Unleash the Power of Vertica and Apache Spark Using the Upgraded Spark Connector
Arash Fard, Senior Software Engineer at Vertica
September 16, 2022
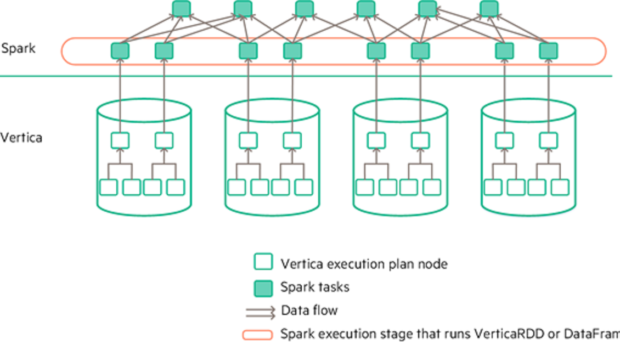
This post is authored by Alex Le What is Apache Spark? Apache Spark is a distributed compute engine that provides a robust API for data science, machine learning, or to work with big data. It is fast, scalable, simple, and supports multiple languages, including Python, SQL, Scala, Java, and R. Backed by the Apache 2.0...