


It has been a thrilling ride. In a few short years, Hadoop has seen astronomical rise, but recently, interest in Hadoop has peaked. Analysts like Gartner and Datanami are reporting that the hype in Hadoop is waning, with some hope that use cases for Hadoop will find their place in the enterprise. So, just what happened to the Hadoop ecosystem, and what will the future hold?
The Hadoop ecosystem is a stack
The solutions in the Hadoop ecosystem show promise on their own, but to really “do” enterprise big data analytics, you need a list of features and technologies that support both descriptive and predictive analytics, mixed workloads, the capability to perform data prep and data loading, metadata management, and more. In an enterprise deployment, these are really important features. In Hadoop, you need to pull them together from the reaches of the Hadoop ecosystem and gain expertise in all of them to move big data analytics from science experiment to production. One of the biggest challenges of Hadoop has always been about the stack.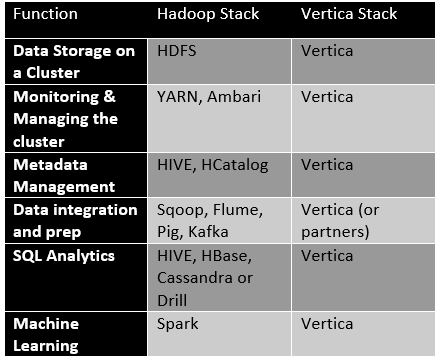
Consider that you may have to engage five or six solutions to achieve production-ready big data analytics. For example, if you want to provision your cluster and use it for multiple applications, you need HDFS and YARN skills. When you want to access data and understand the metadata, you may need HIVE, Pig and/or Sqoop, but the analysis itself is better done with Scala, Drill and/or Tez. For real-time data publishing and subscribing, bring in Kafka and experts who master it. If you want to do machine learning, you’ll need to prep the data with something like Talend and HBase, but then you must move the data out to Spark for predictive analytics. All of these operations take a special form of expertise, understanding how the solutions work, and more importantly, how they work together.
By comparison, a big data analytics platform like Vertica has features like this that work together as a package. You can deploy storage and manage resources with the management console or directly in SQL for some operations. Resource pools can be configured and tuned for workload management. You won’t have to move data out of Vertica if you want to do machine learning – it runs right within SQL database you’re already running.
External Data
If you have some data on HDFS, you can analyze it in place, or JOIN it with your Vertica database. It really takes a lot fewer solutions and much less code to handle most of the process of big data analytics. There are four key reasons why you might want to use external tables matter in your company:• Data Science – Now you can use the Vertica engine to explore data and uncover the goal without having to move the data to the database.
• JOINing External Data – You can gain additional insight by creating JOINs between your Vertica data warehouse and data that is sitting untapped in Hadoop. For example, users can leveraging Web logs to gain additional customer insight, use sensor and IOT data that is sitting externally for pre-emptive service, or track the success of marketing programs by joining data with your data warehouse.
• Training Machine Learning Models – A common practice is to move data, or subsets of data, from the data warehouse into Apache Spark to train your machine learning models. However, using Vertica’s External Tables feature and built-in machine learning capabilities, you can train your models with huge amounts of data and get more precision on your models.
• Information Lifecycle Management – After your hot data cools off, a common practice is to move your data off to lower-cost storage in support of information lifecycle management. Now, with our Parquet WRITE capabilities, you can move cooler data out of Vertica into Hadoop or the Clouds and still analyze it with Vertica using External Tables.
External tables are offered a highly discounted price per/TB, thus making it extremely attractive. The per/TB list price on a perpetual license for externally stored data is now 25% of data stored in native Vertica format. This discount applies to data stored in Parquet or ORC format when stored in Hadoop or S3.
Making the best of your Hadoop Data
Hadoop was marketed as a potential replacement for the data warehouse. Hadoop and HDFS have their place in data management and the information lifecycle, but at least today, right now, it’s not about replacing the data warehouse. The place for HDFS and Apache Hadoop is the data lake. HDFS is a power place to tier data, keep a copy of it without losing access to it for analytics.You can use your Vertica installation to leverage external tables in both Hadoop and the clouds to perform data science, boost the insight of your normal business intelligence and train your machine learning models. Further, if your Vertica data starts to age out, you can tier it off to HDFS or the cloud for cost savings and efficiency, but maintain access to it for analytics.
Limited Time Pricing
Right now you can take advantage of the time-limited Vertica External Data promotional pricing. If you need to use external tables and analyze your data in Parquet or ORC formats with Vertica, it can be very cost effective to do so! Check out https://www.vertica.com/externaldata/ for more information.About the Author
Soniya Shah
Information Developer
Currently, a first year law student with a background in science and technology. Experienced technical writer, with specializations in software documentation, big data, blog development, and website development. I build user-centered content to communicate complex and technical information more easily.
I used to work for Vertica full time for about 3 years. I still work at Vertica part time while going to law school.
Update: Soniya is now doing her law internship, and no longer working at Vertica. Good luck, Soniya!



