Reading Structs as Expanded Columns
You can define columns in external tables to use the values from structs. Instead of reading the struct into a single column, you define columns for each field. For example, an address column could use a struct with strings for the street address, city/state, and postal code, such as { "street":"150 Cambridgepark Dr.", "city":"Cambridge MA", "postalcode":"02140"}. To read this struct, you define columns for the street address, city, and postal code.
The following example defines an external table for addresses:
=> CREATE EXTERNAL TABLE addresses (street VARCHAR, city VARCHAR, postalcode VARCHAR)
AS COPY FROM '...' PARQUET;
A struct column might be just one of several columns in the data. In the following example, the "customer" table includes a name (VARCHAR), address (struct), and account number (INT).
=> CREATE EXTERNAL TABLE customers (name VARCHAR, street VARCHAR, city VARCHAR,
postalcode VARCHAR, account INT)
AS COPY FROM '...' PARQUET;
Within Vertica the structs are flattened; from the definition alone you cannot tell that some values come from structs.
If a struct contains fields with null values, those columns have null values in Vertica. If the struct value itself is null, Vertica rejects the row by default. See Handling Null Struct Values for more information.
ORC and Parquet files do not store field names for structs, only values. When defining columns for struct values, you must use the same order that was used in the source schema. Because you must also define all of the columns represented in the data, your external table will have one column for each primitive-type column and one column for each field in each struct, in the order that they appear in the data.
Example
Consider a table defined in Hive as follows:
create external table orderupc_with_structs
(
struct1 struct<
cal_dt:varchar(200) ,
cmc_chn_str_nbr:int ,
lane_nbr:int >,
time_key int ,
struct2 struct<
tran_nbr:bigint ,
cmc_chn_nbr:int ,
str_tndr_typ_nbr:int >,
struct3 struct<
ord_amt:float ,
ss_ord_amt:float ,
ndc_ord_amt:float >,
unique_upc_qty int
)
stored as parquet location '/user/data/orderupc_with_structs'
;
The data contains three struct columns with a total of nine fields, and two other (non-struct) columns. A Hive query returns the following results:
$ hive -e "select * from orderupc_with_structs limit 1" 2> /dev/null | head -1
{"cal_dt":"2006-01-08","cmc_chn_str_nbr":85,"lane_nbr":1} 35402
{"tran_nbr":60080008501335402,"cmc_chn_nbr":2,"str_tndr_typ_nbr":1}
{"ord_amt":19.74,"ss_ord_amt":19.74,"ndc_ord_amt":0.0} 16
In Vertica you define an external table with 11 expanded columns, one for each field, as follows:
=> CREATE EXTERNAL TABLE orderupc
(
cal_dt varchar(200) ,
cmc_chn_str_nbr int ,
lane_nbr int ,
time_key int ,
tran_nbr bigint ,
cmc_chn_nbr int ,
str_tndr_typ_nbr int ,
ord_amt float ,
ss_ord_amt float ,
ndc_ord_amt float ,
unique_upc_qty int
)
AS COPY FROM 'hdfs:///user/data/orderupc_with_structs/*' PARQUET;
The struct names ("struct1" through "struct3") are not represented in these columns; instead the fields from each struct are individually defined. The following figure illustrates the mappings:
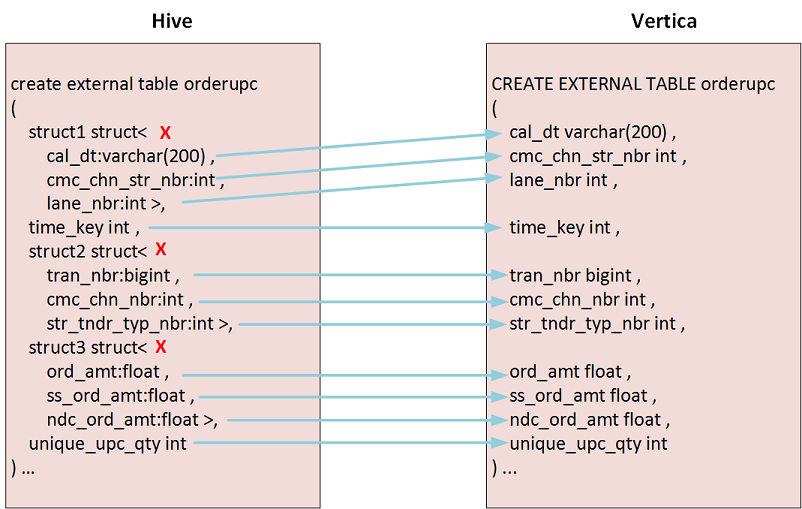
A Vertica query shows the following results:
=> SELECT * FROM orderupc LIMIT 1
cal_dt | cmc_chn_str_nbr | lane_nbr | time_key | tran_nbr |
cmc_chn_nbr | str_tndr_typ_nbr | ord_amt | ss_ord_amt |
ndc_ord_amt | unique_upc_qty
------------+-----------------+----------+----------+-------------------+
-------------+------------------+------------------+------------------+
-------------+----------------
2006-03-30 | 34362 | 3 | 47905 | 60893436201547905 |
214 | 0 | 30.7399997711182 | 30.7399997711182 |
0 | 10
(1 row)