Disclaimer
This document content is for informational purposes only. The content here should not be relied upon as legal advice, or to determine how GDPR applies to your organization or you. We strongly advise working with a qualified legal GDPR professional to understand how the regulation applies to you or your organization to ensure compliance. Neither OpenText nor OpenText™ Vertica™ make any warranties, express, implied, or statutory, as to the information in this document. The content here is provided “as-is.” The information here, including all opinions expressed in this document, as well as URLs and other references, may change without notice. This document does not provide any legal rights to any intellectual property contained herein and does not provide any legal rights to use any OpenText or OpenText Vertica product.Abstract
A database protection update can help customers in their organization compliance process journey. Many organizations are required to ensure their compliance with GDPR requirements that may apply to their databases’ data fields, parameters, scheduled audits, processes, schema templates and process log history. This document shows how Vertica can help customers fulfill database related GDPR requirements, by presenting best practice examples to translate demands into processes.Background
The General Data Protection Regulation (GDPR) is a regulation addressing data protection and privacy for all individuals within the European Economic Area (“EEA”). It also addresses the export of personal data outside the EU. The GDPR’s primary aim is to give control to citizens and residents over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU. GDPR affects any company, wherever in the world, that handles the personal data of EEA citizens. It became law on 25 May 2018, and as such includes UK citizens, since it precedes Brexit. The guidelines for the implementation and enforcement of the GDPR are not always clear, and the position of supervisory authorities can be different per country. One should verify the regulation process qualification from a legal perspective before hardening security means available technically.GDPR short brief (facts and numbers)
- GDPR refers to the General Data Protection Regulation
- Adopted by the EU Parliament in April 2016.
- Enforcement date: 25 May 2018 at which time those organizations in non-compliance may face 20M EUR fines, or 4% of organizations global turnover.
- It carries provisions that require businesses to protect personal data and privacy of EU citizens for transactions that occur within EU member states.
- GDPR also regulates the exportation of personal data outside the EU.
- GDPR Preparation Cost is between one to ten million dollars for 68% of US companies, according to PwC survey Another 9% expect to spend more than $10 million.
Which companies does the GDPR affect?
Companies that store or process personal information about EU citizens within EU states, even with no business presence in the EU.Specific criteria for companies required to comply:
- A presence in an EU country.
- No presence in the EU, but it processes personal data of European residents.
- More than 250 employees.
- Fewer than 250 employees, but its data-processing impacts the rights and freedoms of data subjects, is not occasional, or includes certain types of sensitive personal data.
- That effectively means almost all companies.
- 92% of U.S. companies consider GDPR a top data protection priority – According to PwC survey.
Six Data Protection Principles of GDPR
The six principles of GDPR are similar to the eight principles of the Data Protection Act.- Lawful, fair and transparent – There has to be legitimate grounds for collecting the data, and it must not have a negative effect on the person or be used in a way they would not expect.
- Limited for its purpose – Data should be collected for specified and explicit purposes.
- Adequate and necessary – It must be clear why the data is being collected and what will be done with it. Unnecessary data without any purpose should not be collected.
- Accurate – Reasonable steps must be taken to keep data up to date and to change it if it is inaccurate.
- Not kept longer than needed – Data should not be kept for longer than is needed and it must be deleted when it is no longer used or goes out of date.
- Integrity and confidentiality – Ensure appropriate security. Protection against unauthorized or unlawful processing, loss, damage, and kept safe and secure.
Special categories of personal data
Personal data- Name
- Address
- Location data
- Online behavior (cookies)
- Email address
- Photo
- Profiling and analytics data
- IP address
- Race
- Religion
- Health information
- Biometric data
- Genetic data
- Political opinions
- Trade union membership
- Sexual orientation
Vertica Technology Supports Process Based GDPR Data Protection Principles like the Integrity and Confidentiality principle.
1. Row and Column Access Policies:With Vertica, you can create Column and Row access policies. This provide the Data Protection Officer a simple operative way to restrict access to sensitive information. Access policies can be implement on any table type, columnar, external, or flex, on any column type, including joins. On a table with several billion rows, the elapsed time difference measured was about two seconds, querying data with and without the following access policy. We created a column access policy to allow different users to run the same query and each received different results according to their role permissions. The following access policy example authorize access to a column of Social Security Numbers.
CREATE ACCESS POLICY ON customers_table
FOR COLUMN SSN
CASE
WHEN ENABLED_ROLE(''manager'') THEN SSN
ELSE HASH(SSN)
END
ENABLE;
Only users with a “manager” role can access SSN values, while others can only view a hashed value and not the SSN number itself.2. Virtual Encryption option:
Creating persist DB views across all sessions enables us to use masking as a Virtual Encryption option. Vertica acts here as if the required data subject fields’ values are encrypted. Querying the View with the right permissions will return a masked result set (garbage). The saved fields” metadata will include graded classification scores:
A. Insensitive field – No security actions required. B. Low sensitive field – Logical encryption enforcement. C. High sensitive field – Use tokens or UDx Encryption and physical encryption enforcement.All major disk drive manufacturers support self-encrypting drives (SEDs). With SEDs, encryption techniques built into the drive controller, which ensures data written to physical drive media is in encrypted format. Moving encryption/decryption workload from CPU level to the controller or other h/w is efficient and valid; however, this alone does not answer all GDPR requirement scenarios.
3. The right to be forgotten:
3.a. Logical Process notion:
“The right to be forgotten” GDPR requirement can be implemented as a logical process notion. The concept here is to delete only the individual data subject Encryption Key, whenever the RTBF enforcement activated. This saves time and resources required to find all related data subject sensitive information and delete it all. Later, occasionally a purge process will delete encrypted values with no existing encryption keys pairs (and merge ROSs) to save disk space.
3.b. Hash field for deleted or encrypted values:
Add a new Hash-Field (HF) for each high sensitive data subject field. Each HF value will include the hash value of each predefined sensitive field. This HF will function as a join key for any GBY, count, count distinct and other activities before and after deletion of any specific data subject Encryption Key occurs. Two benefits:
- HF defined as INT for efficient joins.
- Aggregations on data subject individuals who requested to be forgotten will still be possible.
Vertica design, implementation and security operations rely on hardware and/or encryption to secure corporate data. If the backup tape or hardware device is at risk, lost, or stolen, or if it is employee owned and the employee is leaving the organization, the IT administrator will remove the employee user profile to block access to the associated data. However, this does not automatically secure the data. Sensitive data behind hardware or software encryption is still vulnerable if one has the right static password and encryption key(s) when the hardware device, data on the cloud or tape is jailbroken or rooted. A more comprehensive data security option is to verify the identity of users before Vertica boots with Duo”s two-factor authentication or Google Authenticator PAM module. In addition, organizations may consider a very simple option as described below. It does not provide the same level of security standard, as with the idea of asymmetric public-private key cryptosystem option but it will provide two separated keys, both essential for the Vertica database to startup. Decryption is possible only if one has the Vertica database password, the encryption key and the data. Vertica backup files can be divided into two set of files. One includes the encryption key”s table objects and the other set includes the data. Each set is kept in a separate place. One set of files is useless without the other. Backup data will be readable as long as the two sets of files restored to the same disk space target and the database password is available. As long as one set of files does not include the encrypted data and the encryption keys, the data on one location will be unreadable even if DB administrator Linux password is compromised when the hardware device is rooted.
OpenText – GDPR related products
OpenText has several product tools to assist customers to address GDPR compliance activities. To cover all products description is out of this document scope but we will mention three of the most relevant ones. OpenText control point for unstructured discovery, and OpenText SDM or Structure Data Manager for structured discovery, which create feeds for the third product: OpenText Content manager which is a text manager to manage documents in regulation perspective.For example, Inform if [..], alert if [..], delete if [..], backup, move, copy if [..], etc.

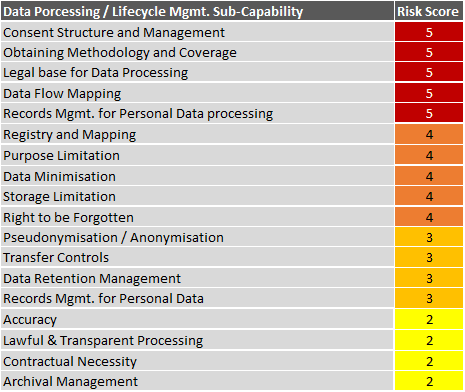
Those technologies can assist customers to create Risk score metrics and Data Life Cycle management charts.
Creating GDPR Schema items with Vertica
In general, the Data Protection Principles of GDPR can be correlated to four main requirements:- Discover – Identify personal data managed and where.
- Manage – Govern how personal data is used and accessed.
- Protect – Security controls to prevent, detect, and respond to vulnerabilities and data breaches.
- Report – Keep required documentation, manage data requests, and provide breach notifications. Vertica’s schema creation capability can facilitate fulfillment of these requirements. Vertica can address relevant subtopics by creating table templates. Some of those are trivial and may be required for future audits like the Controller_ Activities Table, and others as an analytical data layer for the GDPR processing. Consider the “Report” from the above mentioned in Art. 30 “GDPR Records of processing activities – Each controller and where applicable, the controller’s representative, shall maintain a record of processing activities under its responsibility.”
A. Controller_ Activities Table
This table may include the following fields:
| DPO_ID INT | Keeping another dimension for name and contact details of the controller or Data Protection Officer. |
| PROCESSING_ID INT | Saving processing purposes text in a different dimension. |
| DATA_SUBJECT_CATEGORY_ID INT | Description ID of the categories of data subjects and of the categories of personal data. |
| RECIPIENT_CATEGORY_ID INT | Recipient’s categories ID to whom the personal disclosed including recipients in third countries or international organizations. |
| THIRD_ORGANIZATION_ID INT | Where relevant, transfers of personal data to a third country or an international organization, including the identification of that third country or international organization. |
| TIME_LIMIT DATE | Where possible, the envisaged time limits for erasure of the different categories of data. |
| SECURITY_MEASURES_ID INT | Where possible, a description id of the technical and organizational security measures referred to in Article 32(1). |
The table”s purpose is to identify schema items like table names, columns name etc. Should one of these will include one or more of the tags in the Personal_Data_TAGs table, the higher the “personal data score value” this table and/or field will get. Above a defined score, Vertica can define the field or table as “sensitive” and as such be a candidate for audit, encryption, delete, save all unique queries this field was involved with, save data subject consent record, save process justification record, other logs, other schema items correlation reference list, etc.
Personal_Data_TAGs table example:
tag_id INT,
tag_name VARCHAR,
tag_category VARCHAR,
tag_letters VARCHAR
C. Personal_Columns TableThe table”s purpose is to record the connection (join) between each data subject and all its unique operations, by keeping a list of all data subject ids and all unique session_id for each session mentioned in dc_requests_issued or query_requests, which will be saved as a separate table reference. Vertica can help to address the “Record of Processing Activities” by managing a “Personal_Columns” table with reference for each data subject and its unique operations records. Those record references will help to answer questions like:
- Where personal data is being processed?
- Who is processing it?
- How it is being process?
This table can include the components score. This is important for the organization security and GDPR audit. The table includes static items with dynamic score and dynamic items referenced for GDPR components creation proof. The main use is to report the current state of ILM. For example, which DB objects are encrypted or the oldest Encryption key age or which data flow is done according to the security requirements. E. Automatic schema component fields
A set of columns match to each data subject fields set, to include all data like sensitive scores, hash values, encryption keys, encrypted data, consent records and other GDPR arguments.
Frequent Questions Vertica Customers Ask
Does Vertica consider itself a controller or a processor within the context of GDPR?<
Vertica is a “Processor” of data when it comes to support troubleshooting. The Vertica customer is the “Controller” of their own data.
How can the DPO notify about a data breach he does not know about?
According to GDPR Article 32 about privacy, in the event of data compromise or loss, if the organization is in full control of its own encryption keys, it can avoid the notification step altogether if the data is unreadable to the world outside the organization. If an organization chooses not to use encryption, then they would need to demonstrate what alternative mechanisms they plan to use to safeguard client personal data.
How can Vertica maintain Aggregate and Analytic Queries result set consistency when the right to erasure apply?
Vertica can address the “right to erasure” requirement by UDx extension or via a schema template. Vertica customers will retrieve a data subject id via a simple query, delete its encryption key and use its buddy-hash-field as a join key. Alternatively, you can replace its data values with hash values. When customers use Vertica pre-defined schema template, the Vertica optimizer can prefer projections with buddy-hash-fields as the join key. The following shows how you can handle records with an empty encryption key:
SELECT data_subject_id,
firstname,
lastname,
Ekey,
encrypted_ssn_ascii_value,
CASE
WHEN Ekey='''' THEN ''Forgotten''
ELSE public.AESDecrypt(ssn,Ekey)
END AS ''Decrypted SSN''
FROM t1_encrypted_values;
Addressing GDPR encryption requirements
Although GDPR mentions encryption a few times, the question if GDPR make it officially necessary to use encryption does not require a direct answer. In many organizations, this question intend to start a discussion. Even if it is not explicitly mandatory, in case of a personal data breach, personal data breach notification, or GDPR audit the encryption duty question will raise. The encryption processes itself may bring up challenges Vertica can answer:
How can I encrypt/decrypt fast enough to minimize business disturbance?
The benchmark tests below show how Vertica apportioned load generates four hundred million random encryption keys as part of a load process of 400M rows from a CSV file, at 2.3 minutes in total (0.000345 ms a record). Vertica divided the CSV file into segments (portions), and assigned it automatically to the cluster nodes as part of a fast and efficient parallel load. For more nodes, the load and the encryption keys generation will be faster. It took only 88 milliseconds to fetch and decrypt 10 specific records. Each include an encrypted INT value and two encrypted VARCHAR values from two billion records, using their matching encryption keys from a separated and secured table. To manage secured tables access permissions easier, use Vertica roles. A role is a collection of privileges that a super-user can grant to (or revoke from) one or more users or other roles. Using roles, there is no need to manually grant sets of privileges user by user. For example, many users can have access to public tables, but only few users might be assign to the GDPR Data Protection Officer role. With Vertica, the DPO can grant or revoke privileges to or from the administrator role, and all users with access to that role affected by the change.
Which encryption method can be implemented with Vertica?
Vertica data encryption options include:
- Encryption functions via Github Encryption Package: https://github.com/vertica/Vertica-Extension-Packages
- OpenText Voltage SecureData for Vertica
- Vormetric to encrypt data
- Hardware encryption. Some raid controllers have chip/hardware based encryption.
What is the INT values encryption best practice?
Preferring a simple subtract operation between a generated random number (encryption key) and the encryption target (INT value), consume fewer resources than dedicated UDx encryption function. Fetching several specific encrypted SNNs (INT values) from a 400M fact table, and decrypt those INT values (SSNs) using their matching encryption keys from separated secured table, took only 47.1 ms in total in the attached benchmark.
How can I protect off-site corporate data backups even after employees with high security classification leave?
As mentioned above, Vertica backup objects can be divide into two sets. One includes encryption keys table objects and the other set includes all other data objects. Each set is kept in a separate place, since one set of files is useless without the other. Backup data will be readable as long as the two set of files restored to the same disk space target and the database password is available. In our demo the staging table include the encryption keys and the fact table include the encryption values.
What are possible measures to prevent hacking encrypted values?
Encryption scrambles text to make it unreadable by anyone other than those users with the right role to access the table with the keys to decode it. Although sensitive data encryption becomes less of an added option and more of a must-have element in GDPR security strategy for its ability to slow down hackers from stealing sensitive information. Good encryption like AES (Advanced Encryption Standard) with 128 to 256 bit encryption, consumes high system resources. In general, hacking efforts are relative to the encryption algorithm key length, such as 128, 192 or 256 bits. It is safer to work with tokens instead of real encrypted values because the token itself does not include any data. Encryption protects data like a vault. With tokens, there is no use to break an empty vault. Consider the following example to protect the privacy of a data subject: age or SSN . If we generate a random encryption key, whose size is similar to the real data max value, no one can observe whether it is the real data or the encrypted one. A number between one and one hundred can be a good token for age, and a nine-digit number in the format of “AAA-GG-SSSS” can be a good token format for SSN. See the demo below for the use of the Vertica Randomint function with the format: “randomint(999999999)” to tokenize SSN values. Instead of saving the encrypted SSN, we keep a random number (EK) in one secured private table, and the SSN Token (ST) in public tables, where ST=EK-SSN.
How can I maintain ACID Compliance after data subjects are “forgotten”?
As mentioned, we can add to the schema a Hash-Field (HF) for each high sensitive data subject field. Each HF includes the hash value of a predefined sensitive field. The HF can function as a join key for any GBY, count, count distinct and other activities before and after deletion of any specific data subject Encryption Key occurs. This method will ensure faster joins and aggregations on deleted data subject individuals will be still possible.
Vertica GDPR Demo
In general, Vertica tools and features help to ensure system security, and prevent unauthorized users from accessing sensitive information, which can help one to enable a GDPR ready environment. Vertica provides client authentication, TLS/SSL Server authentication, LDAP link service, secure connector framework service, complies with FIPS 140-2 (Federal Information Processing Standard), database auditing and system tables restriction and access management system. The following demo evaluates various aspects of GDPR best practice processes to allow organizations to develop plans to increase performance and address the above questions.GDPR Demo Work Plan and Vertica benchmark Time Results
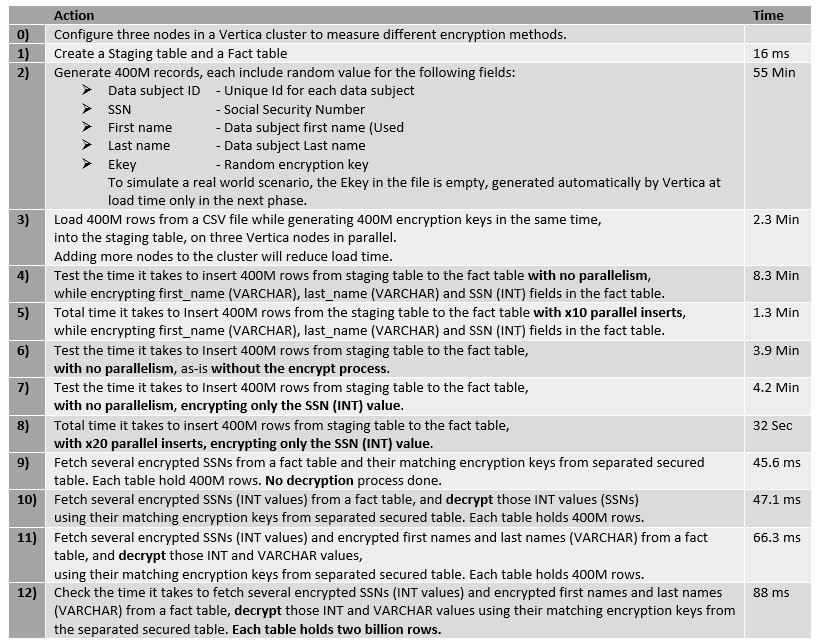 0) Vertica cluster specifics
0) Vertica cluster specifics
Total number of nodes in the cluster: 3
CPU Model: Xeon(R) CPU E5-2687W v3 @ 3.10GHz
Number of physical CPUs in one node: 2
Number of CPU cores in ONE CPU: 10
Total CPU threads in one node: 40
RAM in one node: 256GB
OS version: RHEL 7.2 (Maipo)
Vertica version: v9.0.1-8
1) Staging and Fact tables’ creation
SET SEARCH_PATH TO GDPR;
SET
Timing is on.
CREATE TABLE staging_t (
data_subject_id INT ENCODING COMMONDELTA_COMP,
ssn INT ENCODING COMMONDELTA_COMP,
firstname VARCHAR ENCODING AUTO,
lastname VARCHAR ENCODING AUTO,
ekey INT default randomint(999999999) ENCODING COMMONDELTA_COMP
)
order by data_subject_id
segmented by hash(data_subject_id) all nodes;
CREATE TABLE
Time: First fetch (0 rows): 9.117 ms. All rows formatted: 9.122 ms
CREATE TABLE fact_t (
data_subject_id INT ENCODING COMMONDELTA_COMP,
enc_ssn INT ENCODING COMMONDELTA_COMP,
enc_firstname VARCHAR ENCODING AUTO,
enc_lastname VARCHAR ENCODING AUTO
)
order by data_subject_id
segmented by hash(data_subject_id) all nodes;
CREATE TABLE
Time: First fetch (0 rows): 6.777 ms. All rows formatted: 6.781 ms
2) Generate 400M rows (script runs 40 times in parallel because there are 40 CPU threds on the node)
#!/bin/bash
PARALEL=$(cat /proc/cpuinfo | grep "processor" | wc -l) # Total CPU THREDS in one node
STARTT=$(date +"%s")
for i in $(seq 0 $(($PARALEL -1)) ) ; do
vsql -v I=$i << EOF02 &
SET SEARCH_PATH TO GDPR;
\set DEMO_ROWS 10000000 -- 10M x40 parallel runs = 400M rows
\set RUNID :I * :DEMO_ROWS
insert into sample_data
with myrows as (select row_number() over() + :RUNID as data_subject_id, uuid_generate() as firstname
from ( select 1 from ( select now() as se union all select now() + :DEMO_ROWS - 1 as se) a timeseries ts as ''1 day'' over (order by se)) b)
select data_subject_id, data_subject_id + 100000000 as snn, firstname, firstname as lastname
from myrows;
commit;
EOF02
done
wait
ENDT=$(date +"%s")
echo "DONE"
DIFF_SEC=$(($ENDT-$STARTT))
echo "Process elapsed time is $(($DIFF_SEC / 60)) minutes and $(($DIFF_SEC % 60)) seconds."
3) Load 400M rows from a CSV file into the staging table on three Vertica nodes in parallel:
COPY staging_t (data_subject_id, ssn, firstname, lastname)
FROM ''/data/mg/t1.csv'' ON ANY NODE
DELIMITER '',''
ABORT ON ERROR;
Sample of the generated data we just loaded (ekey generated automatically in the load process):
select data_subject_id,TO_CHAR(ssn,''999-99-9999'') as ssn,firstname,lastname,ekey
from gdpr.staging_t order by 1 desc limit 10;
data_subject_id | ssn | firstname | lastname | ekey
-----------------+--------------+----------------------+----------------------+-----------
400000000 | 400-00-0000 | 4dec6b7f-61af-4200-9 | da832de2-1e33-4a1a-a | 184056458
399999999 | 399-99-9999 | ff252302-08c7-4fd8-8 | afed56d6-a626-4e2b-b | 165546583
399999998 | 399-99-9998 | e1d9818f-d386-4743-8 | 79d64b43-0878-4d00-8 | 524985904
399999997 | 399-99-9997 | c795a0bd-8b95-4625-b | c460092e-d544-4b08-8 | 270943552
399999996 | 399-99-9996 | d2df85f6-9271-434a-a | 534d1fe7-6c45-4db6-9 | 434291313
399999995 | 399-99-9995 | 8b1655f3-9736-4dff-9 | e6de2432-f185-432f-b | 578153263
399999994 | 399-99-9994 | b393da00-2a07-4fed-8 | 5614dc34-52fa-489a-9 | 388401575
399999993 | 399-99-9993 | 405d6eff-96ae-47ac-9 | b088c6fc-4190-4391-9 | 231301861
399999992 | 399-99-9992 | 5ca00a90-e497-42f0-a | 135dba8e-ea17-4ac9-9 | 246945661
399999991 | 399-99-9991 | e0b18fde-a585-4baa-8 | 8bc0ebd4-70aa-4fbe-8 | 500950571
(10 rows)
4) Insert 400M rows from staging table to the fact table with no parallelism, while encrypting first_name (VARCHAR), last_name (VARCHAR) and SSN (INT) fields in the fact table.
#!/bin/bash
vsql << EOF01
SET SEARCH_PATH TO GDPR;
truncate TABLE fact_t;
\timing on
insert into fact_t (data_subject_id, enc_ssn, enc_firstname, enc_lastname)
select
data_subject_id,
ekey - ssn as enc_ssn,
public.AESEncrypt(firstname,ekey::varchar) as enc_firstname,
public.AESEncrypt(lastname,ekey::varchar) as enc_lastname
from staging_t;
commit;
EOF01
5) Insert 400M rows from staging table to the fact table with x10 parallel inserts, while encrypting first_name (VARCHAR), last_name (VARCHAR) and SSN (INT) fields in the fact table.
#!/bin/bash
vsql -e << EOF01
SET SEARCH_PATH TO GDPR;
truncate TABLE fact_t;
EOF01
echo "### Start running 10 inserts in parallel.."
PARALEL=10
FILE_ROWS=$(wc -l /data/mg/t1.csv | wc -l /data/mg/t1.csv | cut -d'' '' -f1 )
STARTT=$(date +"%s")
for i in $(seq 0 $(($PARALEL -1)) ) ; do
DELTA=$(($FILE_ROWS / $PARALEL))
FROM_DOSE=$(($i * $DELTA +1 ))
TO_DOSE=$(( ($i + 1 ) * $DELTA ))
vsql -v TO_DOSE=$TO_DOSE -v FROM_DOSE=$FROM_DOSE << EOF02 &
SET SEARCH_PATH TO GDPR;
insert into fact_t (data_subject_id, enc_ssn, enc_firstname, enc_lastname)
select
data_subject_id,
ekey - ssn as enc_ssn,
public.AESEncrypt(firstname,ekey::varchar) as enc_firstname,
public.AESEncrypt(lastname,ekey::varchar) as enc_lastname
from staging_t
where data_subject_id between :FROM_DOSE and :TO_DOSE;
commit;
EOF02
done
wait
ENDT=$(date +"%s")
DIFF_SEC=$(($ENDT-$STARTT))
echo "### Process elapsed time is $(($DIFF_SEC / 60)) minutes and $(($DIFF_SEC % 60)) seconds."
6) Time the insert of 400M rows from staging table into fact table, with no parallelism, as-is, without encryption. The purpose of these tests is to compare between parallel and not parallel INSERTS, with and without the encryption decryption time.Vertica has better and more efficient ways to merge or copy data between tables, for example optimize MERGE INTO.
#!/bin/bash
echo "### Start one insert, 400M rows with NO encryption.."
vsql -e << EOF01
SET SEARCH_PATH TO GDPR;
truncate TABLE fact_t;
\timing on
insert into fact_t (data_subject_id, enc_ssn, enc_firstname, enc_lastname)
select
data_subject_id,
ssn as enc_ssn,
firstname as enc_firstname,
lastname as enc_lastname
from staging_t;
commit;
EOF01
7) Insert 400M rows from staging table to the fact table, with no parallelism, encrypting only the SSN (INT) value.
#!/bin/bash
vsql -e << EOF01
SET SEARCH_PATH TO GDPR;
truncate TABLE fact_t;
\echo Start one insert, 400M rows, with only SSN (INT value) encryption
insert into fact_t (data_subject_id, enc_ssn, enc_firstname, enc_lastname)
select
data_subject_id,
ekey - ssn as enc_ssn,
firstname as enc_firstname,
lastname as enc_lastname
from staging_t;
commit;
EOF01
8) Time the Insert of 400M rows from staging table into the fact table, with x20 parallel inserts, encrypting only the SSN (INT) values.
#!/bin/bash
vsql -e << EOF01
SET SEARCH_PATH TO GDPR;
truncate TABLE fact_t;
EOF01
echo "### Start 20 inserts in parallel, 400M rows, encrypting only SSN (INT) values."
PARALEL=20
FILE_ROWS=$(wc -l /data/mg/t1.csv | wc -l /data/mg/t1.csv | cut -d'' '' -f1 )
STARTT=$(date +"%s")
for i in $(seq 0 $(($PARALEL -1)) ) ; do
DELTA=$(($FILE_ROWS / $PARALEL))
FROM_DOSE=$(($i * $DELTA +1 ))
TO_DOSE=$(( ($i + 1 ) * $DELTA ))
vsql -v TO_DOSE=$TO_DOSE -v FROM_DOSE=$FROM_DOSE << EOF02 &
SET SEARCH_PATH TO GDPR;
insert into fact_t (data_subject_id, enc_ssn, enc_firstname, enc_lastname)
select
data_subject_id,
ekey - ssn as enc_ssn,
firstname as enc_firstname,
lastname as enc_lastname
from staging_t
where data_subject_id between :FROM_DOSE and :TO_DOSE;
commit;
EOF02
done
wait
ENDT=$(date +"%s")
echo "### DONE"
DIFF_SEC=$(($ENDT-$STARTT))
echo "### Process elapsed time is $(($DIFF_SEC / 60)) minutes and $(($DIFF_SEC % 60)) seconds."
9) Time to fetch several encrypted SSNs (INT) and their matching encryption keys from separated secure table.
Each table holds 400M rows. No decryption done.
select f.enc_ssn as fact_enc_ssn,
s.ekey as staging_ekey
from fact_t f
join staging_t s
on f.data_subject_id=s.data_subject_id
where f.data_subject_id between 399999998 and 400000000;
fact_enc_ssn | staging_ekey
--------------+--------------
349316938 | 749316938
533806860 | 933806859
165837386 | 565837384
(3 rows)
Time: First fetch (3 rows): 45.626 ms. All rows formatted: 45.670 ms
10) Fetch several encrypted SSNs (INT values) from a fact table, and decrypt only those INT values (SSNs)
using their matching encryption keys from separated secured table. Each table holds 400M rows.
select clear_caches();
clear_caches
--------------
Cleared
\timing on
Timing is on.
select f.enc_ssn as fact_enc_ssn,
s.ekey as staging_ekey,
s.ekey – f.enc_ssn as fact_decrypted_ssn
from fact_t f
join staging_t s
on f.data_subject_id=s.data_subject_id
where f.data_subject_id between 399999998 and 400000000;
fact_enc_ssn | staging_ekey | fact_decrypted_ssn
————–+————–+——————–
349316938 | 749316938 | 400000000
165837386 | 565837384 | 399999998
533806860 | 933806859 | 399999999
(3 rows)
Time: First fetch (3 rows): 47.198 ms. All rows formatted: 47.230 ms
11) Time a query to fetch several encrypted SSNs (INT values), encrypted first names and last names (VARCHAR),
from a fact table, and decrypt those INT and VARCHAR values, using their matching encryption keys from the separated secured table. Each table holds 400M rows. The “xxxxxxxxxxxxxxxxxxxxxxxxx” represent encrypted values. The function public.AESDecrypt may return unprintable characters for encrypted values.
select clear_caches();
clear_caches
--------------
Cleared
select f.data_subject_id,
to_char(f.enc_ssn,''999-99-9999'') as encrypted_ssn,
to_char(s.ekey - f.enc_ssn,''999-99-9999'') as decrypted_ssn,
f.enc_firstname as encrypted_firstname,
public.AESDecrypt(f.enc_firstname,s.ekey::varchar) as decrypted_firstname,
f.enc_lastname as encrypted_lastname,
public.AESDecrypt(f.enc_lastname,s.ekey::varchar) as decrypted_lastname
from fact_t f
join staging_t s
on f.data_subject_id=s.data_subject_id
where f.data_subject_id > 399999990
order by 1 limit 10;
data_subject_id | encrypted_ssn | decrypted_ssn | encrypted_firstname | decrypted_firstname | encrypted_lastname | decrypted_lastname
-----------------+---------------+---------------+---------------------------+----------------------+---------------------------+---------------------
399999991 | -31-35-1082 | 399-99-9991 | xxxxxxxxxxxxxxxxxxxxxxxxx | e0b18fde-a585-4baa-8 | xxxxxxxxxxxxxxxxxxxxxxxxx | 8bc0ebd4-70aa-4fbe-8
399999992 | -53-40-4370 | 399-99-9992 | xxxxxxxxxxxxxxxxxxxxxxxxx | 5ca00a90-e497-42f0-a | xxxxxxxxxxxxxxxxxxxxxxxxx | 135dba8e-ea17-4ac9-9
399999993 | 13-14-2257 | 399-99-9993 | xxxxxxxxxxxxxxxxxxxxxxxxx | 405d6eff-96ae-47ac-9 | xxxxxxxxxxxxxxxxxxxxxxxxx | b088c6fc-4190-4391-9
399999994 | -69-04-4742 | 399-99-9994 | xxxxxxxxxxxxxxxxxxxxxxxxx | b393da00-2a07-4fed-8 | xxxxxxxxxxxxxxxxxxxxxxxxx | 5614dc34-52fa-489a-9
399999995 | 372-92-3945 | 399-99-9995 | xxxxxxxxxxxxxxxxxxxxxxxxx | 8b1655f3-9736-4dff-9 | xxxxxxxxxxxxxxxxxxxxxxxxx | e6de2432-f185-432f-b
399999996 | -267-99-9403 | 399-99-9996 | xxxxxxxxxxxxxxxxxxxxxxxxx | d2df85f6-9271-434a-a | xxxxxxxxxxxxxxxxxxxxxxxxx | 534d1fe7-6c45-4db6-9
399999997 | 317-26-0029 | 399-99-9997 | xxxxxxxxxxxxxxxxxxxxxxxxx | c460092e-d544-4b08-8 | xxxxxxxxxxxxxxxxxxxxxxxxx | c795a0bd-8b95-4625-b
399999998 | 565-83-7384 | 399-99-9998 | xxxxxxxxxxxxxxxxxxxxxxxxx | 79d64b43-0878-4d00-8 | xxxxxxxxxxxxxxxxxxxxxxxxx | e1d9818f-d386-4743-8
399999999 | 533-80-6860 | 399-99-9999 | xxxxxxxxxxxxxxxxxxxxxxxxx | ff252302-08c7-4fd8-8 | xxxxxxxxxxxxxxxxxxxxxxxxx | afed56d6-a626-4e2b-b
400000000 | 349-31-6938 | 400-00-0000 | xxxxxxxxxxxxxxxxxxxxxxxxx | 4dec6b7f-61af-4200-9 | xxxxxxxxxxxxxxxxxxxxxxxxx | da832de2-1e33-4a1a-a
(10 rows)
Time: First fetch (10 rows): 66.263 ms. All rows formatted: 66.356 ms
12) Time a query to fetch several encrypted SSNs (INT values), encrypted first names and last names (VARCHAR),
from a fact table, and decrypt those INT and VARCHAR values, using their matching encryption keys from the
separated secured table. Each table holds two billion rows.
\timing on
Timing is on.
select count(1) from gdpr.fact_t;
count
------------
2000000400
(1 row)
Time: First fetch (1 row): 49.640 ms. All rows formatted: 49.683 ms
select count(1) from gdpr.staging_t;
count
————
2000000000
(1 row)
Time: First fetch (1 row): 48.474 ms. All rows formatted: 48.506 ms
select data_subject_id,ssn as ssn,firstname,lastname,ekey
from gdpr.staging_t
where data_subject_id between 1999999991 and 2000000000
order by 1 ;
data_subject_id | ssn | firstname | lastname | ekey
—————–+————+———————-+———————-+———–
1999999991 | 1999999991 | e0b18fde-a585-4baa-8 | 8bc0ebd4-70aa-4fbe-8 | 570795423
1999999992 | 1999999992 | 5ca00a90-e497-42f0-a | 135dba8e-ea17-4ac9-9 | 296199753
1999999993 | 1999999993 | 405d6eff-96ae-47ac-9 | b088c6fc-4190-4391-9 | 448945941
1999999994 | 1999999994 | b393da00-2a07-4fed-8 | 5614dc34-52fa-489a-9 | 557511975
1999999995 | 1999999995 | 8b1655f3-9736-4dff-9 | e6de2432-f185-432f-b | 650631512
1999999996 | 1999999996 | d2df85f6-9271-434a-a | 534d1fe7-6c45-4db6-9 | 659785456
1999999997 | 1999999997 | c795a0bd-8b95-4625-b | c460092e-d544-4b08-8 | 324817229
1999999998 | 1999999998 | e1d9818f-d386-4743-8 | 79d64b43-0878-4d00-8 | 24106768
1999999999 | 1999999999 | ff252302-08c7-4fd8-8 | afed56d6-a626-4e2b-b | 229172828
2000000000 | 2000000000 | 4dec6b7f-61af-4200-9 | da832de2-1e33-4a1a-a | 313472461
(10 rows)
Time: First fetch (10 rows): 37.098 ms. All rows formatted: 37.182 ms
select f.data_subject_id, s.ekey – f.enc_ssn as ssn, public.AESDecrypt(f.enc_firstname,s.ekey::varchar), public.AESDecrypt(f.enc_lastname,s.ekey::varchar)
from gdpr.fact_t f
join gdpr.staging_t s
on f.data_subject_id=s.data_subject_id
where f.data_subject_id between 1999999991 and 2000000000
order by 1 ;
data_subject_id | ssn | AESDecrypt | AESDecrypt
—————–+————+———————-+———————-
1999999991 | 1999999991 | e0b18fde-a585-4baa-8 | 8bc0ebd4-70aa-4fbe-8
1999999992 | 1999999992 | 5ca00a90-e497-42f0-a | 135dba8e-ea17-4ac9-9
1999999993 | 1999999993 | 405d6eff-96ae-47ac-9 | b088c6fc-4190-4391-9
1999999994 | 1999999994 | b393da00-2a07-4fed-8 | 5614dc34-52fa-489a-9
1999999995 | 1999999995 | 8b1655f3-9736-4dff-9 | e6de2432-f185-432f-b
1999999996 | 1999999996 | d2df85f6-9271-434a-a | 534d1fe7-6c45-4db6-9
1999999997 | 1999999997 | c795a0bd-8b95-4625-b | c460092e-d544-4b08-8
1999999998 | 1999999998 | e1d9818f-d386-4743-8 | 79d64b43-0878-4d00-8
1999999999 | 1999999999 | ff252302-08c7-4fd8-8 | afed56d6-a626-4e2b-b
2000000000 | 2000000000 | 4dec6b7f-61af-4200-9 | da832de2-1e33-4a1a-a
(10 rows)
Time: First fetch (10 rows): 88.101 ms. All rows formatted: 88.166 ms
About the Author
Moshe Goldberg
Vertica System Engineer
With more than twenty years of experience, in technical consulting, teaching, project management and IT management, today as part of the EMEA SE team I’m happy to work with Vertica as the best product, in a great company, thanks to the unique people here.