


The documentation states that Vertica organizes data into partitions, with one partition per ROS container on each node. Partitions are defined at the table level and apply to all projections. Partitioning usually needs to be set at create time. How do partitions affect overall Vertica operations? Let’s go to a large (6.3B rows) snapshot of my Flight Data Tracker dataset and create two tables, one without partitions and one with partitions. The definitions differ only in the partition clause:
CREATE TABLE blog.flightdata (…);CREATE TABLE blog.flightdata_partition (…) PARTITION BY (date(generated));Without partitions, Vertica will aggregate all data into a single ROS container, while with partitions, Vertica will store data with one key (here, one calendar day) per ROS container:
blog.flightdata: ROS[Day1 Day2 Day3 … DayX]blog.flightdata_partition: ROS1[Day1] ROS2[Day2] ROS3[Day3] … ROSX[DayX]One of the keys to performance in Vertica is to reduce the amount of disk I/O, since this is often the bottleneck when handling many gigabytes to terabytes of data. Dividing the ROS containers means Vertica has to access fewer bytes in smaller ROS containers, and thus less disk I/O, with partitions. This can help speed up queries when the partition key is a common search term (used in JOIN, WHERE, etc.) through predicate pushdown, where Vertica only scans the ROS containers with matching keys, for example a query filtered by date runs faster with partitions:
dbadmin=> select date(generated), count(distinct hex_ident) from blog.flightdata where generated > (current_timestamp - interval '10 days') group by date(generated);In the first case, Vertica needed to scan the entire ROS container – all 6.3B rows of data! In the second case, Vertica needed only to scan 10 smaller ROS containers corresponding to the last 10 days and completed noticeably faster.
Time: First fetch (8 rows): 138503.903 ms. All rows formatted: 138504.011 ms
dbadmin=> select date(generated), count(distinct hex_ident) from blog.flightdata_partition where generated > (current_timestamp - interval '10 days') group by date(generated);
Time: First fetch (8 rows): 57996.228 ms. All rows formatted: 57996.313 ms
To help visualize that difference, here’s a basic diagram of how partitions work in Vertica:
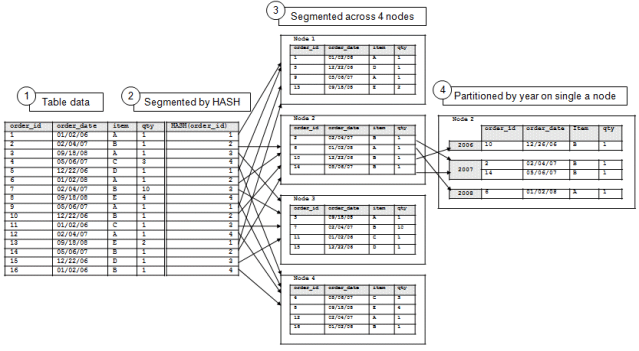
The fastest way to delete data in Vertica is to partition the data and then delete an entire partition, since this deletes the entire corresponding ROS container from disk and is very fast. However, there are frequent cases where it’s necessary to delete, update, merge data in an existing data set (such as restatement of sales figures). These are inefficient operations in Vertica because data are compressed in columnar format, which means Vertica must load the ROS container, unpack the column data, edit, then repack the column and ROS container and write back to disk. This can be done much more efficiently in memory, so we want to minimize the amount of I/O needed to move the ROS data to and from memory. Since we’re often not editing the entire data set, partitioning can greatly reduce the number of ROS containers that are touched during an update and speed up the overall operation. As an example, let’s assume we need to update some identifiers over the past 30 days in the sample data set:
dbadmin=> update blog.flightdata set hex_ident = 'AACCEE' where hex_ident in ('A19DFF','ADF128','A19A48','A2033A','AD5329','A1B449','AD846F','A21F94','A3619C','A29611','A186AD','AC7B1B','A1ACDB') and generated > (current_timestamp - interval '30 days');Not only does the update complete faster, but delete and purge operations also complete faster (the update above generates delete vectors that should be removed for best performance):
Time: First fetch (1 row): 457649.227 ms. All rows formatted: 457649.310 ms
dbadmin=> update blog.flightdata_partition set hex_ident = 'AACCEE' where hex_ident in ('A19DFF','ADF128','A19A48','A2033A','AD5329','A1B449','AD846F','A21F94','A3619C','A29611','A186AD','AC7B1B','A1ACDB') and generated > (current_timestamp - interval '30 days');
Time: First fetch (1 row): 184347.313 ms. All rows formatted: 184347.382 ms
dbadmin=> select purge_table('blog.flightdata');So partitioning is a key element of table design. If your data is organized by date, this is most likely a good partition key. Vertica can also consolidate older records into larger ROS containers with hierarchical partitions, see the further reading for details. You should also consider whether other keys are more commonly used to select data and also whether the key reduces partitions to a manageable size for your workload. If you have specific design requirements to review with us, whether partitions, projections, resource pools, and more, check in with your Vertica representative or visit the forum at https://forum.vertica.com/ and we’ll be happy to help!
purge_table
Time: First fetch (1 row): 3829571.384 ms. All rows formatted: 3829571.469 ms
dbadmin=> select purge_table('blog.flightdata_partition');
purge_table
Time: First fetch (1 row): 1248731.255 ms. All rows formatted: 1248731.344 ms
Helpful Links:
Partitioning tables:
https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/AdministratorsGuide/Partitions/PartitioningTables.htm
Creating or altering partitions:
https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/AdministratorsGuide/Partitions/DefiningPartitions.htm
Hierarchical partitions:
https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/AdministratorsGuide/Partitions/HierarchicalPartitioning.htm
Minimizing partitions:
https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/AdministratorsGuide/Partitions/MinimizingPartitions.htm
About the Author
Bryan Herger
Vertica Big Data Solution Architect at Micro Focus
My background is analytical chemistry and current interests and work are in finance, adtech, health information, and real-time streaming analytics.


