


This blog post was authored by Shrirang Kamat.
Vertica in Eon Mode is a new architecture that separates compute and storage, allowing users to take advantage of cloud economics that enable rapid scaling and shrinking of clusters in response to a variable workload. Eon Mode decouples the cluster size from the data volume and lets you configure by your compute needs instead. While a Vertica cluster can host an Eon Mode database or an Enterprise Mode database, this document focuses on Eon Mode. Currently, Eon Mode works on AWS. For more information, see CloudFormation Template (CFT) Overview in the Vertica documentation.
As a Vertica administrator setting up your production cluster running in Eon Mode, you have to make important decisions about picking the correct EC2 instances and cluster size to meet your needs. This document provides guidelines and best practices for selecting instance types and cluster sizes for a Vertica database running in Eon Mode.
This document assumes that you have a basic understanding of the Eon Mode architecture and references new Eon mode concepts like communal storage, depot, and shards. Make sure you are familiar with these concepts. You can find details about Eon Mode architecture in Eon Mode Architecture.
Cluster sizing guidelines
In Enterprise Mode, sizing your cluster depends a lot on the total compressed data size. In most Vertica implementations we get a 2:1 compression or better on disk. For the number of nodes, you divide the total compressed data size by the storage capacity of each node. Vertica recommends that you put no more than 10TB of compressed data per node. Depending on the complexity of your workload and expected concurrency, you should pick instance types that have sufficient CPU and memory. For production clusters, Vertica recommends a minimum of 16 cores, 128GB RAM and a minimum of 3 nodes for high availability.
In Eon Mode, communal storage is like a data lake that can store unlimited data. A Vertica node in Eon mode must have local storage for writing depot, catalog, and temp data. Sizing for Eon Mode depends on the following factors:
• Working Data Size: The amount of data on which most of your queries will operate.
• Depot Location: To get the fastest response time for frequently executed queries, you must provision a depot large enough to hold your working data set. When loading data, Vertica must write uncommitted ROS files into the depot before uploading to communal storage. Vertica will evict files from the depot to make space for new files, if the free space in the depot is not sufficient. The amount of data concurrently loaded into Vertica cannot be larger than the sum of depot location sizes across all nodes.
• Data Location:.Data location is used for data files that belong to temporary tables and temporary data from sort operators that spill to disk. When loading data into Vertica, the sort operator may spill to disk and depending on the size of the load, Vertica may do the sort in multiple merge phases. If temporary data written to disk runs out of disk space. The amount of data concurrently loaded into Vertica cannot be larger than the sum of temp location sizes across all nodes divided by 2.
• Catalog Location. The catalog size depends on the number of database objects per shard and the number of shard subscriptions per node. Most of our large customers will have a catalog directory less than 25GB.
• Local disk sizing recommendation. Vertica recommends a minimum local storage capacity of 2TB per node, out of which 60% must be reserved for the depot and the other 40% can be shared between the catalog and data location.
• Concurrency and throughput scaling: You can pick the instance type based on the complexity of queries in your workload and the expected concurrency. In Eon Mode, you can achieve elastic throughput scaling by adding more nodes and creating a sub-cluster. To create a sub-cluster you need to define a fault group with the number of nodes equal or greater than the number of shards.
To pick an instance type and the number of nodes for the Vertica cluster running in Eon mode, you must know what your working data set is. The number of shards that you pick at database creation determines the maximum number of compute nodes that will execute your query in parallel. The number of shards cannot be changed in a Vertica database running in Eon Mode. Vertica recommends that you select your shard count based on the following table.
The following are recommended instance types based on the working data size:

Complex analytic queries will perform better on clusters with more nodes, which means 6 nodes with 6 shards performs better than 3 nodes and 6 shards. Dashboard type queries operating on smaller data sets may not see much difference between 3 nodes with 6 shards and six nodes with six shards.
You may choose instance types that support ephemeral instance storage or EBS volumes for your depot depending on the cost factor and availability. It is not mandatory to have an EBS backed depot because in Eon Mode a copy of the data is safely stored in communal storage. We recommend either r4 or i3 instances for production clusters.
The following table has information you can use to make a decision on how to pick instances with ephemeral instance storage or EBS only storage. Check with AWS for the latest prices.
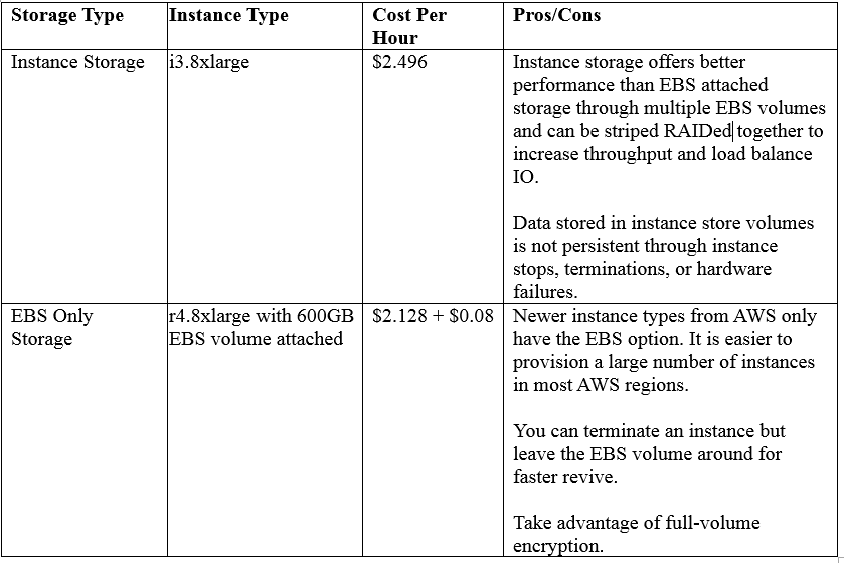
Let’s take a look at some use cases to figure out how to size an Eon Mode cluster.
Use Case 1: Save compute by provisioning close to need, rather than peak times
This example highlights the elastic throughput scaling feature of Eon Mode to scale a cluster from 6 to 18 nodes with 3 sub-clusters of 6 nodes each. In this use case, we want to support a high concurrent, short query workload on a 24TB or less working data set. We will create initial cluster with 6 nodes and 6 shards. We can scale out throughput on demand by adding one or more sub-clusters during certain days of the week or for specific date ranges when we are expecting a peak load. The cluster can then be shrunk back to its initial size by dropping nodes or sub-clusters to meet the requirements of normal workloads. With Vertica in Eon Mode, you save compute by provisioning close to the need, rather than provisioning for the peak times.
With Eon mode, it is easy and quick to add and remove nodes from the cluster as it does not require reshuffling of data via the rebalance process, as you must do in Vertica enterprise mode.
Use Case 2: Complex analytic workload requires more compute nodes
This example showcases the idea that complex analytic workloads on large working data sets will benefit from high shard count and node count. We will create an initial cluster of type large with 24 nodes and 24 shards. As needed, you can add and remove nodes to improve throughput scaling.
Use Case 3: Workload isolation
This example showcases the idea of having separate sub-clusters to isolate ETL and report workloads. We will create an initial cluster with 6 nodes and 6 shards used to service queries, and add another 6 node sub-cluster for supporting ETL workloads. You may need to configure the network load balancer from AWS to separate the ETL workload from SELECT queries. Workload isolation can also be useful for isolating different users with varying Vertica skills.
Use Case 4: Shrink your cluster to save costs
This example showcases the idea that you can shrink cluster into half during off peak hours to save cost. To shrink the cluster size, drop nodes from the cluster and Vertica will automatically re-balance the shards among the remaining nodes. When you shrink the cluster to a size smaller than the initial cluster (number of nodes = number of shards), the nodes may subscribe to more than two shards and will have the following impact:
• The catalog size will be larger because nodes are subscribing to more shards.
• The depot will be shared by more shard subscriptions, which may lead to the evictions of files.
• Each node will process more data, which may have performance impact on queries.
For more information, see Using Eon Mode in the Vertica documentation.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


