Sequence Caching
Caching is similar for all sequence types: named sequences, identity sequences, and auto-increment sequences. To allocate cache among the nodes in a cluster for a given sequences, Vertica uses the following process.
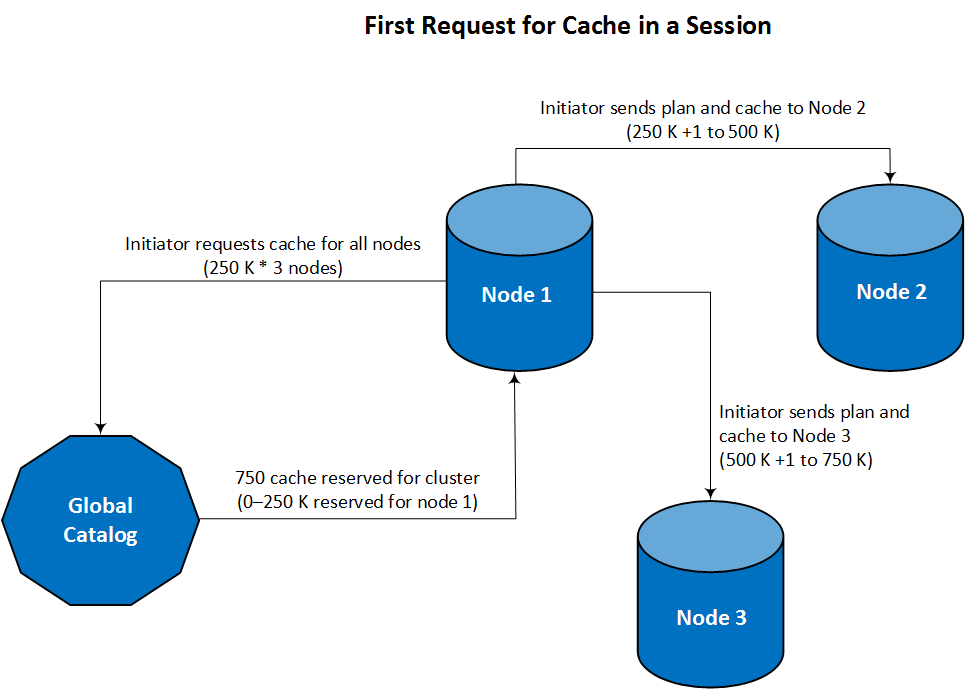
- By default, when a session begins, the cluster initiator node requests cache for itself and other nodes in the cluster.
- The initiator node distributes cache to other nodes when it distributes the execution plan.
- Because the initiator node requests caching for all nodes, only the initiator locks the global catalog for the cache request.
This approach is optimal for handling large INSERT-SELECT and COPY operations. The following figure shows how the initiator request and distributes cache for a named sequence in a three-node cluster, where caching for that sequence is set to 250 K:
Nodes run out of cache at different times. While executing the same query, nodes individually request additional cache as needed.
For new queries in the same session, the initiator might have an empty cache if it used all of its cache to execute the previous query execution. In this case, the initiator requests cache for all nodes.
You can change how nodes obtain sequence caches by setting the configuration parameter ClusterSequenceCacheMode to 0 (disabled). When this parameter is set to 0, all nodes in the cluster request their own cache and catalog lock. However, for initial large INSERT-SELECT and COPY operations, when the cache is empty for all nodes, each node requests cache at the same time. These multiple requests result in multiple simultaneous locks on the global catalog, which can adversely affect performance. For this reason, ClusterSequenceCacheMode should remain set to its default value of 1 (enabled).
The following example compares how different settings of ClusterSequenceCacheMode affect how Vertica manages sequence caching. The example assumes a three-node cluster, 250 K caches for each node (the default), and sequence ID values that increment by 1.
|
Workflow step |
ClusterSequenceCacheMode = 1 | ClusterSequenceCacheMode = 0 |
|---|---|---|
|
1 |
Cache is empty for all nodes. Initiator node requests 250 K cache for each node. |
Cache is empty for all nodes. Each node, including initiator, requests its own 250 K cache. |
| 2 |
Blocks of cache are distributed to each node as follows:
Each node begins to use its cache as it processes sequence updates. |
|
| 3 |
Initiator node and node 3 run out of cache. Node 2 only uses 250 K +1 to 400 K, 100 K of cache remains from 400 K +1 to 500 K. |
|
| 4 |
Executing same statement:
Executing a new statement in same session, if initiator node cache is empty:
|
Executing same or new statement:
|