CROSS_VALIDATE
Performs k-fold cross validation on a learning algorithm using an input relation, and grid search for hyper parameters. The output is an average performance indicator of the selected algorithm. This function supports SVM classification, naive bayes, and logistic regression.
Syntax
CROSS_VALIDATE ( 'algorithm', 'input‑relation', 'response‑column', 'predictor‑columns' [ USING PARAMETERS [exclude_columns='excluded‑columns'] [, cv_model_name='model'] [, cv_metrics='metrics'] [, cv_fold_count=num‑folds] [, cv_hyperparams='hyperparams'] [, cv_prediction_cutoff=prediction‑cutoff] ] )
Arguments
| algorithm |
Name of the algorithm training function, one of the following: |
| input‑relation |
The table or view that contains data used for training and testing. If the input relation is defined in Hive, use |
| response‑column |
Name of the input column that contains the response. |
| predictor‑columns |
Comma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter |
Parameter Settings
| Parameter name | Set to… |
|---|---|
exclude_columns
|
Comma-separated list of columns from predictor‑columns to exclude from processing. |
cv_model_name
|
The name of a model that lets you retrieve results of the cross validation process. If you omit this parameter, results are displayed but not saved. If you set this parameter to a model name, you can retrieve the results with summary functions |
|
The metrics used to assess the algorithm, specified either as a comma-separated list of metric names or in a JSON array. In both cases, you specify one or more of the following metric names:
|
|
cv_fold_count
|
The number of folds to split the data. Default: 5 |
cv_hyperparams
|
A JSON string that describes the combination of parameters for use in grid search of hyper parameters. The JSON string contains pairs of the hyper parameter name. The value of each hyper parameter can be specified as an array or sequence. For example: {"param1":[value1,value2,…], "param2":{"first":first_value, "step":step_size, "count":number_of_values} }
Hyper parameter names and string values should be quoted using the JSON standard. These parameters are passed to the training function. |
cv_prediction_cutoff
|
The cutoff threshold that is passed to the prediction stage of logistic regression, a FLOAT between 0 and 1, exclusive Default: 0.5 |

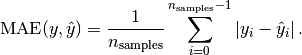
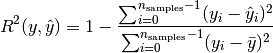
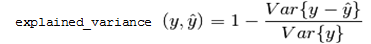
Model Attributes
| Attribute | Description |
|---|---|
call_string
|
The value of all input arguments that were specified at the time CROSS_VALIDATE was called. |
run_average
|
The average across all folds of all metrics specified in parameter |
fold_info
|
The number of rows in each fold:
|
counters
|
All counters for the function, including:
|
run_details
|
Information about each run, where a run means training a single model, and then testing that model on the one held-out fold:
|
Privileges
Non-superusers:
- SELECT privileges on the input relation
- CREATE and USAGE privileges on the default schema where machine learning algorithms generate models. If
cv_model_nameis provided, the cross validation results are saved as a model in the same schema.
Specifying Metrics in JSON
Parameter cv_metrics can specify metrics as an array of JSON objects, where each object specifies a metric name . For example, the following expression sets cv_metrics to two metrics specified as JSON objects, accuracy and error_rate:
cv_metrics='["accuracy", "error_rate"]'
In the next example, cv_metrics is set to two metrics, accuracy and TPR (true positive rate). Here, the TPR metric is specified as a JSON object that takes an array of two class label arguments, 2 and 3:
cv_metrics='[ "accuracy", {"TPR":[2,3] } ]'
Metrics specified as JSON objects can accept parameters. In the following example, the fscore metric specifies parameter beta, which is set to 0.5:
cv_metrics='[ {"fscore":{"beta":0.5} } ]'
Parameter support can be especially useful for certain metrics. For example, metrics auc_roc and auc_prc build a curve, and then compute the area under that curve. For ROC, the curve is formed by plotting metrics TPR against FPR; for PRC, PPV (precision) against TPR (recall). The accuracy of such curves can be increased by setting parameter num_bins to a value greater than the default value of 100. For example, the following expression computes AUC for an ROC curve built with 1000 bins:
cv_metrics='[{"auc_roc":{"num_bins":1000}}]'
Using Metrics with Multi‑class Classifier Functions
All supported metrics are defined for binary classifier functions LOGISTIC_REG and SVM_CLASSIFIER. For multi-class classifier functions such as NAIVE_BAYES, these metrics can be calculated for each one-versus-the-rest binary classifier. Use arguments to request the metrics for each classifier. For example, if training data has integer class labels, you can set cv_metrics with the precision (PPV) metric as follows:
cv_metrics='[{"precision":[0,4]}]'
This setting specifies to return two columns with precision computed for two classifiers:
- Column 1: classifies 0 versus not 0
- Collumn 2: classifies 4 versus not 4
If you omit class label arguments, the class with index 1 is used. Instead of computing metrics for individual one-versus-the-rest classifiers, the average is computed in one of the following styles: macro, micro, or weighted (default). For example, the following cv_metrics setting returns the average weighted by class sizes:
cv_metrics='[{"precision":{"avg":"weighted"}}]'
AUC-type metrics can be similarly defined for multi-class classifiers. For example, the following cv_metrics setting computes the area under the ROC curve for each one-versus-the-rest classifier, and then returns the average weighted by class sizes.
cv_metrics='[{"auc_roc":{"avg":"weighted", "num_bins":1000}}]'
Examples
=> SELECT CROSS_VALIDATE('svm_classifier', 'mtcars', 'am', 'mpg'
USING PARAMETERS cv_fold_count= 6,
cv_hyperparams='{"C":[1,5]}',
cv_model_name='cv_svm',
cv_metrics='accuracy, error_rate');
CROSS_VALIDATE
----------------------------
Finished
===========
run_average
===========
C |accuracy |error_rate
---+--------------+----------
1 | 0.75556 | 0.24444
5 | 0.78333 | 0.21667
(1 row)