


Exploring the Vertica Guaranteed Uniqueness Optimization
Most of us have had that moment. The moment where were scrolling through available titles on an online streaming service and come across a bizarre sub-category like independent films where the dog dies at the end. Then you see the movie again, this time under heartwarming family film or movies based on books. What if someone were to ask you how many titles you have to choose from? Would you scroll through every obscure category? Hardly. You would find a way to list unique values and use some type of optimized method to display them. While hopefully no one has ever asked you to do this, there might be situations where a similar task is asked of you.
Consider the following scenario: you have an online company and want to figure out to what regions your customers typically order products. If, for example, a region never shows up in your records, you might consider removing or scaling down a warehouse in that location. To perform this analysis, you could display the region column from every transaction ever and then scroll through thousands of records to see which regions are not represented. But that might take a long time. A really long time.

You may already know about the various options Vertica provides for retrieving unique values from a column (for example, the SELECT DISTINCT operation). Now, with the new guaranteed uniqueness optimization feature in Vertica 7.2.2, Vertica automatically recognizes when a query is accessing columns with unique values and optimizes the query operations that would otherwise be bogged down due to duplicate values.
In short, if you run a query that has a column that you know for a fact contains only unique values, there are situations where Vertica can take advantage of this fact and optimize that query.
When Guaranteed Uniqueness Optimization Helps
Although Vertica automatically identifies columns in a query that guarantee uniqueness, its helpful if you can identify these as well. Columns that can be guaranteed to include unique values include:
- Columns that are defined with AUTO_INCREMENT or IDENTITY constraints
- Primary key columns where key constraints are enforced
- Columns that are constrained to unique values, either individually or as a set.
- A column that is an output from one of the following SELECT statement options that, by nature, results in unique values:
- GROUP BY: Groups by a specified column so that like values are included in only one row.
- DISTINCT: Returns only distinct values.
- UNION: Combines results from multiple SELECT statements and returns unique rows.
- INTERSECT: Calculates the intersection of the results of two or more SELECT queries and returns distinct values by both the query on the left and right sides of the INTERSECT operand.
- EXCEPT: Combines two or more SELECT queries and returns distinct results of the left-hand query that are not also found in the right-hand query.
Vertica can optimize queries when the above columns are included in the following operations:
- Left or right outer join
- GROUP BY clause
- ORDER BY clause
The above operations do not require additional processing that would otherwise be necessary if the table contained duplicates.
Lets use our online company scenario as an example.
In one table you have a list of cities where you have warehouses (warehouse_locations). In another table, you have a list of orders (orders):
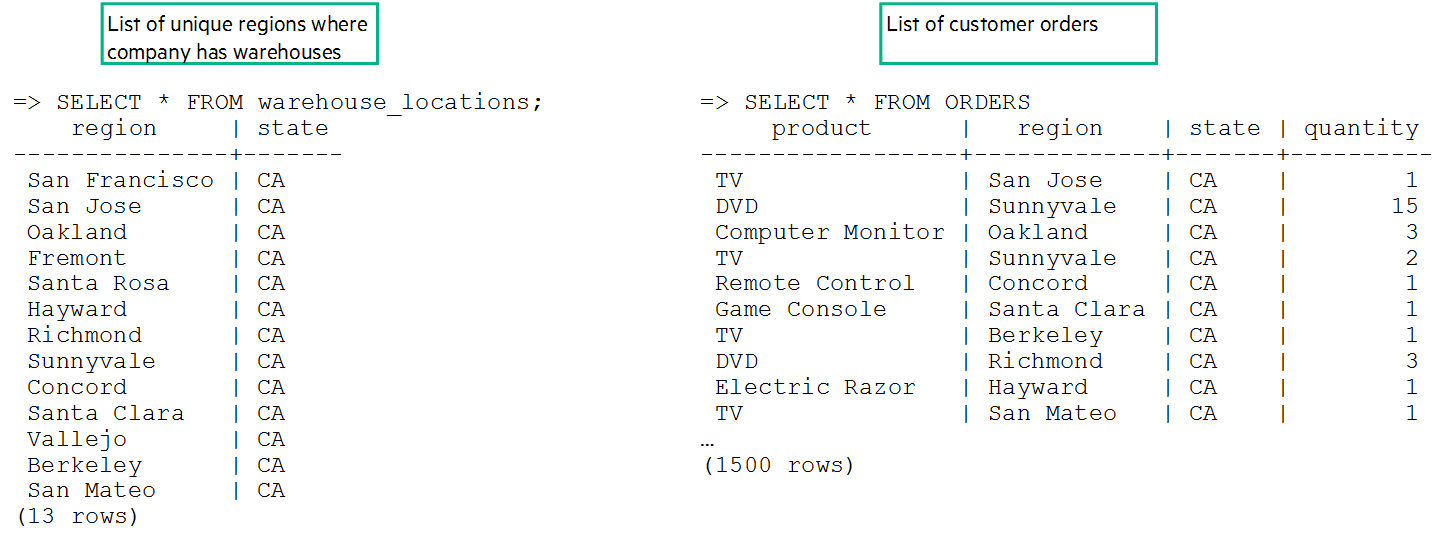
If you want to find a list of warehouse regions that are with associated orders, you can perform a left outer join:
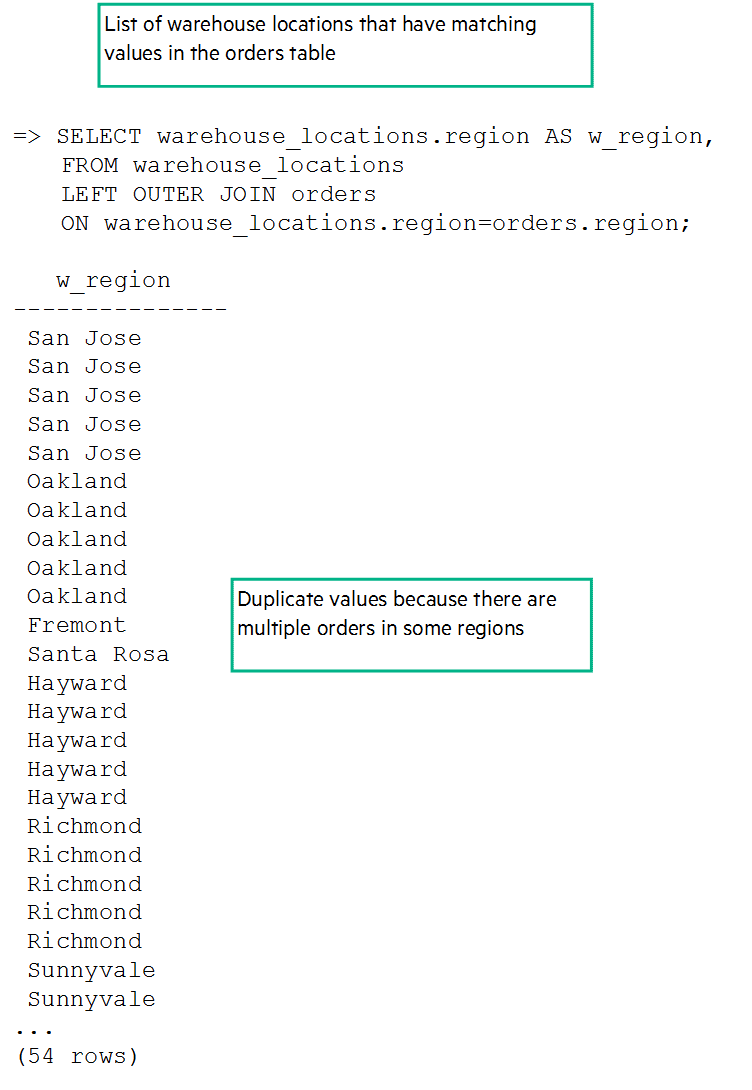
But, as you can see, there are 54 rows and a number of duplicates. Lets create a view with the SELECT DISTINCT statement so we have a list of unique regions to which customer ordered:

Now, when we perform a left outer join with the view instead of the orders table, we see only one value for each region:

So where does guaranteed uniqueness optimization come in? Well, since we are materializing every value in the region column in the warehouse_locations table (because left outer joins preserve the left table), and we know every column in the unique_orders view is unique (due to the SELECT DISTINCT statement), we can guarantee that there will be no duplicates in the w_region column (the result of a left outer join on warehouse_locations.region and unique_orders.region).
Using EXPLAIN, we can verify guaranteed uniqueness optimization is working:
=> EXPLAIN SELECT warehouse_locations.region AS w_region
FROM warehouse_locations
LEFT OUTER JOIN unique_orders ON
warehouse_locations.region=unique_orders.region;
EnableUniquenessOptimization is on
The following JGNodes/Tables have been pruned due to uniqueness guarantee:
Node 1 unique_orders (public.orders)
Access Path:
+-STORAGE ACCESS for warehouse_locations [Cost: 5, Rows: 13 (NO STATISTICS)]
(PATH ID: 1)
| Projection: public.warehouse_locations_super
| Materialize: warehouse_locations.region
As you can see from the EXPLIAN output, that by using guaranteed uniqueness optimization with our join query, Vertica doesnt even need to consider any table but warehouse_locations! Vertica will detect that the region column in the unique_orders table contains unique values and, because youre performing a left outer join, Vertica know that it doesnt have to deal with that table at all, saving time and energy.
Thus, the results of this left outer join are the same as if we were to run the following query:
=> SELECT region FROM warehouse_locations;
The following graphic sums up the previous workflow:
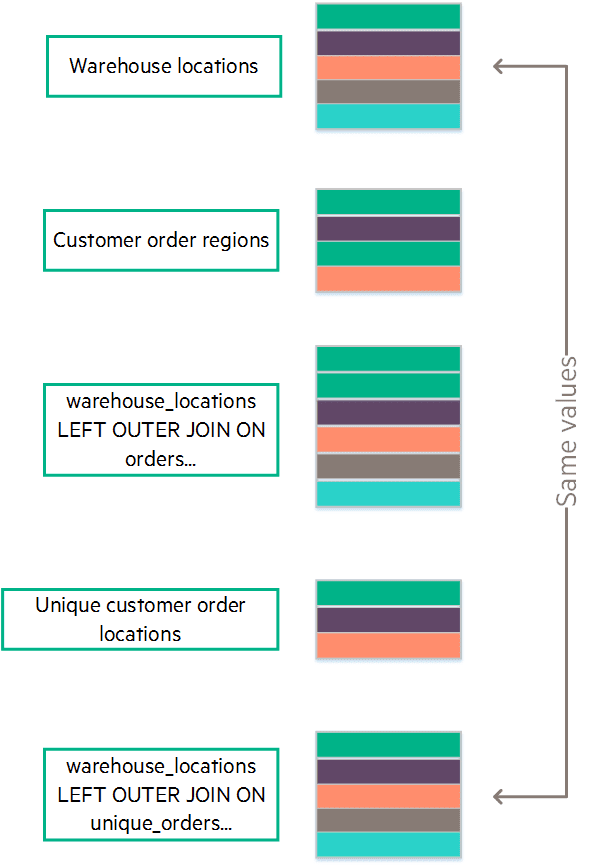
Right outer joins work in a similar way. Conversely, a full outer join always requires grabbing data from both tables, even if you are only materializing columns that exist in one table. Thus, a full outer join does not qualify for guaranteed uniqueness optimization.
Similarly, Vertica can employ guaranteed uniqueness optimization when unique columns are within the GROUP BY clause. This is because without duplicate values, there is no need to do any grouping. With the ORDER BY clause, if there are no duplicates, Vertica only has to order on the specified unique column and wont have to move on to additional columns, as it would if values in the first column were not unique.
Enabling Guaranteed Uniqueness Optimization
You enable guaranteed uniqueness optimization at the database or session level through the configuration parameter EnableUniquenessOptimization. By default, this parameter is set to 1 (enabled).
To disable, set this parameter to 0. For example:
=> ALTER SESSION SET EnableUniquenessOptimization=0;
In Conclusion
With the new guaranteed uniqueness optimization feature, you can rest assured that you get the results you need with minimal effort; Vertica will access the information it needs, and nothing else . Whether you decide to apply this to your movie choices, is a different matter entirely. In the meantime revel in the fact that this process is automatic! You can also choose to manually add column constraints to further streamline the process. Stay tuned for more blogs on uniqueness!
About the Author
Sarah Lemaire
Manager, Vertica Documentation



