Vertica Integration with Apache Hudi: Technical Exploration
About this Document
This document explores the integration of Vertica and Apache HUDI using external tables. In this exploration, we used Apache HUDI on Spark to ingest data into S3 and accessed this data at different timelines using Vertica external tables.
Apache Hudi Overview
Apache Hudi is a Change Data Capture (CDC) tool that records transactions in a table at different timelines. Hudi stands for Hadoop Upserts Deletes Incrementals and is an open-source framework. Hudi provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
The following flow chart illustrates a high level view of the process. Data is processed to S3 using HUDI installed on Apache Spark and data changes in S3 are read from Vertica External Table.

Prerequisites
- Apache Spark environment. We tested using a 4 node cluster with one Master and three Workers. Follow the instructions in Set up Apache Spark on a Multi-Node Cluster to install a multi-node spark environment. Start Spark multi-node cluster.
- Vertica Analytical Database. We tested using Vertica Enterprise 11.0.0.
- AWS S3 or S3 compatible object store. We tested using MinIO as an S3 bucket.
-
The following jar files are required. You can copy the jars in any required location on the Spark machine. We placed these jar files at /opt/spark/jars.
Hadoop - hadoop-aws-2.7.3.jarAWS - aws-java-sdk-1.7.4.jar
-
Run the following commands in the Vertica database to set S3 parameters for accessing the bucket:
SELECT SET_CONFIG_PARAMETER('AWSAuth', 'accesskey:secretkey');SELECT SET_CONFIG_PARAMETER('AWSRegion','us-east-1');SELECT SET_CONFIG_PARAMETER('AWSEndpoint',’<S3_IP>:9000');SELECT SET_CONFIG_PARAMETER('AWSEnableHttps','0');Note Your endpoint value may differ depending on the S3 object storage you have chosen for your S3 bucket location.
Vertica and Apache Hudi Integration
To integrate Vertica with Apache HUDI, we need to first integrate Apache Spark with Apache HUDI, configure the jars, and the connection to access AWS S3. Second, connect Vertica to Apache HUDI . Then, perform operations such as Insert, Append, Update, on the S3 bucket.
Follow the steps in the following sections to write data to Vertica.
Configuring Apache HUDI and AWS S3 on Apache Spark
-
Run the following commands in the Apache Spark machine.
This downloads the Apache Hudi package, configures the jar files, and AWS S3, that is, MinIO:
/opt/spark/bin/spark-shell \ --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"\--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1
-
Import read, write, and other packages of HUDI which are required:
import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._
-
Configure the Minio access key, Secret key, Endpoint, and other S3A algorithm and path style as required using the below commands.
spark.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "*****") spark.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "*****") spark.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "http://XXXX.9000") spark.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true") sc.hadoopConfiguration.set("fs.s3a.signing-algorithm","S3SignerType") -
Create variables to store the table name and S3 path of MinIO. You will need both in the next steps.
Val Table = “Trips” Val basepath = “s3a://apachehudi/vertica/”
-
Preparing the Data
Create sample data in Apache spark using Scala
val df = Seq( ("aaa","r1","d1",10,"US","20211001"), ("bbb","r2","d2",20,"Europe","20211002"), ("ccc","r3","d3",30,"India","20211003"), ("ddd","r4","d4",40,"Europe","20211004"), ("eee","r5","d5",50,"India","20211005"), ).toDF("uuid", "rider", "driver","fare","partitionpath","ts") -
Write data into AWS S3 and verify this data:
df.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Overwrite). save(basePath) -
Run the following command using Scala to verify that data is read correctly from the S3 Bucket.
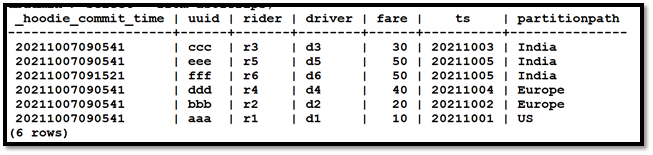
spark.read.format("hudi").load(basePath).createOrReplaceTempView("dta") spark.sql("select _hoodie_commit_time, uuid, rider, driver, fare,ts, partitionpath from dta order by uuid").show()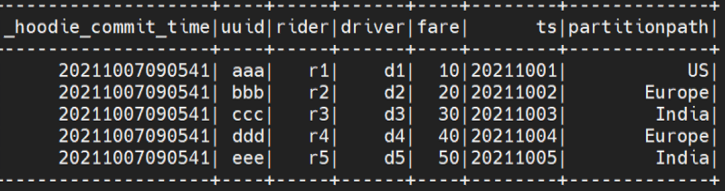
Configuring Vertica and Apache HUDI Integration
-
Create an external table in vertica that contains data from the Hudi Table on S3. We created the table “Trips”.
CREATE EXTERNAL TABLE Trips ( _hoodie_commit_time TimestampTz, uuid varchar, rider varchar, driver varchar, fare int, ts varchar, partitionpath varchar ) AS COPY FROM 's3a://apachehudi/parquet/vertica/*/*.parquet' PARQUET;
-
Run the following command to verify the external table is being read:

How to Get Vertica to See Changed Data
The following sections contain samples of some operations that we performed to view the changed data in Vertica.
Appending Data
-
In this example, we ran the following commands in Apache spark using Scala and appended some data:
val df2 = Seq( ("fff","r6","d6",50,"India","20211005") ).toDF("uuid", "rider", "driver","fare","partitionpath","ts") -
Run the following commands to append this data to the Hudi Table on S3:
df2.write.format("org.apache.hudi").options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
Updating Data
-
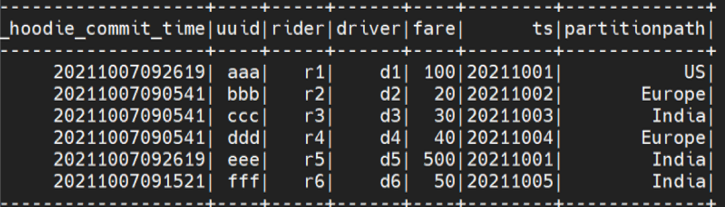
In this example, we updated a record of the Hudi Table. To update the record first you need to import the data in to spark and update the data:
val df3 = Seq( ("aaa","r1","d1",100,"US","20211001"), ("eee","r5","d5",500,"India","20211001") ).toDF("uuid", "rider", "driver","fare","partitionpath","ts") -
Run the following commands to update the data to the HUDI table on S3:
df3.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) -
Following is the output from spark.sql:
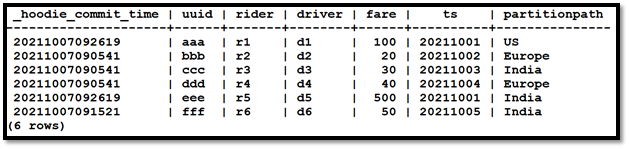
Following is the Vertica output:
Creating and Viewing the historical snapshot of data
-
Execute the following spark command that points to a specific Timestamp:
val dd = spark.read .format("hudi") .option("as.of.instant", "20211007092600") .load(basePath) -
Write the data to the parquet in S3 using the following command:
dd.write.parquet("s3a://apachehudi/parquet/p2") -
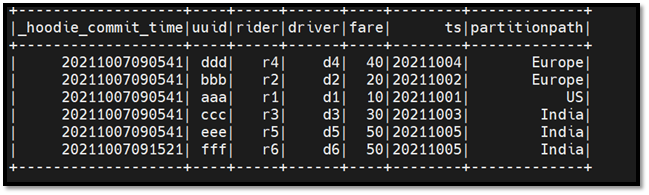
In this example, we are reading the Hudi table snapshot as of ‘20211007092600’ date.
dd.show
-
Execute the command from Vertica by creating an external table on the parquet file.