Choosing Sort Order: Best Practices
When choosing sort orders for your projections, Vertica has several recommendations that can help you achieve maximum query performance, as illustrated in the following examples.
Combine RLE and Sort Order
When dealing with predicates on low-cardinality columns, use a combination of RLE and sorting to minimize storage requirements and maximize query performance.
Suppose you have a students table contain the following values and encoding types:
| Column | # of Distinct Values | Encoded With |
|---|---|---|
gender |
2 (M or F) |
RLE |
pass_fail |
2 (P or F) |
RLE |
class |
4 (freshman, sophomore, junior, or senior) |
RLE |
name |
10000 (too many to list) |
Auto |
You might have queries similar to this one:
SELECT name FROM studentsWHERE gender = 'M' AND pass_fail = 'P' AND class = 'senior';
The fastest way to access the data is to work through the low-cardinality columns with the smallest number of distinct values before the high-cardinality columns. The following sort order minimizes storage and maximizes query performance for queries that have equality restrictions on gender, class, pass_fail, and name. Specify the ORDER BY clause of the projection as follows:
ORDER BY students.gender, students.pass_fail, students.class, students.name
In this example, the gender column is represented by two RLE entries, the pass_fail column is represented by four entries, and the class column is represented by 16 entries, regardless of the cardinality of the students table. Vertica efficiently finds the set of rows that satisfy all the predicates, resulting in a huge reduction of search effort for RLE encoded columns that occur early in the sort order. Consequently, if you use low-cardinality columns in local predicates, as in the previous example, put those columns early in the projection sort order, in increasing order of distinct cardinality (that is, in increasing order of the number of distinct values in each column).
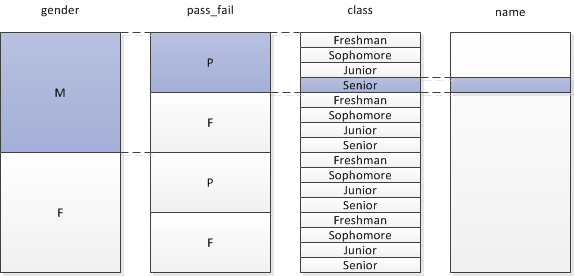
If you sort this table with student.class first, you improve the performance of queries that restrict only on the student.class column, and you improve the compression of the student.class column (which contains the largest number of distinct values), but the other columns do not compress as well. Determining which projection is better depends on the specific queries in your workload, and their relative importance.
Storage savings with compression decrease as the cardinality of the column increases; however, storage savings with compression increase as the number of bytes required to store values in that column increases.
Maximize the Advantages of RLE
To maximize the advantages of RLE encoding, use it only when the average run length of a column is greater than 10 when sorted. For example, suppose you have a table with the following columns, sorted in order of cardinality from low to high:
address.country, address.region, address.state, address.city, address.zipcode
The zipcode column might not have 10 sorted entries in a row with the same zip code, so there is probably no advantage to run-length encoding that column, and it could make compression worse. But there are likely to be more than 10 countries in a sorted run length, so applying RLE to the country column can improve performance.
Put Lower Cardinality Column First for Functional Dependencies
In general, put columns that you use for local predicates (as in the previous example) earlier in the join order to make predicate evaluation more efficient. In addition, if a lower cardinality column is uniquely determined by a higher cardinality column (like city_id uniquely determining a state_id), it is always better to put the lower cardinality, functionally determined column earlier in the sort order than the higher cardinality column.
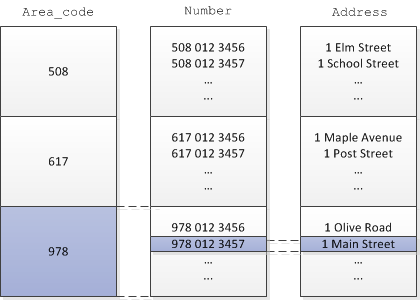
For example, in the following sort order, the Area_Code column is sorted before the Number column in the customer_info table:
ORDER BY = customer_info.Area_Code, customer_info.Number, customer_info.Address
In the query, put the Area_Code column first, so that only the values in the Number column that start with 978 are scanned.
=> SELECT AddressFROM customer_info WHERE Area_Code='978' AND Number='9780123457';
Sort for Merge Joins
When processing a join, the Vertica optimizer chooses from two algorithms:
- Merge join—If both inputs are pre-sorted on the join column, the optimizer chooses a merge join, which is faster and uses less memory.
- Hash join—Using the hash join algorithm, Vertica uses the smaller (inner) joined table to build an in-memory hash table on the join column. A hash join has no sort requirement, but it consumes more memory because Vertica builds a hash table with the values in the inner table. The optimizer chooses a hash join when projections are not sorted on the join columns.
If both inputs are pre-sorted, merge joins do not have to do any pre-processing, making the join perform faster. Vertica uses the term sort-merge join to refer to the case when at least one of the inputs must be sorted prior to the merge join. Vertica sorts the inner input side but only if the outer input side is already sorted on the join columns.
To give the Vertica query optimizer the option to use an efficient merge join for a particular join, create projections on both sides of the join that put the join column first in their respective projections. This is primarily important to do if both tables are so large that neither table fits into memory. If all tables that a table will be joined to can be expected to fit into memory simultaneously, the benefits of merge join over hash join are sufficiently small that it probably isn't worth creating a projection for any one join column.
Sort on Columns in Important Queries
If you have an important query, one that you run on a regular basis, you can save time by putting the columns specified in the WHERE clause or the GROUP BY clause of that query early in the sort order.
If that query uses a high-cardinality column such as Social Security number, you may sacrifice storage by placing this column early in the sort order of a projection, but your most important query will be optimized.
Sort Columns of Equal Cardinality By Size
If you have two columns of equal cardinality, put the column that is larger first in the sort order. For example, a CHAR(20) column takes up 20 bytes, but an INTEGER column takes up 8 bytes. By putting the CHAR(20) column ahead of the INTEGER column, your projection compresses better.
Sort Foreign Key Columns First, From Low to High Distinct Cardinality
Suppose you have a fact table where the first four columns in the sort order make up a foreign key to another table. For best compression, choose a sort order for the fact table such that the foreign keys appear first, and in increasing order of distinct cardinality. Other factors also apply to the design of projections for fact tables, such as partitioning by a time dimension, if any.
In the following example, the table inventory stores inventory data, and product_key and warehouse_key are foreign keys to the product_dimension and warehouse_dimension tables:
=> CREATE TABLE inventory ( date_key INTEGER NOT NULL, product_key INTEGER NOT NULL, warehouse_key INTEGER NOT NULL, ... ); => ALTER TABLE inventory ADD CONSTRAINT fk_inventory_warehouse FOREIGN KEY(warehouse_key) REFERENCES warehouse_dimension(warehouse_key); ALTER TABLE inventory ADD CONSTRAINT fk_inventory_product FOREIGN KEY(product_key) REFERENCES product_dimension(product_key);
The inventory table should be sorted by warehouse_key and then product, since the cardinality of the warehouse_key column is probably lower that the cardinality of the product_key.