Improving Query Performance
When working with external tables in Hadoop columnar formats, Vertica tries to improve performance in the following ways:
-
By pushing query execution closer to the data so less has to be read and transmitted. Vertica uses the following specific techniques: predicate pushdown, column selection, and partition pruning.
- By taking advantage of data locality in the query plan.
- By analyzing the row count to get the best join orders in the query plan.
The following figure illustrates optimizations that can reduce the amount of data to be read:
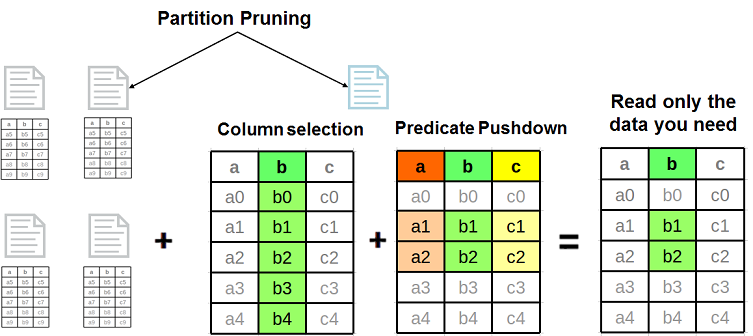
Tuning ORC Stripes and Parquet Rowgroups
Vertica can read ORC and Parquet files generated by any Hive version. However, newer Hive versions store more metadata in these files. This metadata is used by both Hive and Vertica to prune values and to read only the required data. Use the latest Hive version to store data in these formats. ORC and Parquet are fully forward- and backward-compatible. To get the best performance, use Hive 0.14 or later.
The ORC format splits a table into groups of rows called stripes and stores column-level metadata in each stripe. The Parquet format splits a table into groups of rows called rowgroups and stores column-level metadata in each rowgroup. Each stripe/rowgroup's metadata is used during predicate evaluation to determine whether the values from this stripe need to be read. Large stripes usually yield better performance, so set the stripe size to at least 256M.
Hive writes ORC stripes and Parquet rowgroups to HDFS, which stores data in HDFS blocks distributed among multiple physical data nodes. Accessing an HDFS block requires opening a separate connection to the corresponding data node. It is advantageous to ensure that an ORC stripe or Parquet rowgroup does not span more than one HDFS block. To do so, set the HDFS block size to be larger than the stripe/rowgroup size. Setting HDFS block size to 512M is usually sufficient.
Hive provides three compression options: None, Snappy, and Zlib. Use Snappy or Zlib compression to reduce storage and I/O consumption. Usually, Snappy is less CPU-intensive but can yield lower compression ratios compared to Zlib.
Storing data in sorted order can improve data access and predicate evaluation performance. Sort table columns based on the likelihood of their occurrence in query predicates; columns that most frequently occur in comparison or range predicates should be sorted first.
Partitioning tables is a very useful technique for data organization. Similarly to sorting tables by columns, partitioning can improve data access and predicate evaluation performance. Vertica supports Hive-style partitions and partition pruning.
The following Hive statement creates an ORC table with stripe size 256M and Zlib compression:
hive> CREATE TABLE customer_visits (
customer_id bigint,
visit_num int,
page_view_dt date)
STORED AS ORC tblproperties("orc.compress"="ZLIB",
"orc.stripe.size"="268435456");
The following statement creates a Parquet table with stripe size 256M and Zlib compression:
hive> CREATE TABLE customer_visits (
customer_id bigint,
visit_num int,
page_view_dt date)
STORED AS PARQUET tblproperties("parquet.compression"="ZLIB",
"parquet.stripe.size"="268435456");
Predicate Pushdown and Column Selection
Predicate pushdown moves parts of the query execution closer to the data, reducing the amount of data that must be read from disk or across the network. ORC files have three levels of indexing: file statistics, stripe statistics, and row group indexes. Predicates are applied only to the first two levels. Parquet files have two levels of statistics: rowgroup statistics and page statistics. Predicates are only applied to the first level.
Predicate pushdown is automatically applied for files written with Hive version 0.14 and later. ORC files written with earlier versions of Hive might not contain the required statistics. When executing a query against a file that lacks these statistics, Vertica logs an EXTERNAL_PREDICATE_PUSHDOWN_NOT_SUPPORTED event in the QUERY_EVENTS system table. If you are seeing performance problems with your queries, check this table for these events.
Another query performance optimization technique used by Vertica is column selection. Vertica reads from ORC or Parquet files only the columns specified in the query statement. For example, the following statement reads only the customer_id and visit_num columns from the corresponding ORC files:
=> CREATE EXTERNAL TABLE customer_visits ( customer_id bigint, visit_num int, page_view_dt date) AS COPY FROM '...' ORC; => SELECT customer_id from customer_visits WHERE visit_num > 10;
Data Locality
In a cluster where Vertica nodes are co-located on HDFS nodes, the query can use data locality to improve performance. For Vertica to do so, both the following conditions must exist::
- The data is on an HDFS node where a database node is also present.
- The query is not restricted to specific nodes using ON NODE.
When both these conditions exist, the query planner uses the co-located database node to read that data locally, instead of making a network call.
You can see how much data is being read locally by inspecting the query plan. The label for LoadStep(s) in the plan contains a statement of the form: "X% of ORC/Parquet data matched with co-located Vertica nodes". To increase the volume of local reads, consider adding more database nodes. HDFS data, by its nature, can't be moved to specific nodes, but if you run more database nodes you increase the likelihood that a database node is local to one of the copies of the data.
Creating Sorted Files in Hive
Unlike Vertica, Hive does not store table columns in separate files and does not create multiple projections per table with different sort orders. For efficient data access and predicate pushdown, sort Hive table columns based on the likelihood of their occurrence in query predicates. Columns that most frequently occur in comparison or range predicates should be sorted first.
Data can be inserted into Hive tables in a sorted order by using the ORDER BY or SORT BY keywords. For example, to insert data into the ORC table "customer_visit" from another table "visits" with the same columns, use these keywords with the INSERT INTO command:
hive> INSERT INTO TABLE customer_visits SELECT * from visits ORDER BY page_view_dt;
hive> INSERT INTO TABLE customer_visits SELECT * from visits SORT BY page_view_dt;
The difference between the two keywords is that ORDER BY guarantees global ordering on the entire table by using a single MapReduce reducer to populate the table. SORT BY uses multiple reducers, which can cause ORC or Parquet files to be sorted by the specified column(s) but not be globally sorted. Using the latter keyword can increase the time taken to load the file.
You can combine clustering and sorting to sort a table globally. The following table definition adds a hint that data is inserted into this table bucketed by customer_id and sorted by page_view_dt:
hive> CREATE TABLE customer_visits_bucketed ( customer_id bigint, visit_num int, page_view_dt date) CLUSTERED BY (page_view_dt) SORTED BY (page_view_dt)INTO 10 BUCKETS STORED AS ORC;
When inserting data into the table, you must explicitly specify the clustering and sort columns, as in the following example:
hive> INSERT INTO TABLE customer_visits_bucketed SELECT * from visits DISTRIBUTE BY page_view_dt SORT BY page_view_dt;
The following statement is equivalent:
hive> INSERT INTO TABLE customer_visits_bucketed SELECT * from visits CLUSTER BY page_view_dt;
Both of the above commands insert data into the customer_visits_bucketed table, globally sorted on the page_view_dt column.
Partitioning Hive Tables
Table partitioning in Hive is an effective technique for data separation and organization, as well as for reducing storage requirements. To partition a table in Hive, include it in the PARTITIONED BY clause:
hive> CREATE TABLE customer_visits ( customer_id bigint, visit_num int) PARTITIONED BY (page_view_dt date) STORED AS ORC;
Hive does not materialize partition column(s). Instead, it creates subdirectories of the following form:
path_to_table/partition_column_name=value/
When the table is queried, Hive parses the subdirectories' names to materialize the values in the partition columns. The value materialization in Hive is a plain conversion from a string to the appropriate data type.
Inserting data into a partitioned table requires specifying the value(s) of the partition column(s). The following example creates two partition subdirectories, "customer_visits/page_view_dt=2016-02-01" and "customer_visits/page_view_dt=2016-02-02":
hive> INSERT INTO TABLE customer_visits PARTITION (page_view_dt='2016-02-01') SELECT customer_id, visit_num from visits WHERE page_view_dt='2016-02-01' ORDER BY page_view_dt; hive> INSERT INTO TABLE customer_visits PARTITION (page_view_dt='2016-02-02') SELECT customer_id, visit_num from visits WHERE page_view_dt='2016-02-02' ORDER BY page_view_dt;
Each directory contains ORC files with two columns, customer_id and visit_num.
Accessing Partitioned Data from Vertica
Vertica recognizes and supports Hive-style partitions. You can read partition values and data using the HCatalog Connector or the COPY statement.
If you use the HCatalog Connector, you must create an HCatalog schema in Vertica that mirrors a schema in Hive:
=> CREATE EXTERNAL TABLE customer_visits (customer_id int, visit_num int, page_view_dtm date) AS COPY FROM 'hdfs://host:port/path/customer_visits/*/*' ORC (hive_partition_cols='page_view_dtm');
The following statement reads all ORC files stored in all sub-directories including the partition values:
=> SELECT customer_id, visit_num, page_view FROM customer_visits;
When executing queries with predicates on partition columns, Vertica uses the subdirectory names to skip files that do not satisfy the predicate. This process is called partition pruning.
You can also define a separate external table for each subdirectory, as in the following example:
=> CREATE EXTERNAL TABLE customer_visits_20160201 (customer_id int, visit_num int, page_view_dtm date) AS COPY FROM 'hdfs://host:port/path/customer_visits/page_view_dt=2016-02-01/*' ORC;
Example: A Partitioned, Sorted ORC Table
Suppose you have data stored in CSV files containing three columns: customer_id, visit_num, page_view_dtm:
1,123,2016-01-01 33,1,2016-02-01 2,57,2016-01-03 ...
The goal is to create the following Hive table:
hive> CREATE TABLE customer_visits ( customer_id bigint, visit_num int) PARTITIONED BY (page_view_dt date) STORED AS ORC;
To achieve this, perform the following steps:
- Copy or move the CSV files to HDFS.
-
Define a textfile Hive table and copy the CSV files into it:
hive> CREATE TABLE visits ( customer_id bigint, visit_num int, page_view_dt date) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; hive> LOAD DATA INPATH path_to_csv_files INTO TABLE visits;
-
For each unique value in page_view_dt, insert the data into the target table while materializing page_view_dt as page_view_dtm:
hive> INSERT INTO TABLE customer_visits PARTITION (page_view_dt='2016-01-01') SELECT customer_id, visit_num FROM visits WHERE page_view_dt='2016-01-01' ORDER BY page_view_dt; ...
This operation inserts data from visits.customer_id into customer_visits.customer_id, and from visits.visit_num into customer_visits.visit_num. These two columns are stored in generated ORC files. Simultaneously, values from visits.page_view_dt are used to create partitions for the partition column customer_visits.page_view_dt, which is not stored in the ORC files.
Data Modification in Hive
Hive is well-suited for reading large amounts of write-once data. Its optimal usage is loading data in bulk into tables and never modifying the data. In particular, for data stored in the ORC and Parquet formats, this usage pattern produces large, globally (or nearly globally) sorted files.
Periodic addition of data to tables (known as “trickle load”) is likely to produce many small files. The disadvantage of this is that Vertica has to access many more files during query planning and execution. These extra access can result in longer query-processing time. The major performance degradation comes from the increase in the number of file seeks on HDFS.
Hive can also modify underlying ORC or Parquet files without user involvement. If enough records in a Hive table are modified or deleted, for example, Hive deletes existing files and replaces them with newly-created ones. Hive can also be configured to automatically merge many small files into a few larger files.
When new tables are created, or existing tables are modified in Hive, you must manually synchronize Vertica to keep it up to date. The following statement synchronizes the Vertica schema "hcat" after a change in Hive:
=> SELECT sync_with_hcatalog_schema('hcat_local', 'hcat');
Schema Evolution in Hive
Hive supports two kinds of schema evolution:
-
New columns can be added to existing tables in Hive. Vertica automatically handles this kind of schema evolution. The old records display NULLs for the newer columns.
-
The type of a column for a table can be modified in Hive. Vertica does not support this kind of schema evolution.
The following example demonstrates schema evolution through new columns. In this example, hcat.parquet.txt is a file with the following values:
-1|0.65|0.65|6|'b'
hive> create table hcat.parquet_tmp (a int, b float, c double, d int, e varchar(4))
row format delimited fields terminated by '|' lines terminated by '\n';
hive> load data local inpath 'hcat.parquet.txt' overwrite into table
hcat.parquet_tmp;
hive> create table hcat.parquet_evolve (a int) partitioned by (f int) stored as
parquet;
hive> insert into table hcat.parquet_evolve partition (f=1) select a from
hcat.parquet_tmp;
hive> alter table hcat.parquet_evolve add columns (b float);
hive> insert into table hcat.parquet_evolve partition (f=2) select a, b from
hcat.parquet_tmp;
hive> alter table hcat.parquet_evolve add columns (c double);
hive> insert into table hcat.parquet_evolve partition (f=3) select a, b, c from
hcat.parquet_tmp;
hive> alter table hcat.parquet_evolve add columns (d int);
hive> insert into table hcat.parquet_evolve partition (f=4) select a, b, c, d from
hcat.parquet_tmp;
hive> alter table hcat.parquet_evolve add columns (e varchar(4));
hive> insert into table hcat.parquet_evolve partition (f=5) select a, b, c, d, e
from hcat.parquet_tmp;
hive> insert into table hcat.parquet_evolve partition (f=6) select a, b, c, d, e
from hcat.parquet_tmp;
=> SELECT * from hcat_local.parquet_evolve;
a | b | c | d | e | f
----+-------------------+------+---+---+---
-1 | | | | | 1
-1 | 0.649999976158142 | | | | 2
-1 | 0.649999976158142 | 0.65 | | | 3
-1 | 0.649999976158142 | 0.65 | 6 | | 4
-1 | 0.649999976158142 | 0.65 | 6 | b | 5
-1 | 0.649999976158142 | 0.65 | 6 | b | 6
(6 rows)