




Vertica and Coiled: Technical Exploration
About this Document
This goal of this document is to use the Dask supported cloud environment Coiled with Vertica to read, write, and perform analytics on huge data sets. Coiled manages Dask computational clusters.
Coiled and Dask Overview
Coiled helps build distributed and scalable application using python. It helps data scientists to use python to solve problems involving huge data sets by providing computing power in the cloud.
Dask is an open source framework that provides parallelism to the existing Python stack. Dask provides integrations with Python libraries like NumPy Arrays, Pandas DataFrames and scikit-learn.
Test Environment
- Coiled 0.0.67
- RHEL 8.3
- Vertica 11.0.0
- Vertica driver: Vertica_python 1.0.5
Connecting Coiled to Vertica
- To install pip, run the following command:
sudo yum install python-pip
-
Execute the following code to install Coiled:
pip install coiled dask distributed --upgrade
-
Go to https://coiled.io/ and click Start My Free Trial.
-
Sign in with your Google or Github account.
-
Open the link from your email. In your coiled account, go to the account profile page and generate a new API token. Save the token locally for further use.
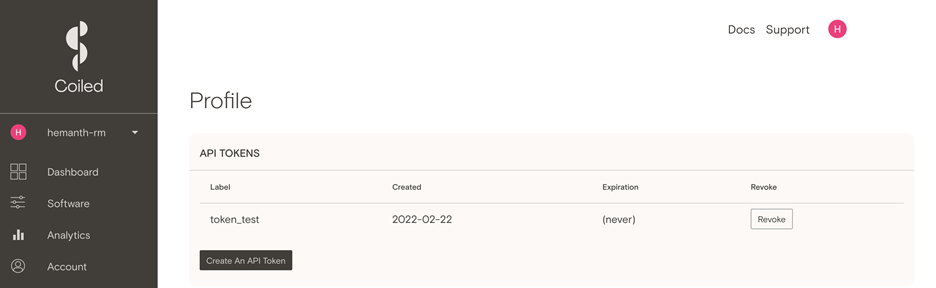
-
Execute
coiled –versionto check the version of Coiled that is installed.
-
Execute
coiled loginto log into the Coiled environment. -
Provide the token generated in your profile to log into your Coiled cloud environment.

-
Execute
ipythonto lauch the ipython session in the Coiled cluster. -
Execute the following python code in the ipython session. Provide the required number of workers. In this example, we set it to 10 workers.
import coiled cluster = coiled.Cluster(n_workers=10) from dask.distributed import Client client = Client(cluster) print('Dashboard:', client.dashboard_link)
-
-
After a successful creation of the cluster, you will see the following message:
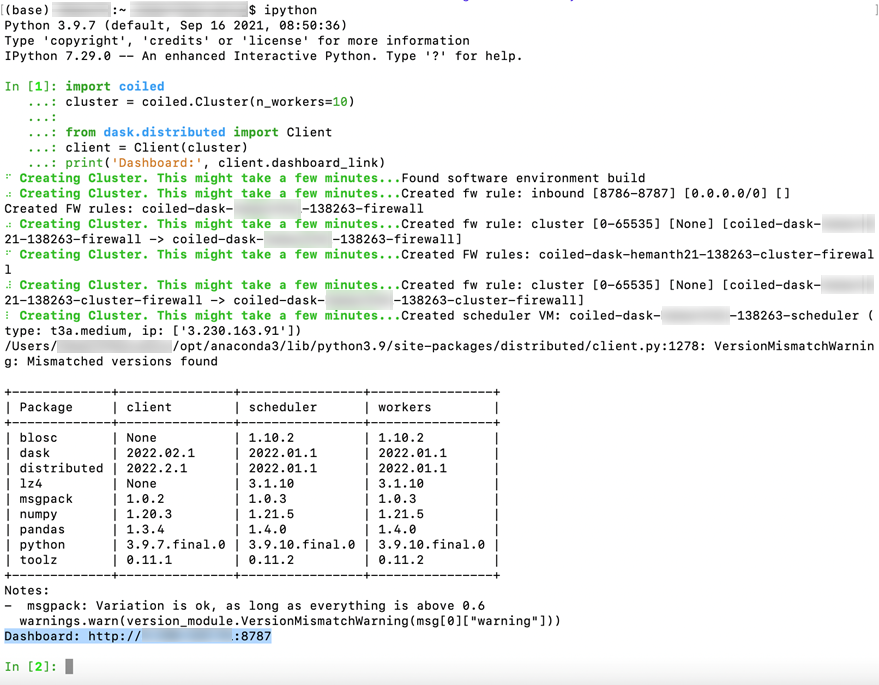
-
You can access the dashboard using the URL to see the statistics when running different operations on the Coiled cluster.
Reading Data from Vertica and Loading it into a Dask Dataframe
Execute the following code in the ipython session to read data from iris table in coiled_schema from the Vertica database and load it into a dask dataframe.
import coiled
from dask.distributed import Client
from dask_vertica import read_vertica
#The below snipped of code installs the dependencies required in the coiled env.
coiled.create_software_environment(
name="vertica",
pip=["bokeh>=2.1.1", "pandas", "git+https://github.com/coiled/dask-vertica.git"],
force_rebuild=True
)
cluster = coiled.Cluster(
name="vertica-test",
n_workers=4,
software="vertica",
)
client = Client(cluster)
connection_kwargs={
"user": "coiled_user",
"password": "<Pwd>",
"host": '<IP-Address>',
"port": 5433,
"database": 'PartPub80DB'
}
ddf = read_vertica(connection_kwargs, 'iris', 5 , 'coiled_schema')
ddf.groupby("Species").PetalLengthCm.mean().compute()
Writing Data to Vertica from a Dask Dataframe
To write data to Vertica, execute the following code in an ipython session. The following code generates a dummy time series data set and is written to a table in Vertica. The following code has two scenarios, to write data sets with few number of partitions and large number of partitions.
Replace the following code snippet with the schema name and table name you want to write it into:
schema = "Machine_Learning_Test"
name = "test_02"
from datetime import datetime
import coiled
from dask.distributed import Client
from dask_vertica import to_vertica
import vertica_python
from verticapy.connect import *
from verticapy.utilities import *
from verticapy.learn.metrics import *
from verticapy.learn.mlplot import *
from verticapy.toolbox import *
from verticapy.errors import *
from verticapy.learn.vmodel import *
import logging
from distributed.client import Client
import dask.dataframe as dd
from dask_vertica.core import (
daskdf_to_vertica,
to_vertica,
_drop_table,
_check_if_exists
)
from dask import compute
from verticapy import readSQL
from verticapy.datasets import load_titanic, load_iris
coiled.create_software_environment(
name="vertica",
pip=["bokeh>=2.1.1", "pandas", "git+https://github.com/coiled/dask-vertica.git", "verticapy", "vertica-python"],
force_rebuild=True
)
cluster = coiled.Cluster(
name="vertica-test",
n_workers=4,
software="vertica",
)
client = Client(cluster)
logging.basicConfig(filename='myapp.log', level=logging.DEBUG, filemode='a')
logging.info(f'\n---------- Starting {datetime.datetime.now()}')
vdb = {
'host': '<IP-Address>',
'port': 5433,
'user': 'dbadmin',
'password': '<Pwd>',
'database': 'VMart',
'connection_load_balance': True,
'session_label': 'py',
'unicode_error': 'strict'
}
def show_tables(vdb):
with vertica_python.connect(**vdb) as conn:
with conn.cursor() as cur:
table_query = f"""
SELECT TABLE_SCHEMA, TABLE_NAME FROM V_CATALOG.TABLES
WHERE TABLE_SCHEMA = '{schema}'
"""
cur.execute(table_query)
tables = [t[1] for t in cur.fetchall()]
return tables
# Set Verticapy Auto Connection
new_auto_connection(vdb, name="vdb_auto_connection")
# Set the main auto connection
change_auto_connection("vdb_auto_connection")
schema = "Machine_Learning_Test"
name = "test_02"
tables = show_tables(vdb)
print(tables)
with vertica_python.connect(**vdb) as conn:
for t in tables:
if t.startswith("iris") or t.startswith("demo_ts"):
_drop_table(conn, t, schema=schema)
with conn.cursor() as cur:
iris = load_iris(cur, schema=schema)
ddf = dd.from_pandas(iris.to_pandas(), npartitions=3)
tables = show_tables(vdb)
print(tables)
assert not "iris_async" in tables
assert not "demo_ts" in tables
# small dataframe, 3 partitions
to_vertica(ddf, vdb, "iris_async", schema=schema, if_exists="overwrite")
# larger DF with more partitions
demo_ts = dd.demo.make_timeseries(
start="2000-01-01",
end="2000-12-31",
freq="30s",
partition_freq="1W"
)
print("demo_ts")
print(datetime.datetime.now())
to_vertica(demo_ts, vdb, "demo_ts", schema=schema, if_exists="overwrite")
print(datetime.datetime.now())
tables = show_tables(vdb)
print(tables)
assert "iris_async" in tables
assert "demo_ts" in tables
The data is now loaded into the Vertica database.

