


Automatic physical database design is a challenging task. Different customers have different requirements and expectations, bounded by their resource constraints. To deal with these challenges in Vertica, we adopt a customizable approach by allowing users to tailor their designs for specific scenarios and applications. To meet different customer requirements, any physical database design tool should allow its users to trade off query performance and storage footprint for different applications.
In this blog, we present a technical overview of the Database Designer (DBD), a customizable physical design tool that primarily operates under three design policies:
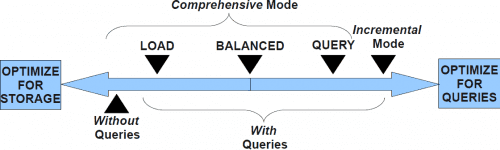
- Load-optimized—DBD proposes the minimum required set of super projections (containing all columns) that permit fast load and deliver required fault tolerance.
- Query-optimized—DBD may propose additional (possibly non-super) projections such that all workload queries are fully-optimized
- Balanced—DBD proposes projections until it reaches the point where additional projections do not bring sufficient benefits in query optimization.
These options allow users to choose to trade off query performance and storage footprint, while considering update costs. These policies indirectly control the number of projections proposed to achieve the desired balance among query performance, storage and load constraints.
In real-world environments, query workloads often evolve over time. A projection that was helpful in the past may not be relevant today and could be wasting space or slowing down loads. This space could instead be reused to create new projections that optimize current workloads. To cater to such workload changes, DBD operates in two different modes:
- Comprehensive—DBD creates an entirely new physical design that optimizes for the current workload while retaining parts of the existing design that are beneficial and dropping parts that are non-beneficial.
- Incremental—Customers can optionally create additional projections that optimize new queries without disturbing the existing physical design. Customers should use the incremental mode when workloads have not changed significantly. With no input queries, DBD optimizes purely for storage and load purposes.
The key challenges involved in the projection design are picking appropriate column sets, sort orders, cluster data distributions and column encodings that optimize query performance while reducing space overhead and allowing faster recovery. The DBD proceeds in two major sequential phases. During the query optimization phase, DBD chooses projection columns, sort orders, and cluster distributions (segmentation) that optimize query performance. DBD enumerates candidate projections after extracting interesting column subsets by analyzing query workload for predicate, join, group-by, order-by and aggregate columns. Run length encoding (RLE) is given special preference for columns appearing early in the sort order, because it is beneficial for both query performance and storage optimization. DBD then invokes the query optimizer for each workload query and presents a choice of the candidate projections. The query optimizer evaluates the query plans for all candidate projections, progressively narrowing the set of candidates until a stopping condition (based on the design policy) is reached. Query and table filters are applied during this process to filter one or more queries that are sufficiently optimized by chosen projections or tables that have reached a target number of projections set by the design policy. DBD’s direct use of the optimizer’s cost and benefit model guarantees that it remains synchronized as the optimizer evolves over time.
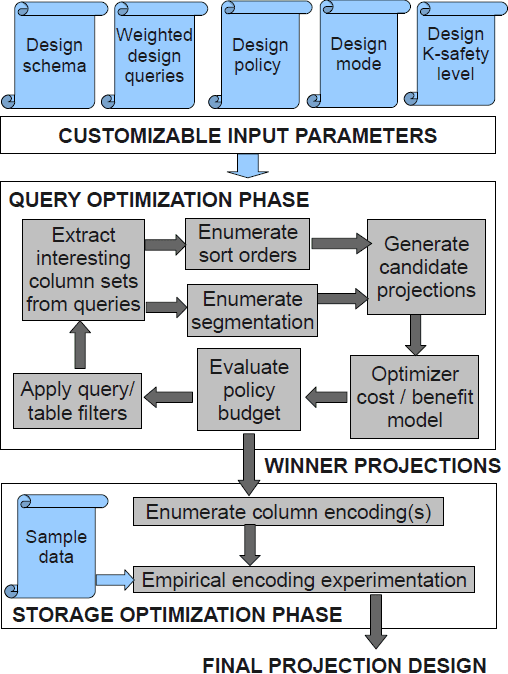
During the storage optimization phase, DBD finds the best non-RLE column encoding schemes that achieve the smallest storage footprint for the designed projections via a series of empirical encoding experiments on the sample data. In addition, DBD creates the required number of buddy projections containing the same data but distributed differently across the cluster, enabling the design to be tolerant to node-down scenarios. When a node is down, buddy projections are employed to source the missing data in the down nodes. In Vertica, identical buddy projections (with same sort orders and column encodings) enable faster recovery by facilitating direct copy of their physical storage structures and DBD automatically produces such designs.
When DBD is invoked with an input set of workload queries, the queries are parsed and useful query meta-data is extracted (e.g., the predicate, group-by, order-by, aggregate and join query columns). Design proceeds in iterations. In each iteration, one new projection is proposed for each table under design. Once an iteration is done, queries that have been optimized by the newly proposed projections are removed, and the remaining queries serve as input to the next iteration. If a design table has reached its targeted number of projections (decided by the design policy), it is not considered in future iterations to ensure that no more projections are proposed for it. This process is repeated until there are no more design tables or design queries are available to propose projections for.
To form the complete search space for enumerating projections, we identify the following design features in a projection definition:
- Feature 1: Sort order
- Feature 2: Segmentation
- Feature 3: Column encoding schemes
- Feature 4: Column sets (select columns)
We enumerate choices for features 1 and 2 above, and use the optimizer’s cost and benefit model to compare and evaluate them (during the query optimization phase ). Note that the choices made for features 3 and 4 typically do not affect the query performance significantly. The winners decided by the cost and benefit model are then extended to full projections by filling out the choices for features 3 and 4, which have a large impact on load performance and storage (during the storage optimization phase).
In summary, the Vertica Database Designer is a customizable physical database design tool that works with a set of configurable input parameters that allow users to trade off query performance, storage footprint, fault tolerance and recovery time to meet their requirements and optionally override design features.
About the Author
ramakrishna



