




Vertica Integration with Apache Flink: Connection Guide
About Vertica Connection Guides
Vertica connection guides provide basic instructions for connecting a third-party partner product to Vertica. Connection guides are based on our testing with specific versions of Vertica and the partner product.
Vertica and Apache Flink: Latest Versions Tested
This document is based on our testing using the following versions:
| Software | Version |
|---|---|
| Apache Flink |
1.13 |
| JDK | 1.8 |
| Scala | 2.11.0 |
| IntelliJ IDEA | IntelliJ Community Edition 2021.1.1 |
| Desktop Platform | Windows Server 2016 |
| Vertica Client |
Vertica JDBC Driver 10.1 |
| Vertica Server |
Vertica 10.1 |
Apache Flink Overview
Apache Flink is an open source framework and distributed processing engine developed by Apache Software Foundation. It is used for stream processing and batch processing. This tool is developed using Java and Scala. You can use Java, Scala, or Python to program in Apache Flink.
Downloading the Vertica Client Driver
Apache Flink uses the Vertica JDBC driver to connect to Vertica. To download the client driver
- Navigate to the Vertica Client Drivers page.
-
Download the JDBC driver package for your version of Vertica.
Note For more information about client and server compatibility, see Client Driver and Server Version Compatibility in the Vertica documentation.
Connecting Vertica to Apache Flink
To read data from Vertica as the source and write to Vertica as the target with Apache Flink,
-
Open IntelliJ IDEA and create a new Scala project with sbt as the build type.
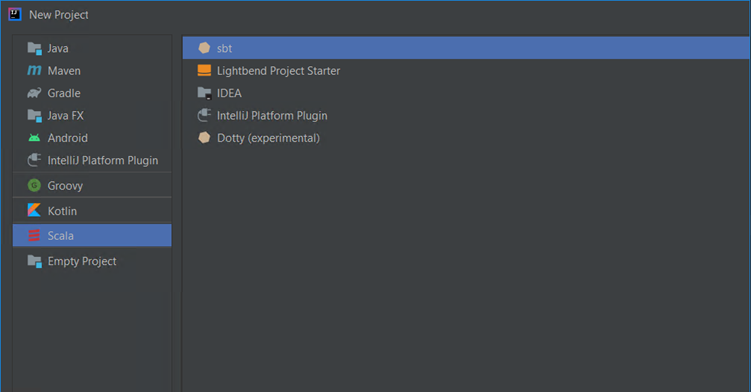
-
After the project is created, add the following SBT dependencies in the build.sbt file that is located in your project (Project > build.sbt). Wait for the dependencies to load into your environment.
libraryDependencies += "org.apache.flink" %% "flink-scala" % "1.13.0"
libraryDependencies += "org.apache.flink" % "flink-core" % "1.13.0"
libraryDependencies += "org.apache.flink" %% "flink-clients" % "1.13.0"
libraryDependencies += "org.apache.flink" %% "flink-jdbc" % "1.10.3" % "compile"
libraryDependencies += "org.apache.flink" %% "flink-table-planner" % "1.13.0" % "compile"
-
Add the Vertica JDBC Driver jar file in your project.
-
From the menu, click File, and then click Project Structure.
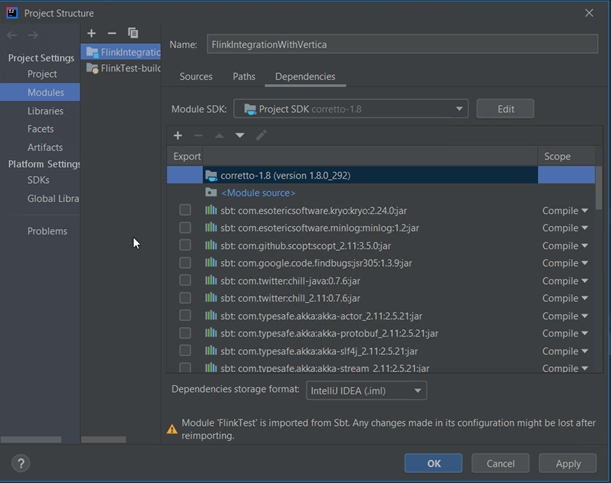
-
Click the plus sign below Module SDK, and then click JARs or Directories.

-
Select the Vertica JDBC driver jar file that you downloaded from the Vertica website and click OK.
-
In the Project Structure window, click OK.
The Vertica JDBC driver is displayed in the left pane, Project > External Libraries.
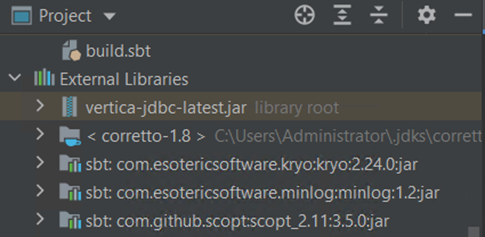
-
-
Create a Scala class file.
By default, Class is selected. Select Object and enter the class name.
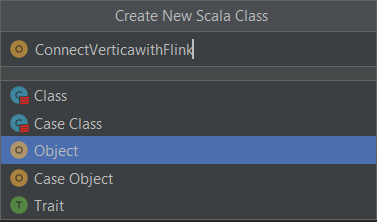
-
Import the following packages in your project:
import org.apache.flink.api.common.typeinfo.{BasicTypeInfo, PrimitiveArrayTypeInfo, SqlTimeTypeInfo, TypeInformation}import org.apache.flink.api.java.io.jdbc.JDBCOutputFormat
import org.apache.flink.table.api.bridge.scala.BatchTableEnvironment
import org.apache.flink.api.java.io.jdbc.JDBCInputFormat
import org.apache.flink.api.java.typeutils.{RowTypeInfo}import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.types.Row
import org.apache.flink.api.scala._
-
Create a connection with Vertica as the source database and map the data types:
val dataSource = env.createInput(JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("com.vertica.jdbc.Driver").setDBUrl("jdbc:vertica://<IP_Address>:5433/<DB Name>?user=<username>&password=<password>").setQuery("Query for reading the source table").setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO))
.finish())
-
Create a temporary view and create a data set using the view:
tableEnv.createTemporaryView("<Temp View Name>", dataSource)val query = tableEnv.sqlQuery("<Query on source view>")dataSource.print()
val result = tableEnv.toDataSet[Row](query)
-
Create a connection with Vertica as the target database and map the data types:
result.output(JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("com.vertica.jdbc.Driver").setDBUrl("jdbc:vertica://<Target_DB_IP>:5433/<DB Name>?user=<username>&password=<password>").setQuery("insert into <SchemaName>.<TableName> values (?,?,?)") //Parameters passed to this query should match to the number column in source table..setSqlTypes(Array(java.sql.Types.VARCHAR, java.sql.Types.VARCHAR, java.sql.Types.VARCHAR))
.finish())
-
Execute the program.
-
Verify the data in the Vertica database.
- Source database
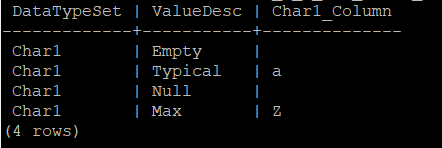
- Target database
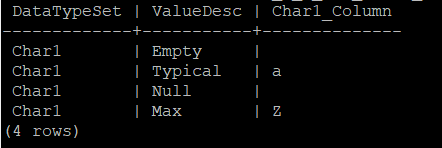
- Source database
Sample Code
Following is a sample code to connect to Vertica as a source and target with Flink. In the following example, we are reading the data from Vertica and writing to Vertica:
package org.vertica.flink
import org.apache.flink.api.common.typeinfo.{BasicTypeInfo, PrimitiveArrayTypeInfo, SqlTimeTypeInfo, TypeInformation}import org.apache.flink.api.java.io.jdbc.JDBCOutputFormat
import org.apache.flink.table.api.bridge.scala.BatchTableEnvironment
import org.apache.flink.api.java.io.jdbc.JDBCInputFormat
import org.apache.flink.api.java.typeutils.{RowTypeInfo}import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.types.Row
import org.apache.flink.api.scala._
object FlinkWithVerticaDemo {def main(args: Array[String]): Unit = {val env = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = BatchTableEnvironment.create(env)
//Create Source connection and map row datatype
val dataSource = env.createInput(JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("com.vertica.jdbc.Driver").setDBUrl("jdbc:vertica://<IP_Address>:5433/<DB Name>?user=<username>&password=<password>").setQuery("Query for reading the source table").setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO))
.finish())
tableEnv.createTemporaryView("<Temp View Name>", dataSource)val query = tableEnv.sqlQuery("<Query on source view>")dataSource.print()
val result = tableEnv.toDataSet[Row](query)
result.output(JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("com.vertica.jdbc.Driver").setDBUrl("jdbc:vertica://<Target_DB_IP>:5433/<DB Name>?user=<username>&password=<password>").setQuery("insert into <SchemaName>.<TableName> values (?,?,?)") //Parameters passed to this query should match to the number column in source table..setSqlTypes(Array(java.sql.Types.VARCHAR, java.sql.Types.VARCHAR, java.sql.Types.VARCHAR))
.finish())
env.execute("flink-test")}
}
Known Limitations
Read Mode
- For TIME, TIMETZ, and TIMESTAMPTZ data types, milliseconds are truncated.
- For BINARY, VARBINARY, and LONG VARBINARY data types, the values are not displayed correctly when previewing the data.
Write Mode
-
INTERVAL and UUID data types are not supported. To use these data types you must type cast the data types to VARCHAR.
- For TIME data type, milliseconds are rounded off to 3 digits.
- For TIMETZ data type, Null and milliseconds are not supported.
- For TIMESTAMPTZ, milliseconds are not supported.

