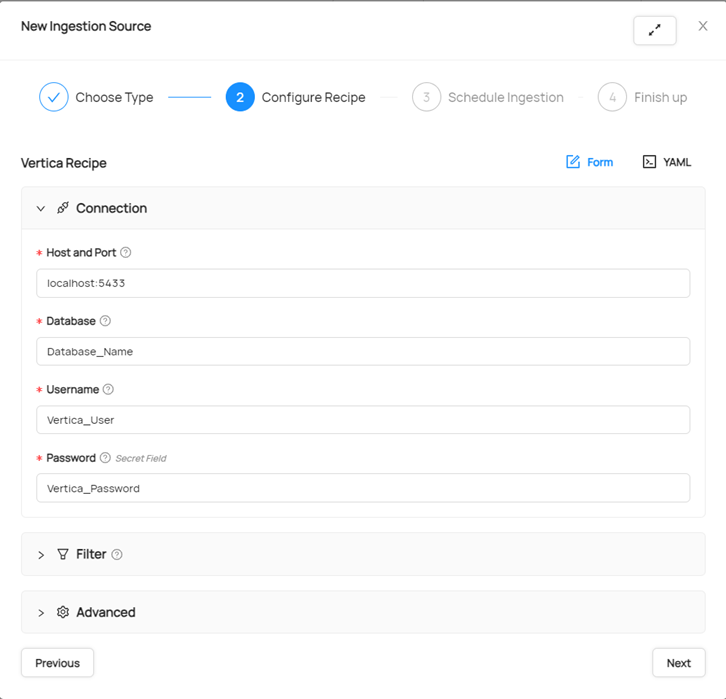
-
Fill the form with your Vertica DB credentials.
-
Click Advance to configure your metadata objects. Click the objects that you want to ingest to Datahub GUI.
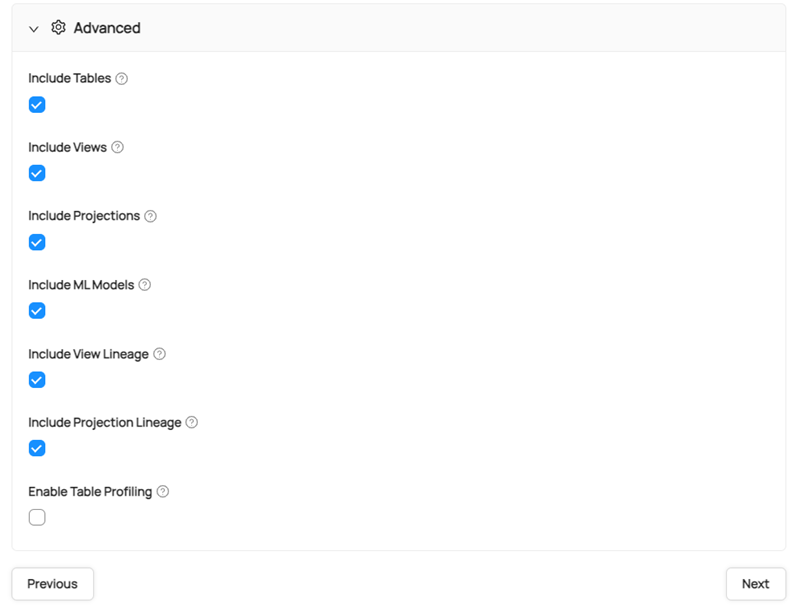
-
Click Next, configure an Ingestion schedule, and then click Next.
-
Enter the name of the ingestion and then click Advance.
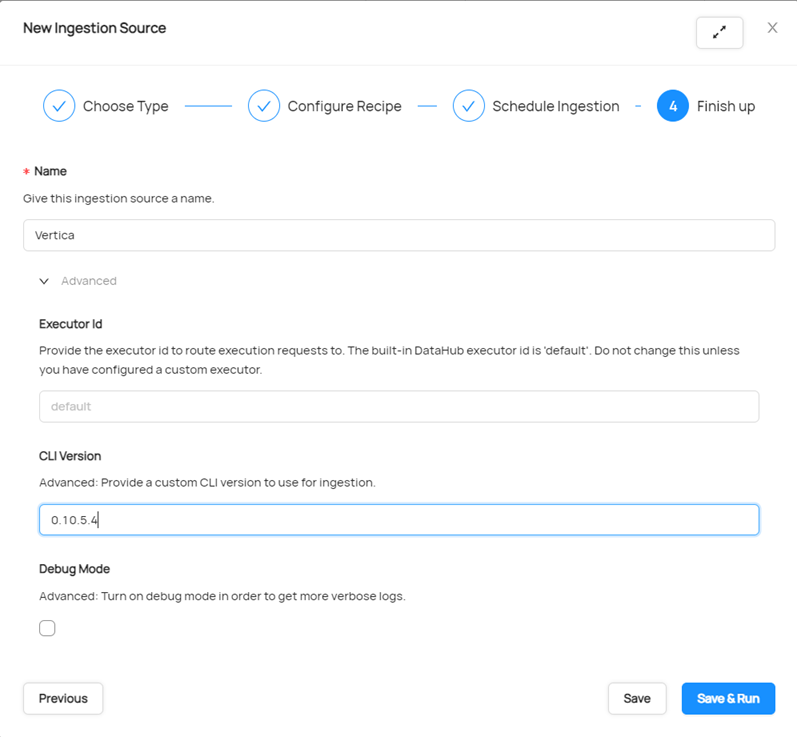
-
Check the CLI version it is on while running the ingestion. Make sure you enter the CLI Version as 0.10.5.4V or later to see Performance improvement while ingesting the Vertica metadata.
-
Click Save & Run to start the ingestion.
-
You will see the following if the ingestion is successful:

CLI Based Ingestion
For CLI based ingestion, go to the DataHub directory in your machine. Create the recipe.yml file and add the Vertica source details in it.
Check out the following recipe to get started with ingestion! See Integration Details for all configuration options.
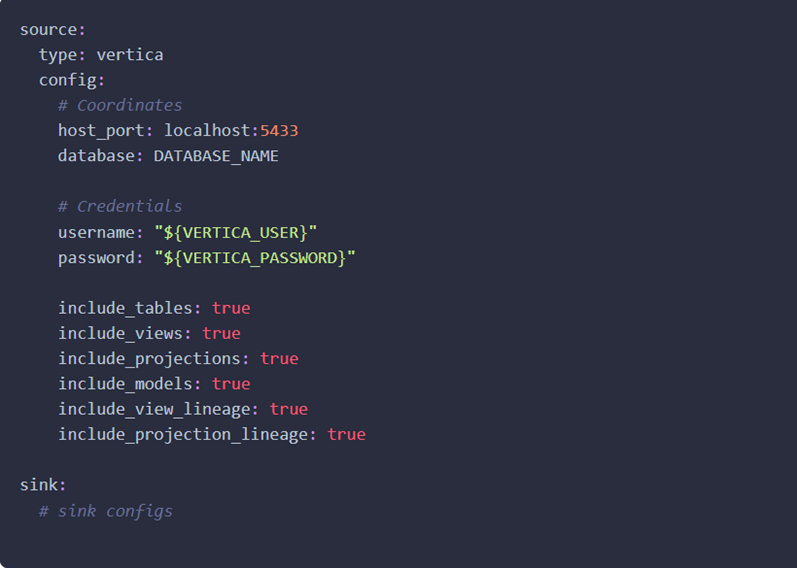
Note By default, you can change all configuration properties that are set to true as per your preference. You can add profiling and other config options based on your needs.
After adding the recipe.yml file in the DataHub directory, run the following command to start the ingestion:
datahub ingest -c recipe.yml
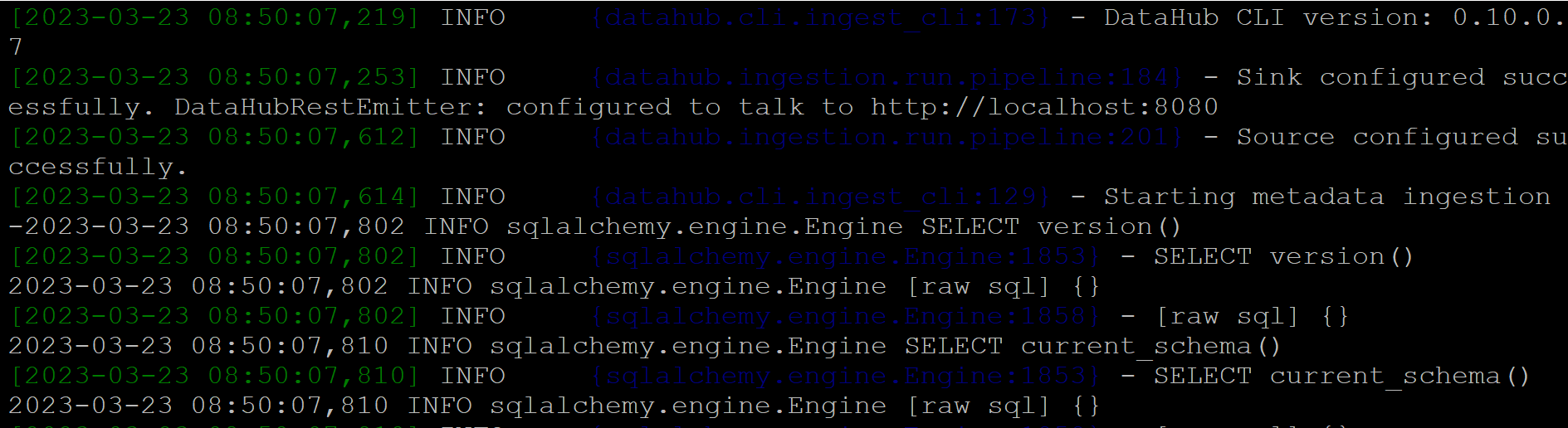
When the ingestion starts running, the log looks like this:
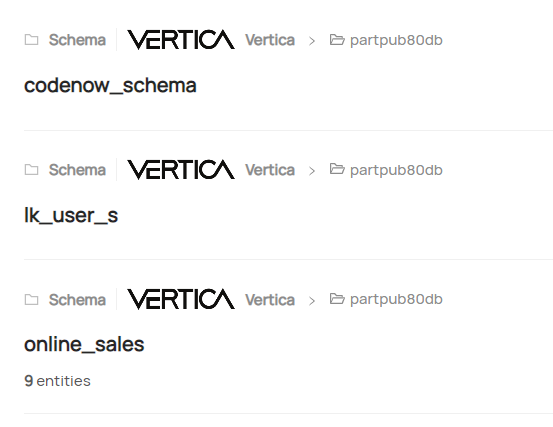
Now you can go to the DataHub UI and check metadata. You will see Vertica in the platforms sections with number of objects ingested:

Click the Vertica logo and it will take you to the list of schemas. You can select any schema and then table, view, projection to view the metadata.
New Vertica DataHub Plugin Features that Support Vertica Metadata
-
UI-based data ingestion.
-
You can now easily ingest data using the UI recipe form. That means no CLI and getting data into DataHub is now as easy for both, an experienced or novice user.
-
-
Supports viewing metadata for Tables, Projections, and Views.
-
You can visualize Vertica tables and associated projections.
-
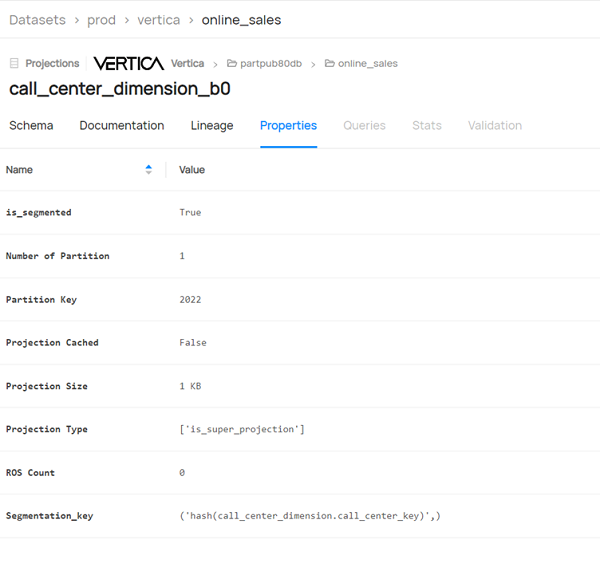
One stop location to get metadata information such as row count, number of projections, partitions, and columns, table size, column size, data type, min/max stats per column.
-
For projections, you can also detect the columns list, type of projection, pinned projections, ROS count and so on.
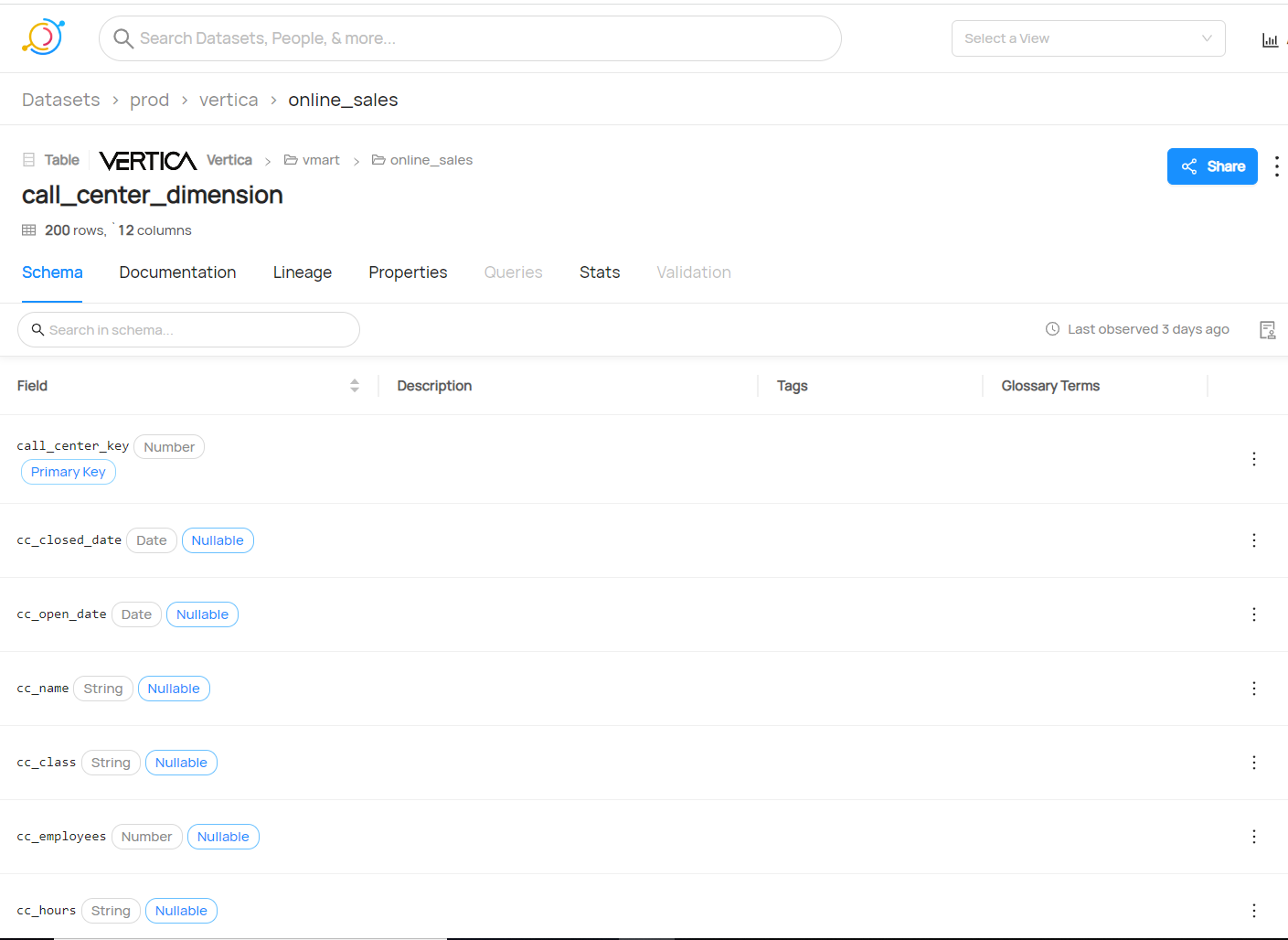
Note Default values for the columns will show up in Description if there are any.
-
-
Supports viewing lineage for Tables, Projections, and Views.
-
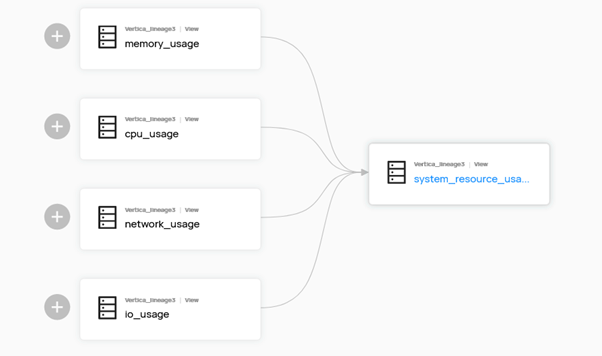
You can visualize “downstream” and “upstream” lineage for a Vertica object. For example, a table can have 2 projections created using the table. These can be viewed as a downstream lineage in DataHub.
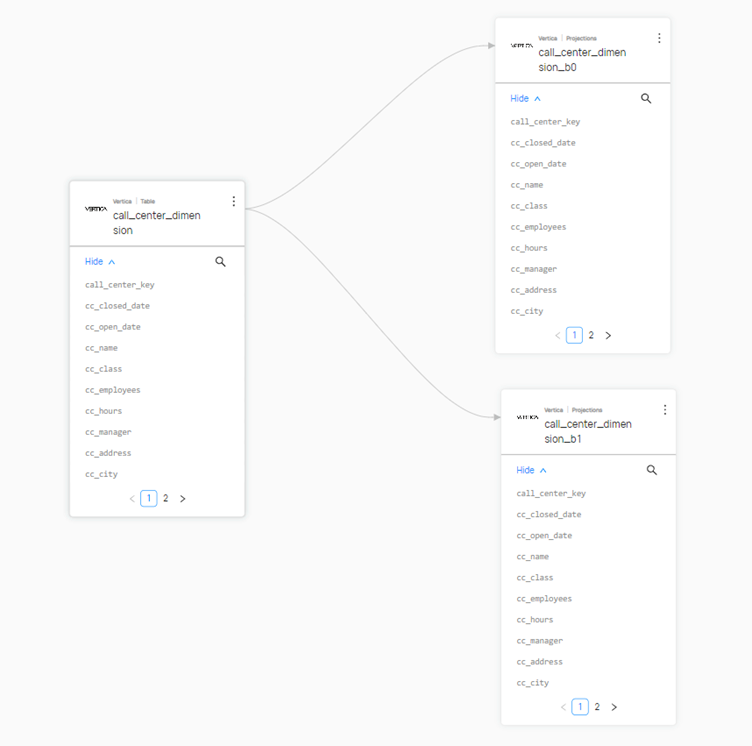
Note Lineage is not displayed if the table, projection, or view is empty.
-
A view can have multiple upstream tables which can be visualized as well.
-
This is particularly useful to determine the consequences of deleting or altering a Vertica table/view/projection on its dependencies.
-
-
Support UDX metadata.
-
You can view all schema level UDXs (permitted) and corresponding language.

-
-
Support for EON mode metadata.
-
You can determine DB mode (Enterprise/EON) the data was ingested from, the communal storage path, and subcluster size.
-
-
Support for ML Models.
-
You can view a summary of any ML model created in the Vertica DB at the schema level.
-
Corresponding results of the Model runs are also shown along with the user who used it.
-
-
Support for deleted entities.
-
During ingestion, enabling stateful_ingestion will allow you to determine any objects that were deleted with respect to previous ingestion.
-
-
Owner for ingested data.
-
Vertica plugin extends DataHub’s support for data federation using “owners”. Every ingested data can only be viewed by the person authorized to in DataHub.
-
-
Improved SQLAlchemy Dialect.
-
The relevant logic to fetch the metadata into Datahub needed to be materialized into the SQLalchemy-vertica dialect. Previously this was developed by an unknown third party. So, as a by-product of this development, we have now a new and improved Vertica-dialect for sqlalchemy that supports many more features than previous open-source versions did.
-
An additional advantage of adding logic into our dialect instead of DataHub was that any other product can now use the new dialect to access Vertica.
-
Known Limitations
-
In Stats, max and min values are not displayed for primary keys.
-
For integer, boolean, and date columns, length of the column is not displayed as the length is fixed in the Vertica database.
For More Information
-
DataHub Vertica plugin GitHub page
- Vertica Community Edition
- Vertica Documentation
- Vertica User Community

