


white cloud in vault type room representing cloud computing
Elastic Throughput Scaling (ETS) enables Vertica to increase concurrency through which we can achieve higher throughput. ETS can take advantage of redundant shard subscriptions to automatically identify the nodes in the cluster that can execute a query.
More Nodes (N) than Shards (S): Achieving higher throughput
• S nodes can serve as Participating Subscriptions for a session
• Vertica can concurrently run ~(Nodes/Shards) queries
Rebalance_shards() to provide Participating Subscriptions for a session. It rebalances shard assignments across a cluster in Eon Mode. When Vertica rebalances shards, it automatically takes into account K-Safety and fault groups. Some of the core functionalities of Rebalance_shards are:
• Rebalance subscriptions across the nodes
• Only UP nodes with ACTIVE subscriptions are picked
• Uniformly distribute Node-per-Shard load
• K-safety achieved by any shard having >=K+1 subscriber nodes
• Each node also serves the Replica shard
Example: 9 nodes, 3 shards, 3 sessions (9/3=3) allowing three queries to be run concurrently.
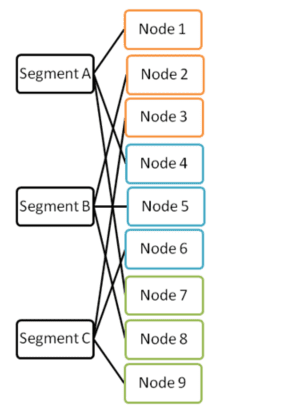
This way you can add nodes temporarily at peak demand times to process more concurrent queries.
Example – 4 Nodes 3 Shards Cluster
dbadmin=> SELECT shard_name, node_name FROM session_subscriptions WHERE is_participating;
shard_name | node_name
------------|-----------
replica | node01
replica | node02
replica | node 03
segment0001 | node01
segment0002 | node02
segment0003 | node03
Suppose node 2 goes down.
SELECT rebalance_shards();
-- Any UP nodes with ACTIVE subscriptions are picked to serve segment0002 if you run rebalance_shards().
shard_name | node_name
-------------+----------------------------
replica | node04
replica | node03
replica | node01
segment0001 | node01
segment0002 | node04
segment0003 | node03
(6 rows)
Elastic Throughput Scaling Example
dbadmin=> CREATE TABLE t (i int, j int) SEGMENTED BY hash(a) ALL NODES;
CREATE TABLE
dbadmin=> insert into t values (1,2);
OUTPUT
--------
1
(1 row)
dbadmin=> commit;
COMMIT
dbadmin=> SELECT count(*) FROM t;
count
-------
1
(1 row)
dbadmin=> SELECT DISTINCT node_name FROM dc_query_executions WHERE transaction_id = current_trans_id() AND statement_id = current_statement() - 1;
node_name
----------------------------
node01
node04
node03
(3 rows)
Or we can alter session enable PlanOutputVerbose to see which nodes are participating. Elastic Throughput Scaling: config parameters
EnableElasticThroughputScaling
1 (default): enables ETS
0: disables ETS
ElasticThroughputScalingSeed
-1 (default): random selection of Participants
0+: produces same Participant Subscriptions set based on seed value
Elastic Throughput Scaling with Subclusters
• Subclusters are Fault Groups with nodes (N) >= shards (S)
• More efficient for ETS than randomly picked Participating nodes from the cluster because it guarantees the participation of nodes only from subcluster
• Workload isolation (One subcluster for load and another for query)
• Connecting via a node in a Fault Group guarantees Participating nodes within this Fault Group
• Better cache reuse (if each Subcluster is used for similar workloads)
• Inherent fault tolerance
Assume we have a 6 Node cluster and we are trying to create two faults group having 2 nodes each.
=> CREATE FAULT GROUP a;
=> CREATE FAULT GROUP b;
=> ALTER FAULT GROUP a ADD node node01;
=> ALTER FAULT GROUP a ADD node node02;
=> ALTER FAULT GROUP b ADD node node03;
=> ALTER FAULT GROUP b ADD node node04;
Dangling nodes – node05 and node06Now, how will queries execute? – There are three strong possibilities in this case:
1) If queries are initiated from node01 or node02 then queries will only execute on fault group “a” thus you will see node01 or node02 or both in the explain plan as participating nodes.
2) If queries are initiated from node03 or node04 then queries will only execute on fault group “b” thus you will see node03 or node04 or both in explain plan as participating nodes.
3) If queries are initiated from node05 or node06 then queries will execute on ALL NODES thus ETS regardless of Subclusters will automatically identify the nodes in the cluster to execute the queries.
References:
https://www.vertica.com/docs/latest/HTML/Content/Authoring/Eon/ElasticThroughputScaling.htm
https://www.vertica.com/docs/latest/HTML/Content/Authoring/Eon/Subclusters.htm?tocpath=Vertica%20Concepts%7CEon%20Mode%20Concepts%7C_____4
About the Author
Phil Molea
Sr. Information Developer, Vertica
Phil developed technical documentation in the areas of security and diagnostics for the Vertica Analytics Platform that enabled companies to extract value from their data at the speed and scale they need to thrive in today’s economy.
(Sadly, Phil passed away recently. He will be missed.)


