


As of Vertica 8.1, Vertica has introduced a set of popular machine learning algorithms, including Linear Regression, Logistic Regression, Kmeans, Naïve Bayes, and SVM. Based on our recent benchmarks, they run faster than MLlib on Apache Spark. The following chart shows the performance difference between Vertica 8.1.0 and Spark 2.1.0 (numbers marked on axes are in log scale).
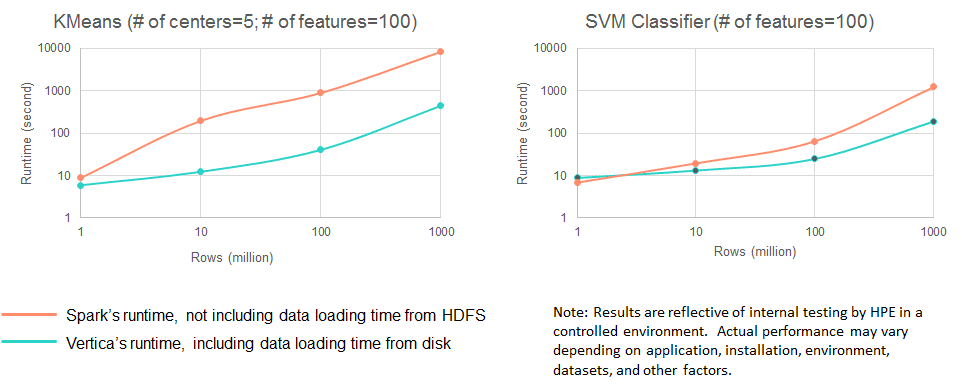
Vertica machine learning is scalable along sample size, the number of features, and cluster size. Best of all, no down-sampling is required. The size of the data that Vertica machine learning can process is only limited to the size of the data that Vertica can store. Such an accomplishment doesn’t come by coincidence. We have gone through many iterations to design a balanced architecture that leverages both Vertica’s powerful SQL engine and its state-of-the-art distributed computing framework.
The value of integrating machine learning capabilities into an RDBMS has long been recognized. Running machine learning algorithms in the database, where the data lives, minimizes data movement and greatly simplifies the machine learning workflow. Most RDBMS vendors have tried different approaches to incorporate machine learning. Traditional database vendors have developed machine learning functions in their centralized systems. MADlib attempts to run machine learning on top of a SQL engine. However, these efforts have been met with similar challenges in scalability. Lately, in-memory distributed systems have become popular platforms for big-data analytics, including machine learning. These platforms, such as Apache Spark, are served as only computing engines, while persistent data storage is provided through integration with other systems like Hadoop.
Vertica’s goal is to provide both: a scalable database that also supports scalable machine learning. The design of Vertica machine learning leverages Vertica’s distributed platform, adopts in-memory processing, and coexists with the SQL engine gracefully. The following post describes the key technologies of the design.
Master/Worker Framework
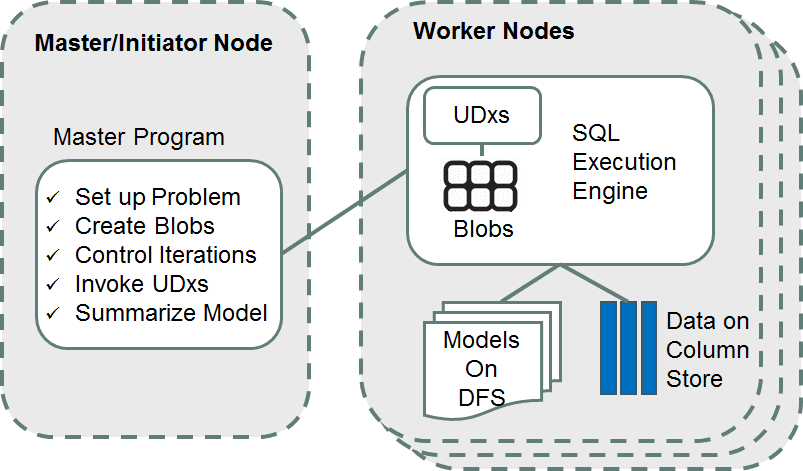
As illustrated in the following diagram, Vertica machine learning leverages Vertica’s distributed infrastructure and adopts the master/worker framework. The master program, which is able to run on any node, controls the high-level workflow of the algorithm. It sets up the problem and instructs each worker to conduct iterations of learning based on local data using Vertica’s User-Defined Functions (UDxs) . When the master determines that the algorithm has converged, it consolidates all the learning from each node and output the model.Data in Vertica is distributed, and machine learning algorithms take advantage of the distribution and conduct heavy computation on node-local data to minimize cross-node data movement.
In-Memory Processing
Vertica is built with an MPP architecture. Its execution engine is highly scalable for a one-pass algorithms like SQL queries. However, machine learning algorithms tend to be iterative, which means we know a priori that we can take advantage of caching to prevent repeated reads from disk. For that reason, Vertica has introduced memory blobs, which cache training data in the format most appropriate for an algorithm. The memory blobs are also used to store intermediate data that needs to be passed from iteration to iteration. The user can control how much memory is reserved for the memory blobs through the resource manager, and data that can’t fit in memory or that exceeds its resource budget automatically spills to disk. This allows machine learning queries to run even on systems with limited resources.Optimized Parallelism
Machine learning algorithms are CPU-bound most of the time. To improve the algorithms’ speed, it’s important to parallelize computation. Machine learning algorithms rely on Vertica’s built-in mechanism for deciding query parallelism to ensure that our queries are efficient without overly encroaching on the resources of other queries in the system. This way, Vertica balances resources intelligently between concurrent queries, including machine learning queries, in a multi-user environment.Distributed Model Storage
Machine learning models are stored as files replicated across the cluster in Vertica’s own distributed file system (DFS). The models are expressed in Vertica’s native format for fast access. Over time, a large number of models may be accumulated. To make it easy to manage models, models are created as native Vertica objects that support the same level of access control as tables and a familiar SQL syntax for listing, altering, and dropping them.State-of-the-art Distributed Machine Learning Algorithms
Researchers and developers are constantly improving existing distributed machine learning algorithms and developing new ones. For every algorithm that we have introduced, we’ve researched the latest advancements from the industry and tailored the implementation to Vertica’s infrastructure. Thanks to Vertica’s column store, projections, and data compression, analytics functions, such as COUNT, AVG, MIN/MAX, are extremely efficient. They have become the building blocks of many of the data preparation functions, such as normalization and missing value imputation. For some functions, like percentile and count distinct that are computationally expensive by nature, approximate versions were developed to speed them up.The design approaches mentioned above have made Vertica machine learning scalable and fast. If you haven’t tried Vertica machine learning yet, it is easy to start. Machine learning is built into Vertica by default. No installation or configuration is required. You can read more about Vertica machine learning in the Vertica documentation.
If you have any comments on this blog, or any other Vertica products, visit our website.
About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!


