Every company I’ve ever encountered needs business intelligence (BI). Increasingly, in multiple industries, more and more also need machine learning (ML) or artificial intelligence (AI) to stay competitive or gain an edge. Eventually, it should be as easy for an organization to put an ML model to work as it is to put a new graph in a BI report. But right now, a lot of companies are stuck. ML projects are either failing at the point in the workflow between proof of concept and production, or just having a long delay of months, or a year even, at that same point. Solving that is all about the data architecture design.
Part of my job at Vertica for the past few years was to host webinars with data architects, CDAOs, data engineers, and such from companies in various industries, to talk with them about their data architectures, how they worked, why they built it that way, and what they got out of it. Combine that with a previous twenty years or so as a data engineer, software trainer, technical writer, data integration consultant, technology evangelist, and product manager for various high scale data pipeline software systems, and I’ve gotten a remarkably broad view of how organizations work with data.
Over the past few years, I’ve been travelling, sometimes in person, sometimes virtually, across the globe to various AI, ML, data science, and data technology conferences talking about the challenges in data architecture that I’ve seen, and the shifting trends in how people tackle those challenges. In particular, the challenge of unifying the old data architecture, built to enable BI, and the new types of architectures, built to take advantage of the ML wave.
Over the last few months, I wrote a short e-book, co-authored with a smart young engineer named Ben Epstein who is now Founding Software Engineer of a small startup called Galileo. Ben’s history is with Splice Machines, so he’s got a solid handle on MLOps, what it takes to get machine learning projects into production. And he’s a great writer on top of that.
We pooled knowledge to create a new O’Reilly report called: Accelerate Machine Learning with a Unified Analytics Architecture – Deploy Machine Learning Models in Minutes, Not Months.
I’m proud to announce that it’s now available. It’s a free download here, and also available on the O’Reilly website.
One of the big ideas is the unification or convergence over time of the data warehouse and data lake architectures into something new that combines the power of both, while compensating for the historical weaknesses of each. This new architecture has a lot of names. Unified Analytics Architecture is the one I prefer, but Data Lakehouse is probably the most popular and well known. I’ve also seen SQL Lakehouse, Unified Data Analytics Platform (UDAP), Unified Analytics Warehouse (UAW), etc.
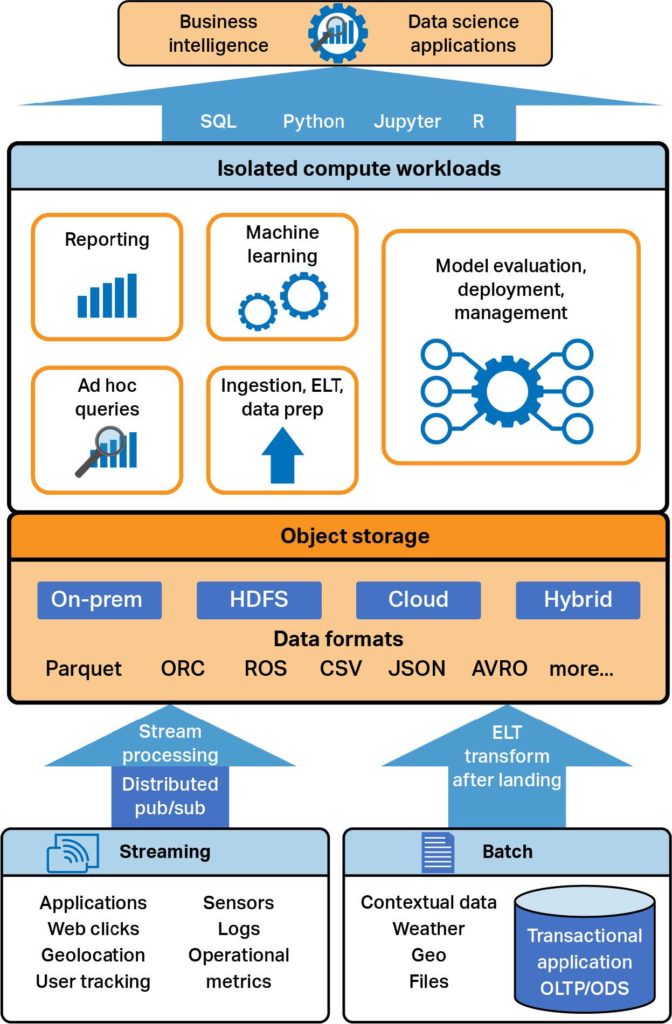
Regardless of what you call it, the data lake and the data warehouse are becoming less and less distinct architectures, and more and more merged over time. Traditional data lakes are adding capabilities like SQL query, ACID compliance, and structured data storage. Traditional data warehouses are adding capabilities like distributed scale, semi-structured and streaming support, and Python clients.
There are a lot of good reasons for this convergence of functionality. I’ve talked with Moneysupermarket.com in the UK and EOITEK in China, Taboola in Israel, and Catch Media and Uber in California. It doesn’t matter if you’re Domo, providing analytics as a service on the Cloud, or you’re Lumenore, putting natural language processing to work to make augmented analytics interfaces, you need both BI and ML to make your company hum.
Just because you’re doing something new and cool and cutting edge with ML or AI doesn’t mean you can forget all the lessons you learned from doing BI for decades.
Smart companies are merging old and new data architectures to create something that is the best of both. Read the book to get a better idea of what companies are doing, how it works, and why doing it right can make the difference between ML project failure, and a smooth ML pipeline from POC to production.
Related Post:
Let Business Intelligence and Data Science Coexist!
About the Author
Paige Roberts
Vertica Open Source Relations Manager
In over two decades in the data management industry, I have worked as an engineer, a trainer, a marketer, a product manager, and a consultant. Contributor to O'Reilly's 97 Things Every Data Engineer Should Know. Now, I promote understanding of Vertica, MPP data processing, open source, high scale data engineering, and how the analytics revolution is changing the world.