


If your organization deals with low latency, high concurrency applications and queries, you can benefit from having as few nodes as possible involved in each query.
For example, say you run a website that needs to simultaneously process many small queries. You could experience time lags if the information you need resides on different nodes. The time it takes your database to compile the information across the nodes may be longer than the time required if the query ran on one node!
This is where single node queries can help. Ensuring that low latency, high concurrency queries execute on only one node can lower the execution cost in relation to a multi-node plan. Furthermore, if you use the Routable Query API (formerly known as the Key Value API), you can connect directly to the node that contains the information needed for a specific query.
To be able to use single node queries, you need to design your projections and query predicate in a certain manner. In this blog, we’?ll use the following tables as a starting point. You?’ll understand why we chose the segmentation options we did in a moment.

How do I know how many nodes I’?m using?
You can use EXPLAIN to look at a query plan to determine the node or nodes used in a query’?s execution. For the following examples, we’?re using the previously-created tables loaded with sample data.
We see from the query plan that the following query executes on all nodes:
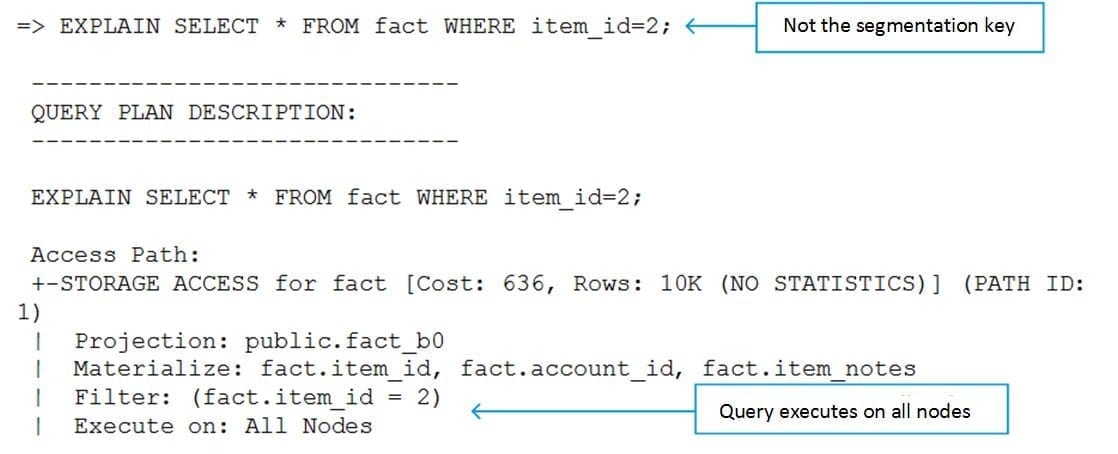
Why does my query execute on all nodes?
Well, for a query to be a single node query, it needs to follow some rules. In general, for a query to be a single node query, the predicate must:
- Be on the segmentation key
- Include an equality operator
- Include a constant value
- Be compared to a value of the same data type
The reason the above query didn’?t run on one node is because it didn’?t follow all the above rules. Specifically, the predicate we specified did not use the segmentation key (account_id).
Now let’?s run a query using the segmentation key in the predicate:
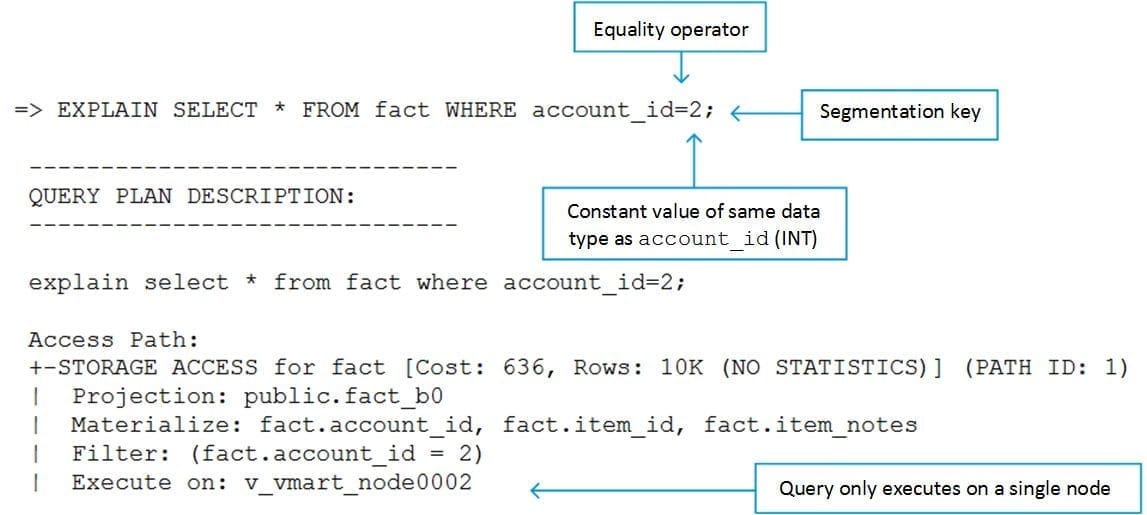
As you can see, the query executed on only one node. This is because the query meets all the requirements for a single node query.
What about other types of queries?
In addition to the basic rules for single node queries, certain types of queries have additional requirements.
Join queries
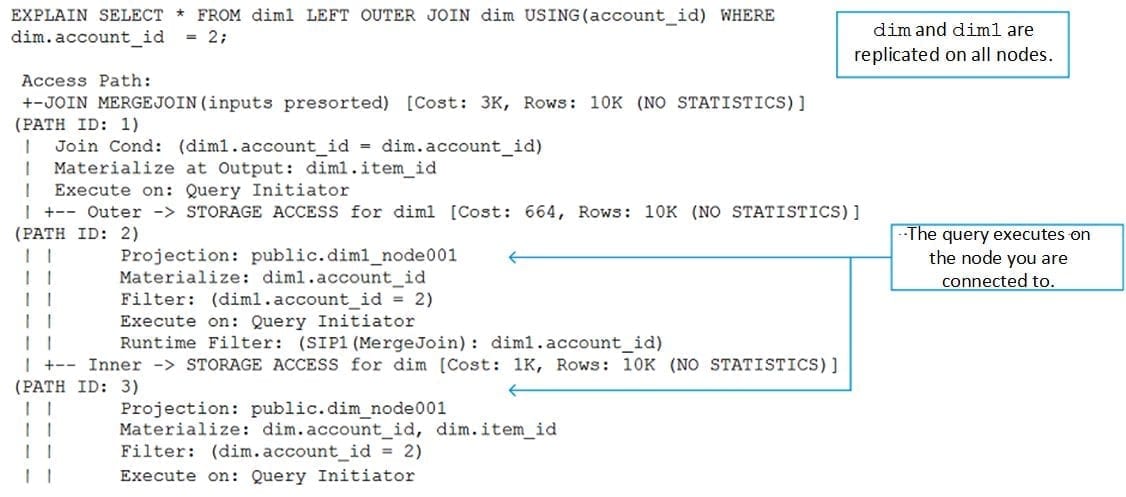
Queries with joins must follow the basic rules for single node queries along with the following: the join key must be the same as the segmentation key.
For example:

However, if one table is segmented and the other is replicated and unsegmented, all the information to answer the query is still available on one node. Therefore, the following query is also a single node query:

Likewise, the following query can execute on any single node because it is joined on two replicated tables:
GROUP BY queries
If a query contains a group by aggregation, you only need to make sure the predicate follows the original four rules for single node queries. This is because although you may be grouping by a non-segmented key, the only data you are comparing (i.e., the data from the segmentation key) is still on one node.
For example:

As you may have guessed, if you combine a GROUP BY with a join, you need to satisfy conditions for both. The query needs to meet the original conditions for a single node query (which is also the only requirement for a GROUP BY), as well as the conditions for a join.
Analytic queries
Similar to GROUP BY queries, analytic queries do not require additional rules to run as single node queries. This is again because the only data you are comparing is on the segmentation key.
For example:
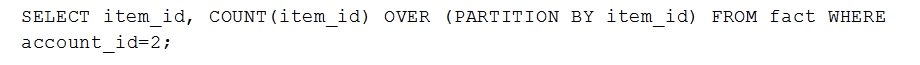
The examples shown in this blog are just a few ways you can use single node queries to help improve resource usage. When you have low latency/high concurrency queries, you should consider creating projections tailored for single node queries. On the other hand, for queries that perform heavy processing (e.g., long-running queries), evenly distributing the processing to all the nodes helps overall response time.
Fortunately, there is no limit to the number of projections you can create on a given table. You can create one projection that is optimized for shorter single node queries and others for the longer ones.
For more information about query plans, see Understanding Query Plans in the Vertica documentation.
About the Author
Sumeet Keswani



