




Vertica and Apache Storm: Technical Exploration
About this Document
The goal of this exploration is to integrate Vertica with Apache Storm and how you can ingest Kafka Stream into Vertica Database.
Apache Storm Overview
Apache Storm is an open source and distributed real time computation system. It can be used for machine learning, real time analytics, ETL, and more. Apache Storm can be integrated with Databases and Queuing services. You can download Apache Storm from the the Apache Storm website.
Test Environment
-
OS Windows Server 2019
-
Java JDK 8
-
Vertica Server version 12.0.3
-
Vertica JDBC Driver version 12.0.3
-
IDE IntelliJ IDEA Community Edition
-
Apache Storm 2.4.0
-
Kafka 2.12
Apache Storm Mode
Apache Storm supports two modes:
-
Local
-
Production
Note We have used Local mode in this exploration.
Creating Apache Storm Project
-
Open IntelliJ Community Edition and create new project with Language as Java and Build System as Maven. Also select JDK 1.8.
-
Open pom.xml file and add required dependencies.
-
Import Vertica JDBC Driver.
-
Create KafkaSpoutConfig in main method.
-
Create Spout object, Bolt object, and create topology.
-
Create another class for bolt and extend BaseBasicBolt.
-
In declareOutputFields method declare schema.
-
In execute method, create Vertica JDBC connection, and also write logic for insertion of data into Vertica.
-
Initiate the Kafka producer.
-
Run the Apache Storm program. The data should be inserted into the Vertica table.
Steps for Adding Vertica JDBC JAR in IntelliJ
-
After the project is created in IntelliJ, open File > Project Structure.
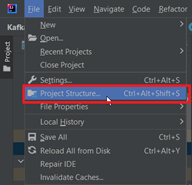
-
In Project Settings select Modules and select Dependencies.

-
Click + icon in Module SDK and select the JAR or directories. Select Vertica JDBC Jar. Vertica JAR should be visible in Imported libraries.
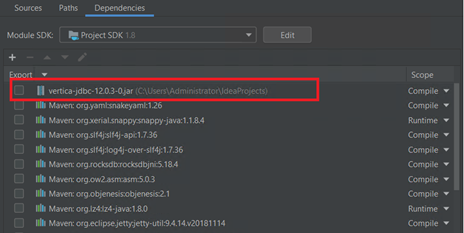
Complete Project Details
The following code contains the POM file, Bolt, and topology that enable you to move Kafka messages to Vertica.
POM File
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>KafkaJDBC</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-core -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.4.0</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-kafka-client -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.4.0</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>
</dependencies>
</project>
Storm Kafka Bolt:
package org.example;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class KBolt extends BaseBasicBolt {
private OutputCollector collector;
private BasicOutputCollector basicOutputCollector;
private Connection connection;
private PreparedStatement statement;
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
this.basicOutputCollector = basicOutputCollector;
try {
Class.forName("com.vertica.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:vertica://<VerticaServerIP>:5433/<DBName>?user=<Uname>&password=<DBPassword>");
//In below statement, id is the name of column.
statement = connection.prepareStatement("INSERT INTO <TableName> (id) VALUES (?)");
// Extract data from Kafka tuple and populate JDBC statement
String id = tuple.getValueByField("value").toString();
statement.setString(1, id);
System.out.println("Printing the message from Kafka: " + id);
// Execute the JDBC statement and acknowledge the tuple
statement.executeUpdate();
basicOutputCollector.emit(new Values(id));
} catch (Exception e) {
// Log error and fail the tuple
collector.fail(tuple);
throw new RuntimeException("Failed to execute JDBC statement", e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("id"));
}
}
Storm Kafka Spout Topology:
package org.example;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.kafka.spout.FirstPollOffsetStrategy;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.topology.TopologyBuilder;
import java.util.Properties;
public class MainKSprout1 {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
Properties prop = new Properties();
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "1");
KafkaSpoutConfig spoutConfig = KafkaSpoutConfig.
builder("PLAINTEXT://<KafkaProducerIP>:9092","<KafkaTopic>")
.setProp(prop)
.setFirstPollOffsetStrategy(FirstPollOffsetStrategy.EARLIEST)
.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_MOST_ONCE)
.setOffsetCommitPeriodMs(100)
.setProp("session.timeout.ms", 20000)
.setProp("heartbeat.interval.ms", 15000)
.build();
builder.setSpout("stations", new KafkaSpout<String, String>(spoutConfig));
builder.setBolt("MultiplierBolt", new KBolt()).shuffleGrouping("stations");
Config config = new Config();
config.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("HelloTopology", config, builder.createTopology());
try {
Thread.sleep(10000);
} catch (InterruptedException e){
e.printStackTrace();
}
}
}

