This blog post was co-authored by Yassine Faihe, Michael Flower, and Moshe Goldberg.
Updating One Million Records in Two Seconds
To illustrate the true power of MERGE, this article describes how we used MERGE to
demonstrate Vertica’s performance at scale.
SQL MERGE statements combine INSERT and UPDATE operations. They are a great
way to update by inserting a small (<1000), or large (>1 million) number of records from a
source table into a target table. The source table can include new and existing data. If
the target table does not include any of the source table’s records (new or existing),
MERGE inserts all source data into the target. The following is a MERGE example with two MERGE options that you update (WHEN MATCHED THEN
UPDATE…) or insert data (WHEN NOT MATCHED THEN INSERT…).
MERGE INTO target TGT
USING source SRC
ON SRC.A=TGT.A
WHEN MATCHED THEN
UPDATE SET A=SRC.A, B=SRC.B, C=SRC.C, D=SRC.D, E=SRC.E
WHEN NOT MATCHED THEN
INSERT VALUES (SRC.A,SRC.B, SRC.C, SRC.D, SRC.E);
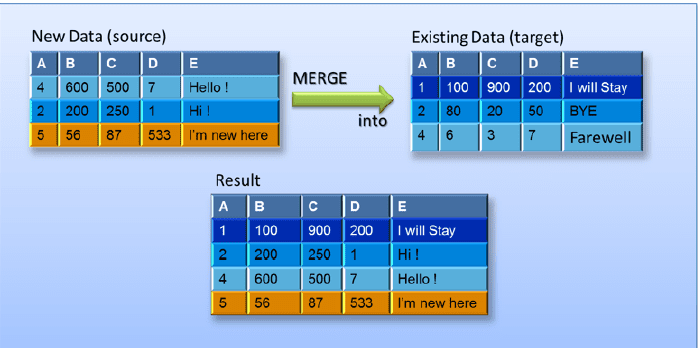
This diagram illustrates the results of merging data into an existing target table:
To realize the full potential of MERGE, both tables in the MERGE statement must meet
a set of conditions. When tables meet such conditions, Vertica optimizes the statements
to significantly improve performance.
This article describes using MERGE to address a set of customer requirements. By
meeting all of the required MERGE conditions, we saw spectacular performance results:
updating one million records in two seconds. We also illustrate how to convert a non-optimized
merge into an optimized one, and explain, and include the script used to do
so. For many more details about the MERGE statement, see
Improving MERGE Performance in the Vertica documentation.
Putting MERGE to Work
Initially, our customer requested that we update one million records in a target fact table,
pre-populated with dozens of columns and billions of rows. We ran some internal
MERGE performance tests to benchmark results. These tests updated several columns
and dozens of fields, with promising results: 30 seconds. By updating even fewer
columns, initial results improved: decreasing from 30 seconds to 8 seconds. The 8-second result
seemed to meet our customer’s request.
Still, we had many preconceptions about Vertica updates, especially our assumption
that adding more fields would reduce performance. We did not consider the
opposite possibility: that we could increase performance by adding more fields. We
were about to uncover our faulty assumptions, totally changing our misconceptions.
After presenting our 8-second test results to the customer, their next request was to
make similar updates, this time with a heavy query workload in process. Determined to
address all customer requests, we continued.
Meeting Optimized Query Plan Conditions
Our first task was to change the MERGE statement to meet all of the required conditions
for optimization:
- Target table’s join column has a unique or primary key constraint
- UPDATE and INSERT clauses include every column in the target table
- UPDATE and INSERT clause column attributes are identical
- Source table is smaller than the target table
After meeting these conditions, Vertica prepared an optimized query plan and ran much
faster. When conditions were not met, Vertica prepared a non-optimized query plan, and
performance decreased. The decreased result was similar to earlier Vertica releases
before optimized MERGE was available.
Optimized Query Plan Benchmark Results
Here are the benchmark results when we met all the optimized query plan conditions.
These tests all used the MERGE statement with the same fact table, which had 2.7B
rows, and dozens of fields. Test iterations used different data:
| Description |
Seconds |
| UPDATE 1 million records, dozens of fields, in a table with 2.7B rows, no
background queries |
2.2 |
| UPDATE 1 million records, dozens of fields, in the same table, with
background queries running |
2.5 |
| INSERT 1 million records into the same fact table, with background
queries running |
1.4 |
| Use a MERGE statement with the same table to INSERT 500K records
and UPDATE 500K records, with background queries running |
13.0 |
Given these results, we wondered if the UPDATE performance behavior is linear? The
answer is Yes, as shown by the following UPDATE benchmarks:
| Description |
Seconds |
| Update 100 million records, dozens of fields, in the same target fact table,
but with ~3B rows, without background queries running |
220 |
| Update 100 million records, dozens of fields, in the same target fact table,
but with ~3B rows, with background queries running |
250 |
While testing our optimized MERGE statement syntax (with UPDATE and INSERT
clauses) we made these additional conclusions:
• Performance increased significantly when the source table data caused only
UPDATES, or only INSERTS.
• Performance decreased when the source table data caused a mix of INSERTs and
UPDATEs in the same statement.
Note: All results were generated with the maximum input/output operations per
second (IOPS) possible on a DL380p lab system, with two CPUs, and only 12
internal commodity disk drives. Running the benchmarks on the same system with
22 disks would result in almost twice the number of IOPS, and even more
impressive performance.
Converting to an Optimized MERGE
Nobody wants a MERGE statement that is not optimized, but sometimes it’s hard to avoid.
Fortunately, you can convert a non-optimized MERGE into an optimized
version. We’re including the full script we used
OptimizeMERGE_Script. The script illustrates how we
create an optimized MERGE version, by avoiding right outer joins.
In our test, we created a source table with three fields from the target table, using a non-optimized
query.
Next, we updated 1 million records. Then, we inserted another million records, based on
three fields in the SOURCE table. Separating the UPDATE and INSERT activities into
the same TARGET table using an Optimized Merge took 7.6 seconds (including the
convert time). So, the starting point is that we do not have all of the fields. Updating only
two fields does not fulfill the optimized MERGE query plan conditions. Here are descriptions of the script steps and their completion times:
| Test Phase |
Phases to Convert Non-Optimized MERGE to Optimized |
Time (ms) |
| Preparation |
Create a SOURCE table, containing three fields from
TARGET. Use this table for a non-optimized test. |
N/A |
| Set rows for UPDATE |
Create TMPSOURCE table, containing all fields from
TARGET. Use this table as the first phase of converting the query into an optimized UPDATE. |
4.8 |
| Set rows for UPDATE |
Insert 1M records from SOURCE into TMPSOURCE ,
with existing user_id in TARGET table. |
4,179.774 |
| Set rows for INSERT |
Create TMPISOURCE table, containing all fields from
TARGET. Use this table during first phase of converting
query to an optimized INSERT. |
5.125 |
| Set rows for INSERT |
Insert 1M records from SOURCE into TMPISOURCE,
with existing user_id in TARGET table table. |
977.238 |
| UPDATE
time |
MERGE INTO TARGET USING TMPSOURCE
(Optimized 1M UPDATES) |
1,262.036 |
| INSERT
time |
MERGE INTO TARGET USING TMPSOURCE
(Optimized 1M UPDATES) |
1,219.661 |
Let’s take a closer look at the breakdown of numbers:
Total time (Convert time + Optimized INSERT +
Optimized UPDATE)= 7,648.634ms
Non-optimized time (MERGE into target using
SOURCE table, 1M UPDATES + 1M INSERTS) = 57,134.958
Total savings (Non-optimized MERGE 57 seconds,
Optimized MERGE 7.6 seconds)= 49,486.324
Proving MERGE Optimization
To confirm that your MERGE statement is optimized, search for a semi path in the
EXPLAIN plan (search for semi). Similarly, you can confirm that a MERGE statement is
not optimized by searching for RightOuter in the EXPLAIN plan.
Confirming MERGE Optimization
Here’s how we determined whether our tests were optimized, or not. To confirm
optimization, we used the grep ‘Semi’ command to confirm that this Explain plan is
optimized:
\o | grep --color 'Semi'
EXPLAIN MERGE INTO MYSCHEMA.TARGET TGT
USING MYSCHEMA.TMPSOURCE SRC
ON SRC.user_id=TGT.user_id
WHEN MATCHED THEN
UPDATE SET user_id=SRC.user_id, user_first_name=SRC.user_first_name,
user_last_name=SRC.user_last_name,f04=SRC.f04, f05=SRC.f05, f06=SRC.f06, f07=SRC.f07,
f08=SRC.f08, f09=SRC.f09, f10=SRC.f10, f11=SRC.f11, f12=SRC.f12, f13=SRC.f13,
f14=SRC.f14, f15=SRC.f15, f16=SRC.f16, f17=SRC.f17, f18=SRC.f18, f19=SRC.f19,
f20=SRC.f20, f21=SRC.f21, f22=SRC.f22, f23=SRC.f23, f24=SRC.f24,
f25=SRC.f25, f26=SRC.f26, f27=SRC.f27
WHEN NOT MATCHED THEN
INSERT VALUES(SRC.user_id, SRC.user_first_name, SRC.user_last_name,
SRC.f04, SRC.f05, SRC.f06, SRC.f07, SRC.f08, SRC.f09, SRC.f10, SRC.f11, SRC.f12,
SRC.f13, SRC.f14, SRC.f15,SRC.f16, SRC.f17, SRC.f18, SRC.f19, SRC.f20, SRC.f21,
SRC.f22, SRC.f23, SRC.f24, SRC.f25, SRC.f26, SRC.f27);
| +---> JOIN MERGEJOIN(inputs presorted) [Semi] [Cost: 2M, Rows: 1M] (PATH ID: 1) Inner (RESEGMENT)
| +---> JOIN MERGEJOIN(inputs presorted) [Semi] [Cost: 2M, Rows: 1M] (PATH ID: 1)
| +---> JOIN MERGEJOIN(inputs presorted) [Semi] [Cost: 2M, Rows: 1M] (PATH ID: 1) Inner (RESEGMENT)
| +---> JOIN MERGEJOIN(inputs presorted) [Semi] [Cost: 2M, Rows: 1M] (PATH ID: 1)
4[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT1_DBD_1_seg_DestoUPD_b1 and subquery
(PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc: Integer(8)", color = "brown", shape = "box"];
14[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT1_DBD_1_seg_DestoUPD_b0 and subquery (PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc:
Integer(8)", color = "brown", shape = "box"];
22[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE)
using MOGOT0_PROJ_v1_b1 and subquery (PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc: Integer(8)",
color = "brown", shape = "box"];
32[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using MOGOT0_PROJ_v1_b0
and subquery (PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc: Integer(8)",
color = "brown", shape = "box"];
50[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT1_DBD_1_seg_DestoUPD_b1 and subquery (PATH ID: 1)\n[Semi]\n\nUnc:
Integer(8)\nUnc: Integer(8)", color = "brown", shape = "box"];
60[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT1_DBD_1_seg_DestoUPD_b0 and subquery (PATH ID: 1)\n[Semi]\n\nUnc:
Integer(8)\nUnc: Integer(8)", color = "brown", shape = "box"];
68[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT0_PROJ_v1_b1 and subquery (PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc:
Integer(8)", color = "brown", shape = "box"];
78[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT0_PROJ_v1_b0 and subquery (PATH ID: 1)\n[Semi]\n\nUnc: Integer(8)\nUnc: Integer(8)",
color = "brown", shape = "box"];
Search For Term RightOuter
To confirm that the MERGE statement is not optimized, we used the grep
‘RightOuter’ command to search for that term. This MERGE statement could never
be optimized because it did not comply with the optimization requirements. How? By
omitting the user_last_name=SRC.user_last_name clause from the UPDATE clause,
the number of column attributes in the INSERT and UPDATE clauses were uneven.
In addition, we did not specify all table columns in the statement.
\o | grep 'RightOuter'
EXPLAIN MERGE INTO MYSCHEMA.TARGET TGT USING MYSCHEMA.TMPSOURCE SRC
ON SRC.user_id=TGT.user_id
WHEN MATCHED THEN UPDATE SET
user_id=SRC.user_id, user_first_name=SRC.user_first_name,
f04=SRC.f04, f05=SRC.f05, f06=SRC.f06, f07=SRC.f07, f08=SRC.f08, f09=SRC.f09, f10=SRC.f10,
f11=SRC.f11, f12=SRC.f12, f13=SRC.f13, f14=SRC.f14, f15=SRC.f15, f16=SRC.f16, f17=SRC.f17,
f18=SRC.f18, f19=SRC.f19, f20=SRC.f20, f21=SRC.f21, f22=SRC.f22, f23=SRC.f23, f24=SRC.f24,
f25=SRC.f25, f26=SRC.f26, f27=SRC.f27
WHEN NOT MATCHED THEN INSERT VALUES(
SRC.user_id, SRC.user_first_name, SRC.user_last_name,
SRC.f04, SRC.f05, SRC.f06, SRC.f07, SRC.f08, SRC.f09, SRC.f10, SRC.f11, SRC.f12,
SRC.f13, SRC.f14, SRC.f15, SRC.f16, SRC.f17, SRC.f18, SRC.f19, SRC.f20, SRC.f21,
SRC.f22, SRC.f23, SRC.f24, SRC.f25, SRC.f26, SRC.f27);
| +---> JOIN MERGEJOIN(inputs presorted) [RightOuter] [Cost: 82M, Rows: 1M
(NO STATISTICS)] (PATH ID: 1)
5[label = "Join: Merge-Join: \n(MYSCHEMA.TARGET x MYSCHEMA.TMPSOURCE) using
MOGOT1_DBD_1_seg_DestoUPD_b0 and subquery (PATH ID:
1)\n[RightOuter]\n\nUnc: Integer(8)\nUnc: Varchar(64)\nUnc: Varchar(64)\nUnc: Integer(8)\nUnc […]