


Last week, the VerticaPy team released a new version. This version will include many new features which will help any organization get the most out of Vertica in terms of analytics. The v0.5.0 version focused on hyperparameter tuning, time series analysis and model explainability. When doing machine learning at scale, any data scientist wants to be able to automate as many tasks as possible.
The first one is hyperparameter tuning. By testing many combinations of parameters, Grid Search and Randomized Search automate the process.
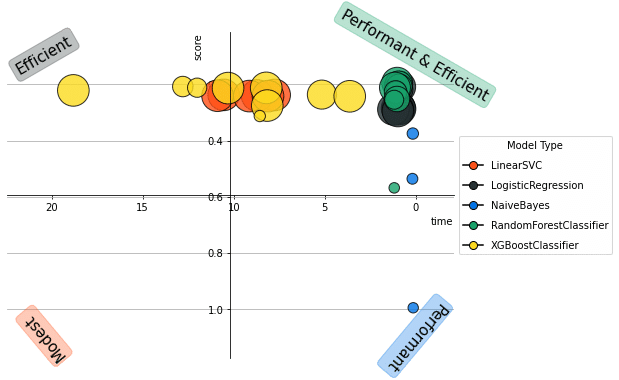
VerticaPy’s first version of AutoML makes it even easier to understand which algorithm should be used to create the final model. The following graphic shows the result of the VerticaPy AutoML algorithm. The size of the bubble is the standard deviation error of the model score. A small bubble at the top right of the graphic illustrates a performant & efficient model compared to the others. We can clearly see that, for this example, Random Forest outperforms the other models.
You can then focus on more important tasks, like Model Explainability. Most of the time, everyone prefers a simple model. When it is easy to understand, it is easier to take action. Linear Regressions with penalty (also called ElasticNet) are very often used due to their simplicity. By using Statistical tests to provide information like Multicollinearity, Endogeneity & Heteroskedasticity, it is easy to keep a stable Linear Model. VerticaPy allows in-database statistical tests to validate hypotheses.
But what if we deal with Time Series(TS)? The process will be totally different.
Being rigorous on TS analysis helps make an efficient and stable model. Many statistical tools are available for TS analysis in VerticaPy. It is easy to decompose TS into 3 parts: Seasonality, Trend and Noise. We can then use TS models to predict the noise which verifies the stationarity hypothesis.
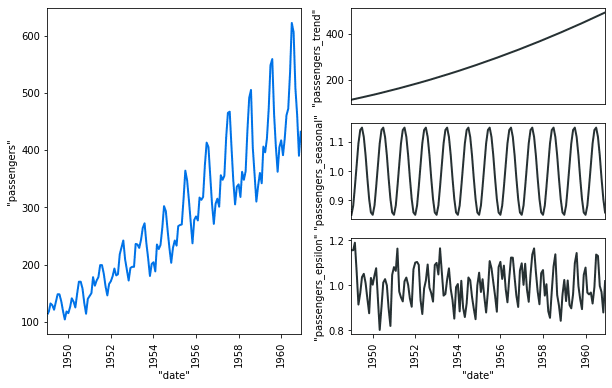
VerticaPy tries to provide everything a data scientist needs to have a real conversation with the data at scale…
Github: https://github.com/vertica/VerticaPy
What’s new: https://www.vertica.com/python/documentation_last/whats-new.php
Chart Gallery: https://www.vertica.com/python/gallery/index.php
About the Author
Badr Ouali
Head of Data Science



