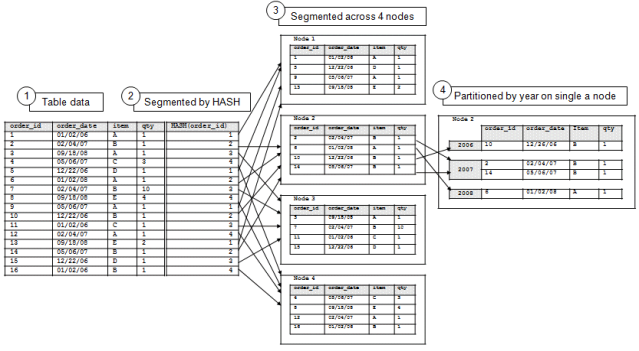
Partitioning and Segmentation
In Vertica, partitioning and segmentation are separate concepts and achieve different goals to localize data:
- Segmentation refers to organizing and distributing data across cluster nodes for fast data purges and query performance. Segmentation aims to distribute data evenly across multiple database nodes so all nodes participate in query execution. You specify segmentation with the
CREATE PROJECTIONstatement's hash segmentation clause. - Partitioning specifies how to organize data within individual nodes for distributed computing. Node partitions let you easily identify data you wish to drop and help reclaim disk space. You specify partitioning with the
CREATE TABLEstatement'sPARTITION BYclause.
For example: partitioning data by year makes sense for retaining and dropping annual data. However, segmenting the same data by year would be inefficient, because the node holding data for the current year would likely answer far more queries than the other nodes.
The following diagram illustrates the flow of segmentation and partitioning on a four-node database cluster:
- Example table data
- Data segmented by
HASH(order_id) - Data segmented by hash across four nodes
- Data partitioned by year on a single node
While partitioning occurs on all four nodes, the illustration shows partitioned data on one node for simplicity.