




Vertica Integration with Amazon Kinesis: Technical Exploration
This technical exploration details the process to load live streaming data into Vertica using Amazon Kinesis. We used a Python program to continuously generate data and load this data into the Amazon Kinesis data stream. Amazon Kinesis Data Firehose delivers this real-time streaming data to an AWS S3 bucket. Using AWS Glue, we transferred the data from the S3 bucket to Vertica for futher analysis. The following is a high level view of this process flow:
Amazon Kinesis Overview
Amazon Kinesis is a real time big data streaming service which is durable and highly scalable. You can collect, process, and analyze streaming data easily in real time and push data into the data stream from multiple sources. Amazon Kinesis can capture large amounts of data from multiple sources. Amazon Kinesis Data Firehose is a managed service that is used to load the streamed data into data stores or data lakes.
Test Environment
- AWS Environment
- Vertica Server 11.0. We used the Community Edition and installed it on AWS.
Prerequisites
- Install the AWS console on your local machine.
curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" unzip awscli-bundle.zip sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
-
After the installation, configure the AWS console. Enter the following command and you will be prompted to enter AWS access key id, region, secret key, and the default output option provided by your AWS admin.
$aws configureNote The default output format in this example is JSON.
-
You must have Vertica available on AWS.
-
All the necessary IAM permissions must work with Amazon Kinesis data stream, Amazon Kinesis Data Firehose, S3 bucket, and AWS Glue.
Connecting Amazon Kinesis to Vertica
The steps in this section load the generated sample data into Vertica.
-
Create a new data stream on Amazon Kinesis.
See the following link for information about to create an Amazon Kinesis data stream:https://docs.aws.amazon.com/streams/latest/dev/amazon-kinesis-streams.html#how-do-i-create-a-stream
Note the data stream name.
-
Use the following program to generate sample data continuously to be pushed to the AWS data stream:
import json from pprint import pprint import random import time import boto3 from faker import Faker fake = Faker() STREAM_NAME = 'TestDataStreamVertica' def employee_record(): rand_name = fake.name() rand_age = str(random.randint(25, 70)) rand_address = fake.street_address() rand_city = fake.city() rand_state = fake.country_code() temp_record = rand_name+"|" + rand_age + "|" + rand_address + "|" + rand_city + "|" + rand_state return {'Data': json.dumps(temp_record), 'PartitionKey': 'partition_key'} def generate(stream_name, batch_size, kinesis_client): while True: records = [ employee_record() for _ in range(batch_size)] pprint(records)#Prints the records generated kinesis_client.put_records(StreamName=stream_name, Records=records) time.sleep(0.1) if __name__ == "__main__": generate( stream_name=STREAM_NAME, batch_size=1, kinesis_client=boto3.client('kinesis'))Update the “STREAM._NAME” in the code with the Kinesis data stream name.
-
Run the code in python IDE. This will continuously push data to the Amazon Kinesis data stream. You should see the code generating data in the IDE console as shown:
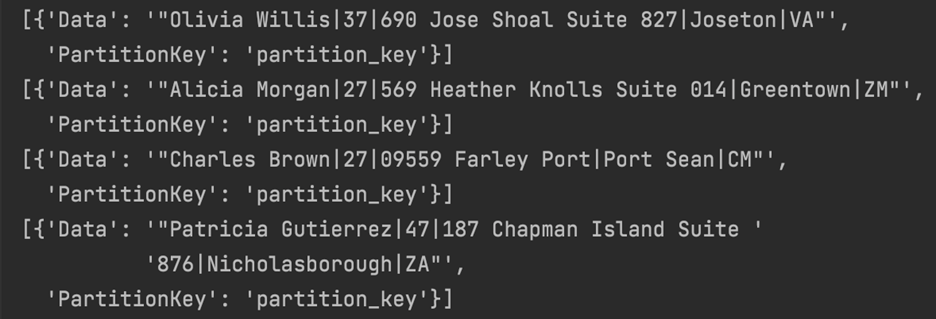
-
You can check the Amazon Kinesis data stream metrics on the AWS console to verify data is being pushed to the stream:
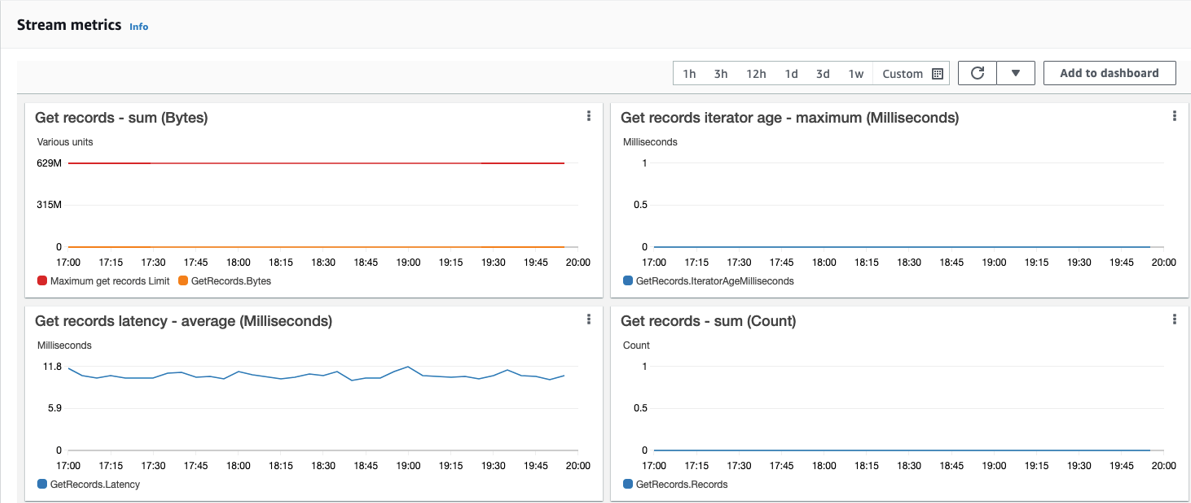
-
Create an Amazon Kinesis Data Firehose delivery stream and add the above created Amazon Kinesis data stream as the source and Amazon S3 as the destination.
- Follow the link to create the delivery stream:
https://docs.aws.amazon.com/firehose/latest/dev/create-name.html - Follow the link to create an S3 bucket using the AWS S3 Console.
https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html
Ensure that data is loaded into the S3 bucket before loading it into Vertica.
- Follow the link to create the delivery stream:
-
Using AWS Glue, load the data from the S3 bucket into Vertica. For more information, see the AWS Glue Connection Guide to know more about loading data from an S3 bucket into Vertica.
For More Information
- Amazon Kinesis website
- Amazon Kinesis Documentation
- Vertica Community Edition
- Vertica User Community
- Vertica Documentation

